
Web3 实习计划 - 2025 夏季
在这个Web3实习计划之前,其实我学过一些区块链的内容,但是也仅仅是知道一些概念性的东西,例如,PoW、PoS、defi等一些概念,所以参加这个实习计划也是为了更深入的学习Web3的内容,接下来是我的每日学习笔记
8月4日
区块链基础概念
区块链介绍
区块链是一种去中心化的分布式账本技术,用于在网络节点之间安全、透明且不可篡改地记录事务数据
- 去中心化:区块链网络通常分布在全球,每个节点都将会存储一份相同的区块链数据。没有人能够控制全部的节点,因此这份区块链数据将会一直存在。
区块链特性
- 不可篡改
你无法改变历史信息,因为每个区块包含了上一个区块的摘要并串联起来,如果你修改了历史的区块,你将必须修改后面的全部区块。所以交易一旦上链,就无法再更改
- 公开透明、匿名
在区块链上的信息全部公开透明。每个人都可以顺着区块和链找到历史上所有的记录来查看你的钱包余额。可以在区块链浏览器上进行查看
- 快速交易
无论金额多少以及你在什么地方,只要你的交易记录被打包在区块链中,交易就自动完成。相比传统的跨国汇款非常快速便捷
区块链的核心组成部分
去中心化的网络和区块链
区块链将会有一条链来记录全部的信息,这条链将存在对应的去中心化网络中。 去中心化的网络,将由无数节点提供服务来维持网络运行。节点通过计算验证交易获得代币奖励
维持网络运行的代币激励
去中心化的网络由无数节点提供服务来维持网络运行,整合区块并合并到链上的操作称为挖矿。维持这些服务的人一般称之为矿工。矿工们维持网络运行会得到代币奖励以及燃料费(Gas Fee)。 你使用这个网络进行交易、转账、铸造 NFT 等等,均需要支付代币
公链 私链 联盟链
区块链根据访问权限与治理模式,大致可分为三类。按照去中心化程度从高到低排列

公链(Public Blockchain)
- 特点:
- 完全开放:任何人可参与读写、验证交易或成为节点。
- 去中心化:无单一控制方,数据公开透明,不可篡改。
- 激励机制:通常通过代币(如比特币、以太坊)奖励矿工/验证者。
- 性能较低:因共识机制(如PoW、PoS)需全局节点验证,交易速度较慢。
- 典型应用:
- 加密货币(比特币、以太坊)。
- 去中心化应用(DApp)、DeFi、NFT等开放生态。
- 代表案例:
Bitcoin、Ethereum、Solana。
私链(Private Blockchain)
- 特点:
- 权限封闭:由单一组织或实体控制,参与者需授权。
- 中心化:节点由管理者指定,交易验证效率高。
- 隐私性强:数据仅对授权方可见,适合企业内部使用。
- 无代币激励:通常无需挖矿,节点由组织自行维护。
- 典型应用:
- 企业数据管理、内部审计、供应链追踪等。
- 对隐私和效率要求高的封闭场景。
- 代表案例:
Hyperledger Fabric(可配置为私链)、R3 Corda。
联盟链(Consortium Blockchain)
- 特点:
- 部分去中心化:由多个组织联合管理(如银行、企业联盟)。
- 准入机制:节点需许可加入,但参与者间平等协作。
- 平衡效率与信任:共识机制(如PBFT)比公链更快,兼顾一定透明度。
- 部分公开:数据可对成员共享,对外保密。
- 典型应用:
- 跨机构业务(跨境支付、贸易金融)。
- 行业协作(物流、医疗数据共享)。
- 代表案例:
Hyperledger Fabric、FISCO BCOS、Quorum。
对比总结
| 维度 | 公链 | 联盟链 | 私链 |
|---|---|---|---|
| 控制权 | 无中心主体 | 多组织共同治理 | 单一组织控制 |
| 参与权限 | 完全开放 | 需许可加入 | 严格授权 |
| 透明度 | 全网公开 | 成员间透明 | 仅内部可见 |
| 性能 | 低(TPS低,延迟高) | 中(优化共识机制) | 高(中心化处理) |
| 用例 | 加密货币、开放生态 | 跨机构协作 | 企业内部管理 |
选择依据
- 公链:适合需要完全去中心化和信任透明的场景。
- 联盟链:适合多组织协作且需平衡效率与隐私的行业。
- 私链:适合单一组织追求高效可控的私有化应用。
8月5日
| 今日学习内容 |
|---|
| 以太坊概览 |
| unphishable钓鱼攻防挑战-初级 |
以太坊概览
以太坊介绍
以太坊(Ethereum)被称为“区块链 2.0”,它不仅是一种加密货币(以太币 ETH),更是一台支持智能合约的“全球共享计算机”。通过代码自动执行规则,开发者可以在区块链上构建去中心化金融(DeFi)、数字艺术品(NFT)和去中心化自治组织(DAO)等创新应用,无需依赖银行或中心化平台。
以太坊的核心创新在于 智能合约(Smart Contracts) 。智能合约是存储在区块链上的可执行代码,能够在满足预设条件时自动执行操作,无需人工干预。这一特性使得以太坊不仅是数字货币的载体,更是构建去中心化应用(Dapps)、去中心化金融(DeFi)、非同质化代币(NFT)等生态系统的基础设施。
Ethereum 与 Bitcoin 的差异
| 维度 | 比特币(Bitcoin) | 以太坊(Ethereum) |
|---|---|---|
| 目标与定位 | 去中心化的数字货币,强调安全、稳定和稀缺性(总量 2100 万枚) | 去中心化平台,支持智能合约和 Dapps,定位为“区块链 2.0” |
| 编程能力 | 脚本语言有限,仅支持简单的交易验证逻辑 | 图灵完备的编程语言(如 Solidity),可开发复杂智能合约 |
| 共识机制 | 工作量证明(PoW),矿工通过算力竞争记账权 | 从 PoW 转向权益证明(PoS),通过 The Merge 实现能源效率优化 |
| 交易速度 | 每 10 分钟生成一个区块,交易确认较慢 | 区块时间约 12 秒,交易确认更快,适合高频应用 |
| 经济模型 | 总量固定,强调抗通胀属性 | 供应灵活,通过 EIP-1559 等机制可能呈现通缩趋势 |
以太坊的定位与演进
以太坊1.0(PoW阶段)
这个阶段就是挖矿,和比特币的机制相同,同样的消耗电力和处理交易速度慢、费用高
以太坊2.0与The Merge:从双链并行到完美合并
The Merge 完整故事:
2020 年 12 月:信标链启动
以太坊团队首先创建了一条全新的信标链(Beacon Chain),专门运行 PoS 共识机制。此时:
- 以太坊主网继续使用 PoW 挖矿
- 信标链独立运行 PoS 验证
- 两条链并行存在,互不干扰
2022 年 9 月:历史性合并
2022 年 9 月 15 日,The Merge 发生:
- 以太坊主网“关闭”了 PoW 挖矿引擎
- 将共识机制“插接”到信标链的 PoS 系统
- 从此,以太坊主网由信标链保护安全
合并后的新架构
现在的以太坊实际上是两层结构:
- 执行层:处理交易、智能合约(原主网)
- 共识层:管理验证者、确定区块顺序(信标链)
PoS机制详解:
验证者如何工作:
- 准入门槛:质押 32 ETH 成为验证者
- 工作方式:系统随机选择验证者来提议和验证区块
- 奖励机制:验证者获得新发行的 ETH + 交易费用(gas)
- 惩罚机制:作恶者质押的 ETH 被销毁(Slashing)
相比 PoW 的优势:
- **能耗降低 99.95%**:无需大量电力和硬件
- 经济安全性:攻击成本约需控制全网 67% 的质押 ETH(价值数百亿美元)
- 最终确定性:区块确认更快、更可靠
未来升级路线
暂时学不懂
以太坊生态概览:L1、L2、Sidechains 等
以太坊的生态系统由多层架构组成,包括 L1(主网)、L2(二层扩展解决方案)、侧链(Sidechains) 等,共同支持高吞吐量和低费用的交易处理。
- Layer 1(L1)
- 以太坊主网:核心区块链,负责最终安全性与共识。
- EVM:以太坊虚拟机,执行智能合约代码。
- 账户系统:外部账户(EOA)与合约账户(CA)共同构成网络基础。
- Layer 2(L2)
- Rollup:通过将交易批量处理后提交至 L1,降低 Gas 费。
- Optimistic Rollup:假设交易合法,仅在争议时验证。
- ZK Rollup:通过零知识证明验证交易,无需链上争议。
- Rollup:通过将交易批量处理后提交至 L1,降低 Gas 费。
- 侧链(Sidechains):独立运行的链,通过桥接与主网交互。
- 以太坊生态分层架构
1. Optimistic Rollup(乐观汇总)
核心思想
“默认信任,争议时验证” —— 假设所有提交到链上的交易是合法的,仅在有人提出质疑时进行验证。
工作流程
- 交易打包:
- 用户将交易发送给排序器(Sequencer),排序器批量打包交易并生成状态根(State Root),提交到主链(如以太坊)。
- 主链仅存储交易数据(Calldata),不立即验证。
- 挑战期(Fraud Proof):
- 提交后有一段挑战期(通常 7天),任何人可质疑交易有效性。
- 如果发现无效交易,验证者提交欺诈证明(Fraud Proof),触发链上计算并回滚错误状态。
- 最终确认:
- 若挑战期内无争议,交易最终确认。
优点
- 兼容性强:支持任意智能合约(EVM 兼容)。
- Gas 成本低:仅需提交数据,无需复杂计算。
- 开发门槛低:无需零知识证明(ZKP)专业知识。
缺点
- 提款延迟:用户需等待挑战期结束(7天)才能提取资金。
- 中心化风险:依赖排序器(Sequencer)快速打包交易。
- 安全依赖诚实多数:若无人监控并提交欺诈证明,恶意交易可能通过。
代表项目
- Optimism、Arbitrum(EVM 兼容,主打 DeFi 生态)。
2. ZK Rollup(零知识证明汇总)
核心思想
“数学证明,即时验证” —— 每批交易通过零知识证明(ZKP)验证有效性,无需争议期。
工作流程
- 交易打包:
- 排序器收集交易,生成状态变更和有效性证明(ZK-SNARK/STARK)。
- 将证明和状态根提交到主链。
- 链上验证:
- 主链验证 ZKP,确保交易合法后立即更新状态。
- 无需挑战期,交易即时确认。
优点
- 即时最终性:无提款延迟,资金可立即提取。
- 更高安全性:依赖数学证明,无需诚实多数假设。
- 隐私性:可选择性隐藏交易细节(如 Zcash 风格隐私交易)。
缺点
- 计算资源消耗大:生成 ZKP 需要高性能硬件。
- EVM 兼容性有限:早期仅支持简单逻辑,现逐步改进(如 zkEVM)。
- 开发复杂度高:需密码学专业知识。
代表项目
- zkSync、StarkNet、Scroll(专注 zkEVM 兼容)。
以太坊生态可以分为以下几个层次:
- 应用层(Application Layer)
用户直接交互的应用和界面:
- DeFi 应用:Uniswap(去中心化交易所)、Aave(借贷协议)、Compound(借贷协议)
- NFT 平台:OpenSea、Foundation、SuperRare
- 钱包应用:MetaMask、Coinbase Wallet、Rainbow
- DAO 工具:Snapshot、Aragon、Colony
- 协议层(Protocol Layer)
以太坊的核心基础设施:
- 共识层客户端:Prysm、Lighthouse、Nimbus、Teku
- 执行层客户端:Geth、Nethermind、Erigon、Besu
- 核心协议:EVM、状态管理、Gas 机制
- 扩展层(Scaling Layer)
提升性能和降低成本的解决方案:
- Layer 2 Rollups:Arbitrum、Optimism、Polygon zkEVM、zkSync Era
- 侧链:Polygon PoS、xDAI(Gnosis Chain)
- 状态通道:Lightning Network for Ethereum
以太坊文化与价值观
核心价值观
- 去中心化治理(Decentralization)
- 没有单一的控制者或权威机构
- 社区通过公开讨论和 EIP(以太坊改进提案)机制共同决策
- 验证者遍布全球,防止权力集中
- 无需许可与开放性(Permissionless & Open)
- 任何人都可以使用、开发、部署智能合约
- 开源代码,透明可审计
- 无身份、地域、财富限制的参与门槛
- 抗审查性(Censorship Resistance)
- 交易和智能合约不受政府或机构干预
- 通过分布式验证确保网络弹性
- 支持言论自由和经济自由
- 密码朋克精神(Cypherpunk Ethos)
- 代码即法律:用算法和数学构建信任
- 密码学保护隐私和自主权
- 技术驱动的社会变革,而非政治手段
- 公共物品导向(Public Goods Orientation)
- 优先考虑生态系统整体利益
- 支持开源项目和基础设施建设
- 通过各种资助计划推动创新
- 可持续发展理念
- The Merge 体现了对环境责任的承诺
- 长期主义思维,注重技术的可持续演进
- 平衡创新速度与网络稳定性
以太坊核心机制:从账户到执行的完整链路
以太坊三个关键机制:账户系统、Gas 模型 和 以太坊虚拟机(EVM)。
(1)账户系统:你的数字身份
账户系统 包含由私钥控制的 外部账户(EOA) 和由智能合约代码控制的 合约账户(CA) 。
想象你第一次接触以太坊——你需要一个“数字钱包”来参与网络。这个钱包的核心是 外部账户(EOA) ,它由一对密钥(私钥和公钥)生成,就像银行账户的密码和账号。私钥是你控制账户的“钥匙”,必须严格保密;公钥通过加密算法生成一个唯一的地址(如 0xAbc...123),你可以把它分享给朋友接收转账。
除了用户控制的 EOA,还有 合约账户(CA) 。它们不像 EOA 那样受私钥控制,而是由代码驱动。比如,你部署一个智能合约(如一个 NFT 市场),区块链会自动生成一个 CA 地址(如 0xDef...456)。这个账户不能主动发起交易,只能通过 EOA 触发——比如你点击“购买 NFT”按钮时,EOA 向 CA 发送交易,CA 的代码自动执行出货逻辑。
每个账户都包含四个关键字段:
- Nonce:防止重复交易的计数器(EOA 记录发送次数,CA 记录创建合约次数)。
- 余额:账户持有的 ETH 数量(单位为 Wei)。
- CodeHash:EOA 为空哈希,CA 存储合约字节码的哈希值。
- StorageRoot:记录账户数据的 Merkle 树根哈希(如 NFT 归属关系)。
(2)Gas 模型:交易的燃料费
当你用钱包使用自己的 EOA 发起一笔交易(比如转账或操作合约),这件事当然 不会是免费的,你需要支付“燃料费”——也就是 Gas。
Gas 费用 = 用多少 × 每单位多少钱,就像你打车一样:
- Gas Limit(限额):你最多愿意“烧”多少燃料。 比如你觉得最多可能需要 15 万单位,就设置 150,000。
- Gas Price(单价):每单位燃料多少钱,用 Gwei 表示(1 Gwei = 0.000000001 ETH)。 网络越拥堵,价格越贵,就像打车高峰期加价。
所以,总费用 = Gas Limit × Gas Price。
1 | 假设你设置 Gas Limit 为 150 000,Gas Price 为 100 Gwei,总费用就是 0.015 ETH。如果实际消耗 120 000 Gas,剩余 30 000 Gas × 100 Gwei = 0.003 ETH 会退还给你。 |
Gas 的存在有两个目的:
- 激励矿工/验证者:你给得越多(Gas Price 越高),他们越愿意优先处理你的交易。
- 防止资源滥用:如果有人想让合约死循环,Gas 会用光,交易失败,系统不会被拖垮。
在 EIP-1559 升级后,Gas Price 被拆分了:
以前,Gas Price 全部给矿工。 现在,分成两部分:
- 基础费用(Base Fee):每个区块都会有,自动计算,直接销毁(直接消失)来帮助 ETH 通缩,毕竟物以稀为贵。
- 小费(Tip):你额外加的钱,用来鼓励矿工优先处理你。
(3)以太坊虚拟机(EVM):代码的执行引擎
EVM(Ethereum Virtual Machine)是 以太坊的“大脑”,是专门用来运行智能合约的虚拟计算机。它运行在每个节点上,确保整个网络在处理代码时,结果都一致、可信任。
EVM 的核心特点:
- 图灵完备:就像真正的电脑一样,EVM 可以执行各种逻辑,比如 if 判断、循环等。
- 全球同步:每个矿工/节点都会自己执行一遍合约代码,保证结果一样。
- 隔离安全:EVM 把合约“关”在一个小房间里运行,不允许它乱访问用户的数据和网络,保护隐私和安全。
Unphishable钓鱼攻防挑战
挑战地址:unphishable.io
初级
No.0x0001 Web3 钱包设置指南
第一关就是创建一个MetaMask的小狐狸钱包,在这之前我就有一个钱包里。这关也重点强调了助记词的重要性。非常重要!!千万不能泄露,接下来一关我就中招了!
安全存储助记词方法附上:
- 将其写在纸上(多份副本)
- 存放在安全、防水、防火的地方
- 考虑使用金属备份解决方案以提高耐久性
- 切勿以数字方式存储(不要拍照、不要云存储、不要电子邮件)
- 切勿与任何人分享,包括”支持人员”
还有一个点就是要领取Holesky的测试币,找了几个水龙头都不是很好弄,看群里的小伙伴都是用Google水龙头领测试币,但是我的就用不了,Google的水龙头搞抽象,无法领取,问了群里大佬说他是这样的。不过最后找到一个好用的水龙头,不仅之前领了Sepolia的测试币,现在也领了Holesky的测试币,附上地址
https://www.alchemy.com/faucets/ethereum-sepolia
但是应该是需要eth主网上有一定量的以太币(0.001 ETH)才能在这里领测试币
领完测试币,连接钱包,这关就结束了
No.0x0002 钱包恢复助手
这是一个ai对话界面,功能是钱包恢复,然后让你输入你的助记词,我看到了这样的字样 “请放心,这是一个安全的环境,您的信息将被加密处理。”然后还真的去找了我的助记词给他添上了,我还特意用ai查了这个平台是否靠谱,结果输入进入,告诉我我被钓鱼了。身为一个学安全的人,我自认为安全意识还是有点的,但是也可能是我还没意识到这个挑战是在做个什么,所以被骗+1。
所以!!永远不要向任何人透露您的助记词,无论他们声称是谁
No.0x0003 USDC Permit 钓鱼模拟
这一个内容就到了我要学习的地方,之前没听过。开始学!
因为一开始还不知道所以还是点了授权,被骗+1
知识点:
通过使用 EIP-2612 的
permit签名功能,用户可以在不预先进行链上授权交易(即无需支付 Gas 费)的情况下,授权第三方合约使用自己的代币(如 USDC、DAI 等)。这是以太坊上一种更高效、更省 Gas 的授权方式,尤其适合优化用户体验(UX)和批量操作。1. EIP-2612
permit的核心机制(1)传统授权(
approve)的问题
- 需要发送一笔链上交易(支付 Gas)。
- 用户必须提前授权,导致交互流程变长。
(2)
permit的改进✅ 免 Gas 授权:用户签署一条链下消息(签名),第三方合约可凭此签名直接获得代币使用权,无需用户预先发送
approve交易。
✅ 单次有效:签名可设置过期时间(deadline),避免长期风险。
✅ 兼容 ERC-20:无需修改代币标准,只需代币合约实现permit函数。2.
permit的工作原理(1)用户签署离线消息
用户对以下数据进行签名(使用 EIP-712 结构化签名):
2
3
4
5
6
7
owner: "0x用户地址", // 代币持有者
spender: "0x合约地址", // 被授权方(如 Uniswap)
value: 1000000, // 授权数量(如 1 USDC = 1e6)
nonce: 123, // 防止重放攻击
deadline: 1698765432 // 过期时间(UNIX 时间戳)
}(2)第三方合约提交签名
合约调用代币的
permit方法,传入签名数据:
v, r, s是签名的 ECDSA 参数。- 代币合约验证签名,并更新授权状态(相当于执行了
approve)。3. 安全注意事项
✅ 优点
- 节省 Gas:用户只需签一次名,无需单独发
approve交易。- 更短交互流程:适合钱包内直接签名授权。
⚠️ 风险
- 签名钓鱼:恶意 DApp 可能诱导用户签署高额
permit(检查value和spender)。- 过期时间失效:若
deadline过长,签名可能被重复使用(建议设置较短有效期)。
我的理解就是 授权第三方合约使用自己的代币,然后可以省去gas费用
这个签名将允许攻击者控制您的 USDC 代币!通过使用 EIP-2612 permit 签名,攻击者可以:
- 获得对您所有 USDC 的完全访问权限
- 在未来任何时间转移您的代币
- 无需您进一步批准即可花费您的资金
安全检查要点
检查 Permit 类型,了解授权范围
验证 Spender 地址是否为可信来源
注意授权金额,警惕无限制授权
确认网站来源的可信度
所以此处不能进行授权
No.0x0004 专属代币空投
此交易实际上是向合约 0xbe535a82f2c3895bdaceb3ffe6b9b80ac2f832a0 发送 0.5 ETH,而不是领取任何代币。
函数选择器 0x5fba79f5 调用了一个名为 SecurityUpdate() 的函数,该函数可能会将您的资金转移给攻击者。
在真实情况下,永远不要在不了解交易内容的情况下签署交易!
No.0x0005 USDT 授权钓鱼模拟
挑战:请小心真实的授权请求
授权风险提示:
- 除了 approve 外,也要当心 increaseAllowance 函数
- increaseAllowance 同样可以增加代币授权额度
- 一些钓鱼网站会通过这个方式来掩饰其真实意图
💡 安全建议:永远不要给不明来源的网站无限授权!
increaseAllowance是 ERC-20 代币标准 中的一个扩展函数,用于安全地增加某个地址(spender)的代币授权额度。它是对传统approve方法的改进,旨在避免潜在的安全风险(如前端竞态条件攻击)。传统
approve的问题
竞态条件(Race Condition)
如果用户连续发起两笔approve交易(例如先授权 100,再改为 200),矿工可能以相反顺序打包交易,导致最终授权额度被意外覆盖(变成 100 而非 200)。solidity
2
3
approve(spender, 100); // 交易1
approve(spender, 200); // 交易2
increaseAllowance的解决方案✅ 增量调整:基于当前授权额度增加数值,而非直接覆盖。
✅ 安全操作:避免竞态条件,适合前端交互。
No.0x0006 假冒代币空投钓鱼攻击
挑战:识别真假域名
- 场景描述
某天,你收到一封电子邮件,声称你有资格获得UNI代币的空投!邮件中包含一个链接,引导你到一个看似合法的网站。你点击了该链接,并看到以下交易记录:
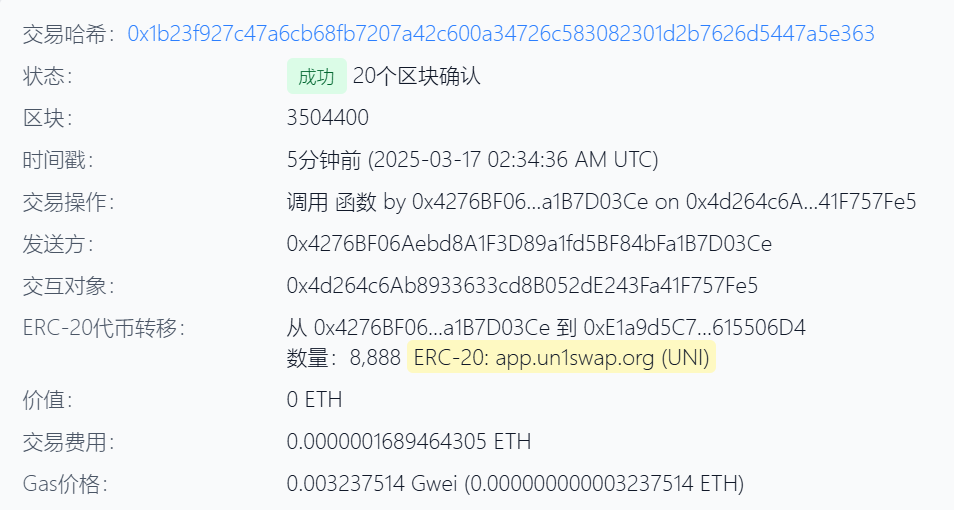
仔细观察上面的交易记录。这种钓鱼攻击通常利用视觉上相似的字符(如用数字”1”替代字母”i”)来欺骗用户。
安全建议
- 始终逐字符检查域名
- 警惕使用数字代替字母的域名(例如,用’1’代替’i’)
- 收藏官方网站而不是点击电子邮件中的链接
- 使用密码管理器,它只会在合法域名上自动填充
- 安装警告钓鱼网站的浏览器扩展
No.0x0007 超高收益质押平台
挑战:了解如何识别可疑的质押合约
某些可疑的质押合约可能会引导您进行 approve 授权,表面上看似只为了质押特定金额,实际上却请求对整个代币余额的完全访问权限。一旦授权成功,攻击者即可任意转走您的所有资产。
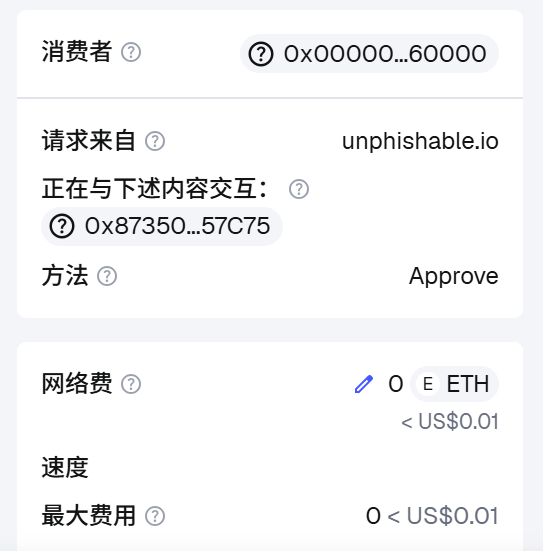
如上图,存在approve方法需要谨慎!!
approve是 ERC-20 代币标准 中的一个核心方法,用于授权另一个地址(通常是智能合约)代表你支配一定数量的代币。它是 DeFi(去中心化金融)交互的基础,但错误使用可能导致资金风险。
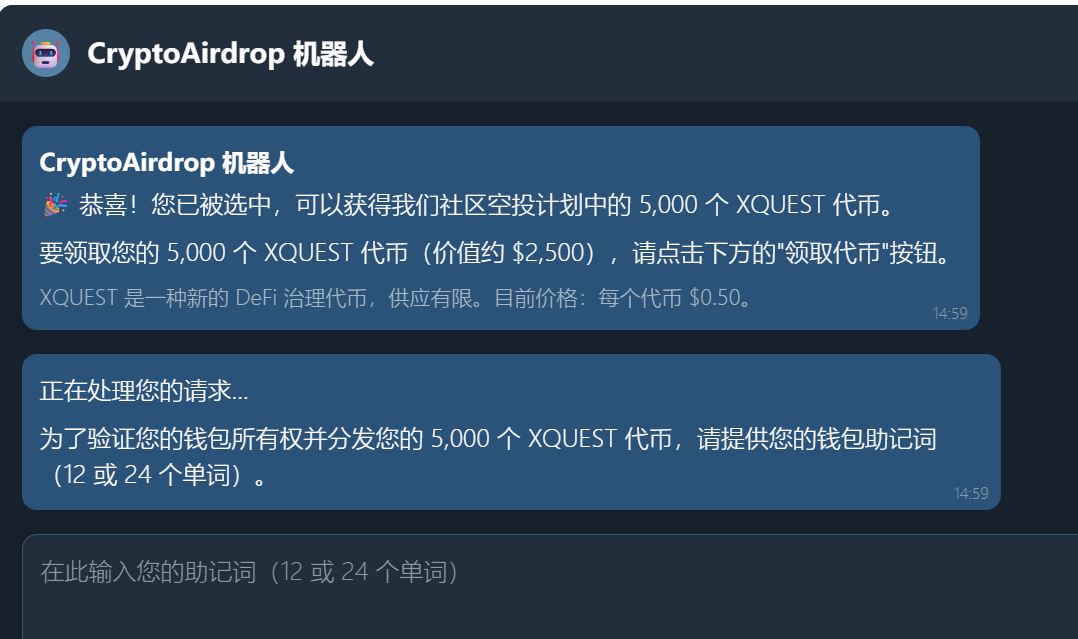
No.0x0008 Telegram 代币钓鱼挑战
挑战:学习识别和避免 Telegram 上的助记词钓鱼攻击
风险点依旧是提供助记词,所以千万不要给别人提供自己钱包的助记词!!!
No.0x0009 Punycode 钓鱼攻击
挑战:识别 Punycode 钓鱼域名
- 场景描述
您收到一封电子邮件,声称是来自 Trezor(一个知名的硬件钱包品牌)的重要安全更新通知。电子邮件中的链接看起来像是指向官方 Trezor 网站,但实际上是一个精心伪装的钓鱼网站。
1 | trẹzor.com |
什么是 Punycode?
Punycode 是一种编码系统,允许将非 ASCII 字符(如西里尔字母、中文等)转换为 ASCII 字符,以便在域名系统中使用。攻击者经常利用视觉上相似的字符创建看似合法的域名。 例如,某些特殊字符看起来与拉丁字母几乎相同,但它们是不同的字符: 你可以使用 Punycoder 来转换 Unicode 和 Punycode 域名。
显示域名 实际 Punycode 域名 说明 trẹzor.com xn–trzor-o51b.com 使用特殊字符替换了某些字母
所以 trezor的官方域名应该为trezor.io
防御方式:
- 直接在浏览器中输入已知的官方网址,而不是点击电子邮件中的链接
- 使用书签保存常用的重要网站
- 安装可以检测 Punycode 域名的浏览器扩展
- 注意域名中不寻常的字符或拼写
No.0x0010 剪贴板钓鱼挑战
挑战:识别剪贴板型钓鱼攻击
- 场景描述
您需要转账 1 ETH 到朋友的钱包。他们已经分享了他们的钱包地址,您正在使用加密货币转账界面进行转账。
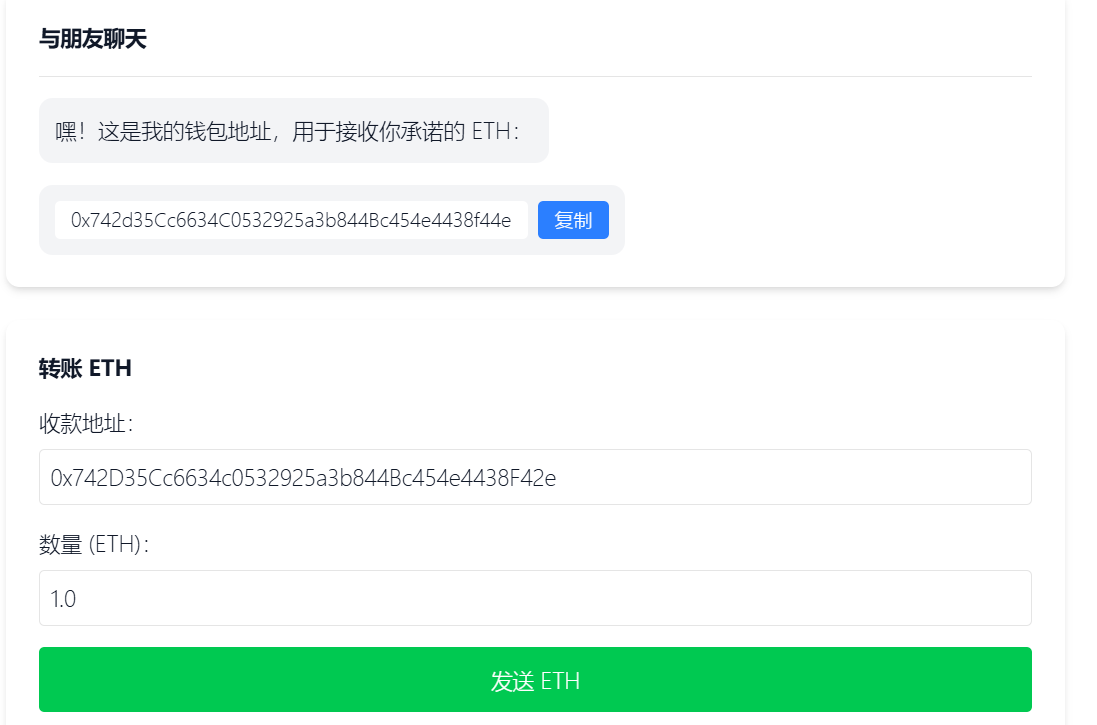
复制粘贴之后,发现钱包地址与之前的不同了
- 攻击原理:
- 攻击者创建一个看似合法的网站
- 当你点击”复制”按钮时,恶意JavaScript代码会秘密替换复制的地址
- 如果粘贴后没有验证地址,你可能会将资金发送给攻击者
防御方式:
粘贴后务必再次检查地址
考虑使用带有地址验证的硬件钱包
在电脑上复制敏感信息(如钱包地址)时要特别小心 - 即使使用Ctrl+C,恶意软件也可能篡改你的剪贴板内容
No.0x0011 Google 搜索广告钓鱼攻击
挑战:识别 Google 搜索广告钓鱼
- 场景描述
您想要使用 Lido Finance 质押 ETH。在 Google 上搜索”Lido Finance”时看到这些结果。您能识别出哪个是合法网站,哪个是钓鱼网站吗?
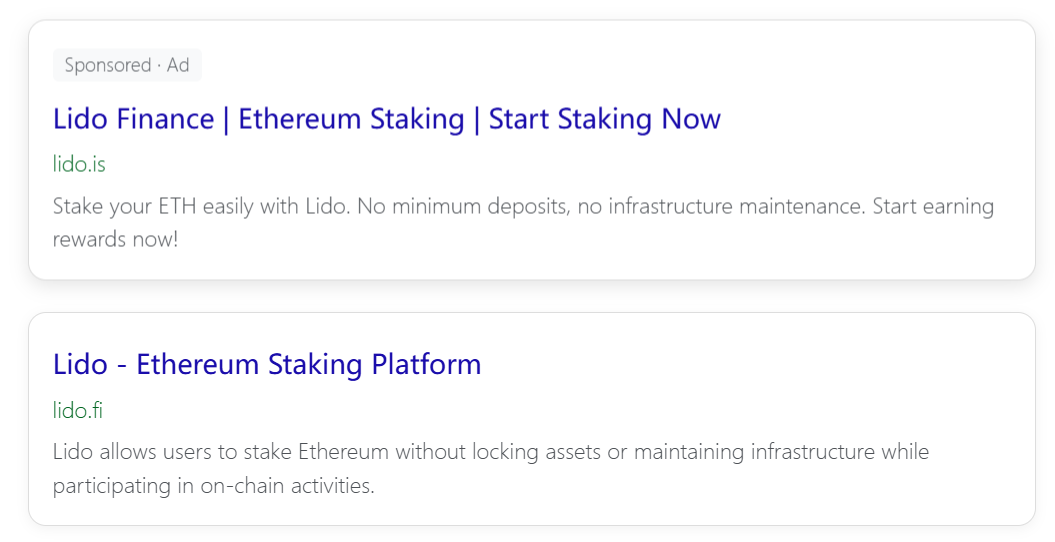
看第一条的左上角有一个Ad,是广告的意思,怀疑是钓鱼网站
辨别网站真伪的方法:
- 攻击者经常购买与热门加密货币项目相关的 Google 广告,这些广告会出现在搜索结果的顶部,标记为”赞助”或”广告”。
- 这些广告通常使用与官方网站非常相似的域名,但有细微的差别,例如:
- 使用不同的顶级域名(如用 .is 代替 .fi)
- 在域名中添加或删除字母
- 使用连字符或用数字替换字母
- 当用户点击这些广告时,他们会被引导到看起来与官方网站完全相同的钓鱼网站,这些网站旨在窃取资金或私钥。
No.0x0012 Microsoft Teams 钓鱼攻击
本页面模拟攻击者如何创建虚假的 Microsoft Teams 网站来分发恶意软件和窃取敏感信息。
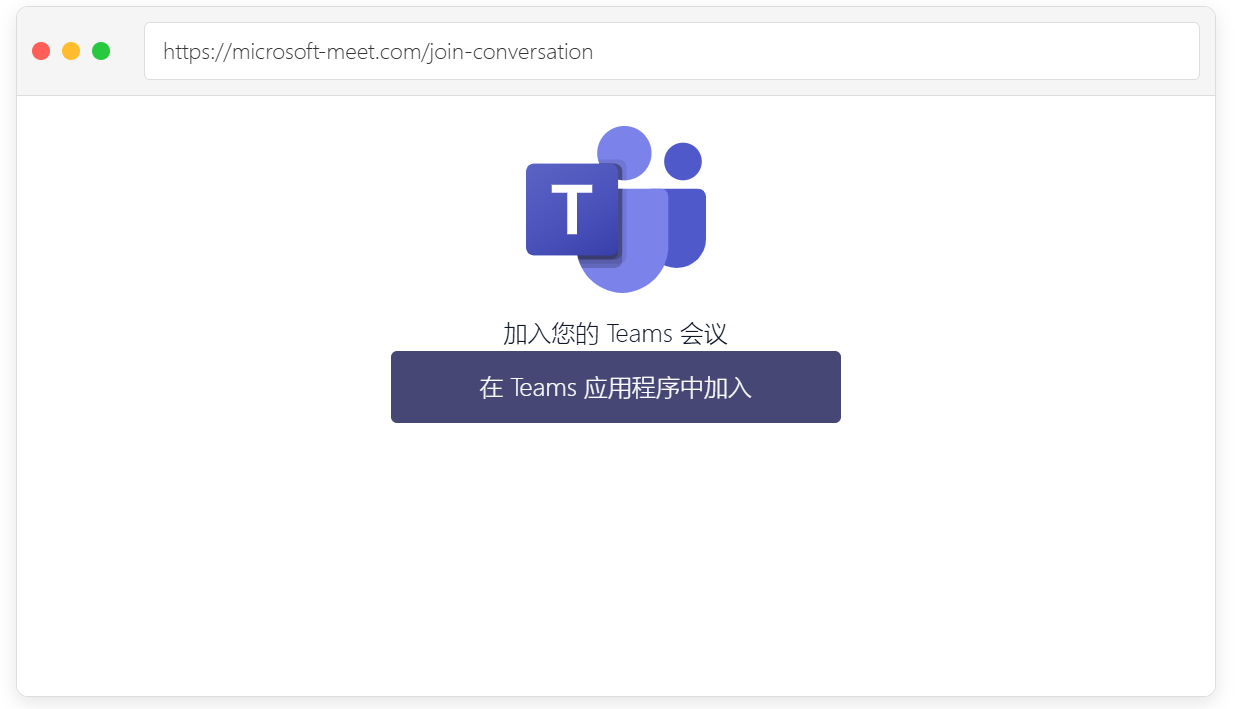
本示例中的钓鱼指标
- 可疑 URL:注意域名是 “microsoft-meet.com” 而不是 “teams.microsoft.com”
- 简化界面:与真实的 Teams 登录相比,虚假页面具有简化的界面
- 缺乏安全功能:缺少 Microsoft 通常包含的安全元素
- 加入按钮:突出的 “在 Teams 应用程序中加入” 按钮可能会导致恶意软件下载
安全提示
- 在输入凭据或下载软件之前,始终验证 URL。
- 仅从官方 Microsoft 网站或应用商店下载 Microsoft Teams。
- 对任何异常的安装过程或请求保持警惕。
- 如果您下载了可疑的软件包,可以在打开之前使用 VirusTotal.com 进行扫描。但请注意,即使没有检测到威胁(0 检测),也不能保证绝对安全。
Microsoft Teams 钓鱼攻击的工作原理
攻击者创建令人信服的 Microsoft Teams 登录页面或更新通知的复制品,诱骗用户下载恶意软件或泄露其凭据。这些攻击变得越来越复杂,针对个人和组织。
风险1:数据泄露
通过虚假 Teams 更新安装的恶意软件可以访问您设备上的敏感文件,可能导致未经授权访问个人和公司数据。这可能导致知识产权盗窃、机密信息泄露和合规违规。
风险2:凭据盗窃
当用户在虚假 Teams 网站上输入其 Microsoft 凭据时,攻击者会捕获这些信息以获取对电子邮件、OneDrive、SharePoint 和其他 Microsoft 365 服务的访问权限。这可能导致账户被接管并进一步危及组织资源。
风险3:钱包资金耗尽
对于从同一设备访问加密货币钱包或金融服务的用户,通过虚假 Teams 更新安装的恶意软件可能包含扫描钱包凭据的功能,导致数字资产被盗。
No.0x0037 虚假扩展程序钓鱼
挑战:识别出虚假扩展程序
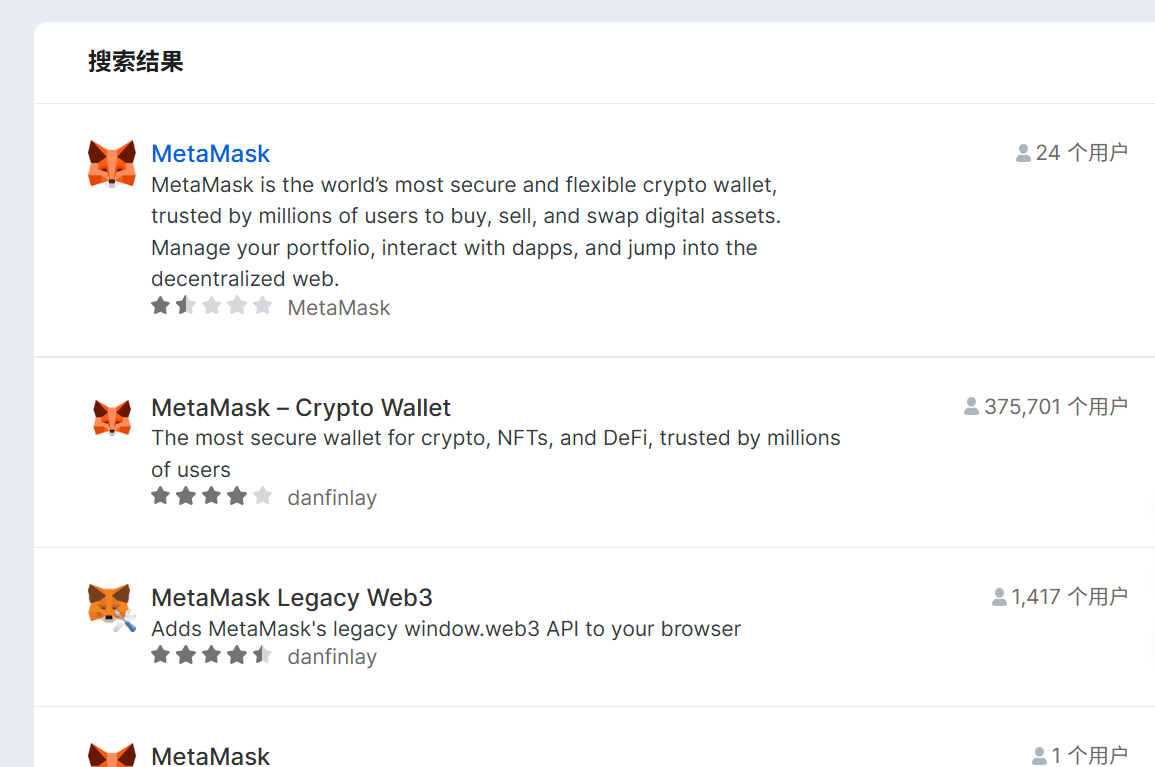
扩展程序安全最佳实践:
- 始终从官方网站下载:直接访问官方网站(例如 metamask.io),而不是在扩展商店中搜索。虚假或恶意扩展程序可能出现在搜索结果中,甚至出现在官方扩展商店中,有时会模仿真实扩展程序的名称、图标或品牌。通过访问官方网站,您可以确保获得正宗、安全的版本,避免落入可能危及您安全和资产的仿冒或诈骗列表的陷阱。
- 检查用户数量和评论:官方扩展程序拥有大量用户和普遍积极的评论
- 仔细阅读权限:只授予必要的权限
- 保持扩展程序更新:定期更新通常包含安全补丁
- 删除未使用的扩展程序:通过删除不再使用的扩展程序来减少攻击面
中级
No.0x0013 TransferFrom 零值转账钓鱼挑战
挑战:学习识别和避免零值转账诈骗
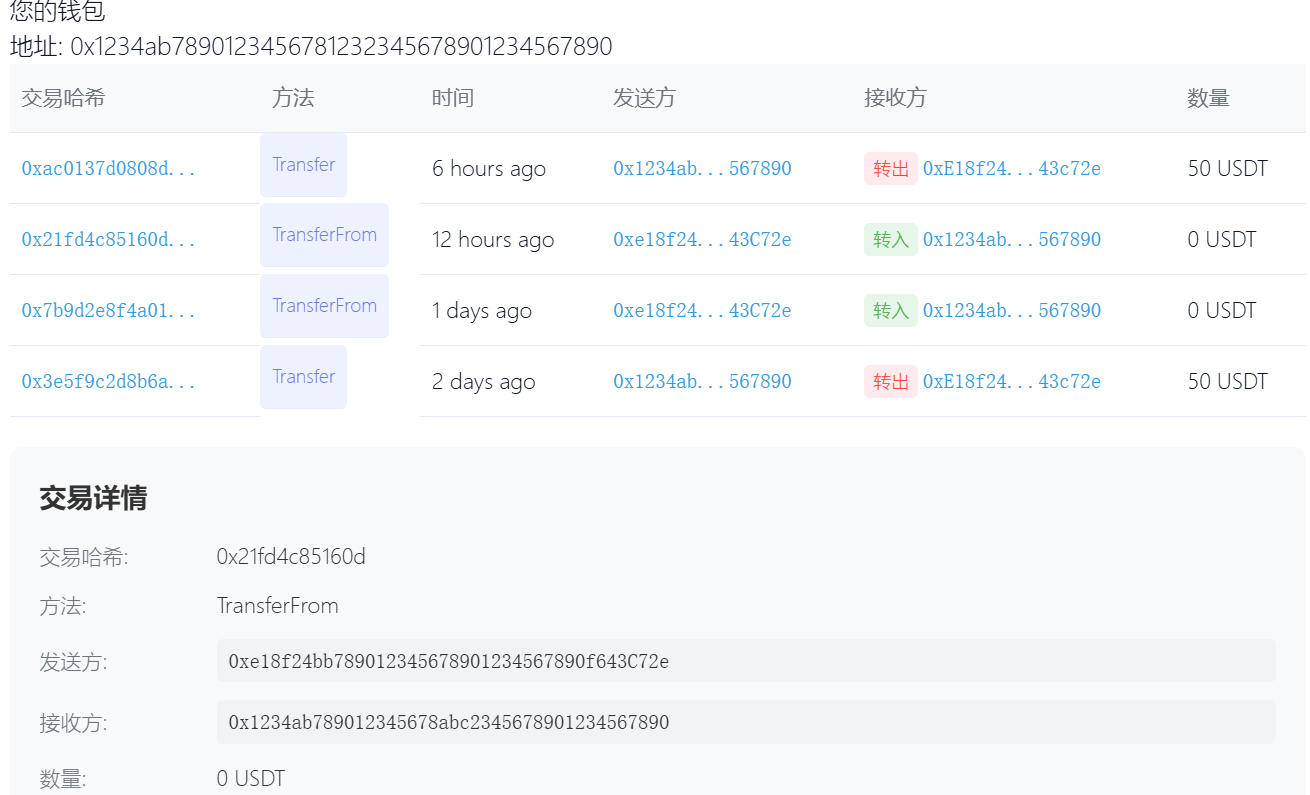
发现我的钱包地址和发送方发送到接收方的地址不同
1 | 我的钱包: 0x1234ab7890123456781232345678901234567890 |
诈骗者经常使用零值转账来创建与伪造地址的虚假交易历史,让受害者以为该地址为可信地址,从而做到地址混淆,让受害者向攻击方地址进行转账。
如何保护自己:
- 始终验证完整地址,而不仅仅是开头和结尾
- 警惕看起来与您之前交互过的地址相似的地址
- 仔细检查交易历史,包括零值转账
- 使用钱包的地址簿功能标记可信地址
- 考虑使用带有地址验证功能的硬件钱包
诈骗者利用“零值转账”伪造交易历史的原理及防范措施
1. 攻击原理
诈骗者通过发送 零值转账(0 ETH 或 0 代币) 到 伪造地址,目的是在区块链浏览器(如 Etherscan)上制造虚假的交易历史,诱导受害者误认为该地址是可信的。具体手法如下:
- 伪造交易历史:
攻击者向目标地址(如0x123...abc)发送多笔0 ETH转账,使该地址在 Etherscan 上显示与“知名地址”(如交易所、项目方)有交互记录。
- 例如:攻击者可能伪造一个与 Uniswap 路由合约 相似的地址,并提前用零值转账制造“活跃记录”。
- 地址混淆(Address Poisoning):
攻击者生成一个与受害者常用地址 开头和结尾相似 的地址(如0x1234...5678vs0x1234...9876),并发送零值转账,使受害者在复制粘贴时误选错误地址。- 诱导转账:
当受害者看到该地址有“历史交易”时,可能误以为是合法地址,从而将资金转入诈骗者的钱包。
8月6日
| 今日学习内容 |
|---|
| MyFirstLayer2 部分学习 |
| 区块链岗位全景图 |
MyFirstLayer2
1 公链瓶颈
1.1改进尝试
为了保证参与门槛足够低,比特币将全网同步的出块时间控制在 10 分钟,平均 TPS (每秒可处理交易笔数)仅有个位数。以太坊出块时间约 12 秒,平均 TPS 也仅有十几笔。这对比于传统 Web2 的经济活动来说,远远不够用
提高区块链性能的两个尝试:
增大单个区块的大小,容纳更多的交易
这样做会引起区块账本的快速膨胀,参与验证的机器性能要求越来越高,提高了参与门槛,导致整个网络去中心化程度和安全性渐渐降低。从 BTC 分叉出来的 BCH(Bitcoin Cash) 将区块大小从 1MB 提升至 32MB,BSV(Bitcoin Satoshi’s Vision) 则是更激进地取消了区块大小上限,允许无限多的信息融入一个区块。
降低出块的时间,追求一定时间内出更多的块来处理更多的交易
这样对节点的网络条件提出了更高要求,提高了参与门槛。并且影响了全网数据同步的稳定性,因为物理上相隔较远的节点集群容易对最新的区块产生分歧,导致分叉。分叉链总需要竞争出新的最长链,抛弃其中的一条分支,导致过去一段时间内的许多交易被重写,这就是“区块重组”现象,Polygon 在 2023 年发生过 157 个区块的重组事件。
此外,还有一些公链试图用更激进的方式改善性能:
使用数量更少的超级节点通讯:
超级节点的性能更强大,网络带宽更好更稳定,因此彼此之间能实现超高速的通讯,但这显然降低了去中心化程度。如 Fanton 有 51 个共识节点,BSC、EOS、TRON 则仅有 21 个超级节点。
用特殊的共识机制提升性能:
共识机制决定了全网节点对出块方式如何达成共识,一些特殊的机制也许可以提高出块速度,但共识机制越复杂,就对机器性能要求越高,也更容易出现单点故障导致整个系统出错。如 Solana,全网节点依赖随机选出的单个 Leader 节点来协调,因此获得了极高的理论 TPS 上限,但对节点性能要求变得非常高,并多次发生全网宕机的安全性事故。
目前高性能公链的探索成果,普遍获得了将 TPS 提升至 100 ~ 1000 的成绩,但共识节点数量也降低为几十个至一千多个不等。对比于以太坊分布全球的近万个共识节点 ,高性能公链在性能提高了一两个数量级的同时,去中心化程度也下降了一两个数量级。
1.2 区块链三难困境
由于区块链的底层特性,存在一个不可能三角悖论。区块链不可能三角(Blockchain Trilemma)是指在设计区块链系统时,存在三个目标之间的矛盾,这三个目标分别是去中心化、安全性和可扩展性(性能)
- 去中心化(Decentralization):指的是在区块链系统中,所有的节点都具有相同的权力,没有单一的中心化权威节点进行控制。这个目标是区块链的核心特性,也是保证系统安全性和抗攻击性的基础。
- 安全性(Security):指的是在区块链系统中,保证交易的真实性、完整性、不可篡改性和抗攻击性等方面的安全。这个目标是区块链系统的重要保障,也是确保系统可靠性和信任度的基础。
- 可扩展性(Scalability):可扩展性即性能,指的是在区块链系统中,支持足够大量的交易、节点和用户等系统扩展。这个目标是区块链系统的重要需求,也是确保系统能够满足现实需求的基础。
这三个目标之间存在矛盾关系。例如,在追求更高的去中心化的情况下,需要所有节点都保存完整的区块链数据,但是这会导致系统的可扩展性降低。相反,在追求更高的可扩展性的情况下,需要牺牲一定的去中心化;还比如采用分片技术 [1] 来扩容,但是可能导致节点同步数据困难,更容易发生故障,导致安全性降低。
高安全性和高可扩展性
追求安全性和可扩展性(即性能),往往采用少数超级节点进行通讯,超级节点拥有更强的性能和更好的网络环境,彼此之间能实现超高速的通讯。但参与门槛过高,牺牲了去中心化程度。
代表区块链:BSC、EOS、TRON 等区块链采用了少数高性能节点维护网络,仅有 21 个超级节点进行记账。
高可扩展性和高去中心化
追求可扩展性(即性能)和去中心化程度,为保证去中心化采用了较多验证节点,为了追求性能提高了出块速度,或采用了特殊的共识机制。但提高出块速度容易导致大规模区块重组,更复杂的共识机制容易导致全网宕机等安全事故,牺牲了安全性。
代表区块链:Polygon 在 2023 年发生了 157 个区块的大规模重组;Solana 多次出现全网宕机的事故。
高去中心化和高安全性
追求去中心化程度和安全性,采用更多的节点和更公平的出块方式,值得信赖。但为了允许低性能节点参与验证,协调全球网络延迟,导致每秒可处理的交易数较低,牺牲了性能。
代表区块链:BTC、ETH 追求了极致的安全可靠和去中心化,但处理交易的速度较低,BTC 约为 7 笔/秒,ETH 约为 10 - 20 笔/秒。
1.3 Layer 2
事实上,有一种方法可以克服区块链三难困境。而工程实践上,我们可以通过增加层级的方式来优化三者的矛盾,增加层级实现了业务解耦,降低了原先层级的负担。
增加第二层网络(Layer 2 ),来分摊一层网络(Layer 1)的负担,达到扩容的目的。
Layer 2 即二层网络,是在一层网络的基础上搭建的,用各种技术手段帮助底层公链扩容的解决方案
2 Layer 2发展史
2.1 状态通道(State channel)
假设 Alice 经常在一家咖啡店消费,如果每次买一杯 5 美元的咖啡,都需要支付 0.5 美元的手续费,这也太痛苦了。那么假如 Alice 和咖啡店能达成共识,每次买咖啡时付给咖啡店一张签了名的欠条,一段时间后咖啡店攒了足够多的欠条,将欠条算好总金额一次性兑现,这样交易成本就可以大幅降低,对双方都有利。这种思路就是最早的二层网络,也就是状态通道的原理。
状态通道 是一种区块链扩容技术,允许用户在链下进行高频、低成本的交互,仅在开启和关闭通道时与区块链交互,从而实现近乎即时、零摩擦的交易。状态通道使用了多签技术 [1],允许两个个体之间提前存入一笔资金锁定在智能合约中,建立一个内部通道,然后双方可以在通道内进行多笔小额转账,速度极快,成本极低,再在一段时间后用转账证明一次性提款。状态通道也是比特币的 Lightning Network(闪电网络),以太坊的 Raiden Network(雷电网络)背后的底层技术。
[1] 多签技术(Multi-sig):即多重签名技术,是指需要多个授权方共同授权才能完成交易,提高了交易的安全性和可靠性。如公司财库的资金要求三人之中的至少两人签名(2/3)才能动用,状态通道中则要求同时拥有双方的签名(2/2)才能生效,多签也允许出现更多 n/m 的授权条件。
1. 核心原理
(1) 基本流程
- 开启通道:
- 双方将资金锁定在链上的智能合约中(如存入 10 ETH)。
- 生成初始状态(如 Alice: 6 ETH,Bob: 4 ETH),并签名确认。
- 链下交易:
- 双方通过签名消息更新状态(如 Alice 转 1 ETH 给 Bob → Alice:5, Bob:5)。
- 无需矿工/验证者,交易即时生效。
- 关闭通道:
- 将最终状态提交到链上,合约根据最新状态分配资金。
- 若有争议(如一方提交过期状态),可挑战并惩罚作弊者。
(2) 技术关键点
- 多签名验证:每次状态更新需双方签名。
- 时间锁(Timelock):防止旧状态被恶意提交。
- 欺诈证明(Fraud Proof):允许诚实方在争议期举证。
2. 为什么需要状态通道?
问题 状态通道解决方案 链上交易慢且昂贵 链下交易零成本,即时确认 区块链吞吐量有限 支持无限次链下交互 隐私性差 交易细节仅在参与者间传递
3. 典型应用场景
(1) 高频微支付
- 案例:
- 按秒计费的视频流服务(如每小时支付 0.001 ETH)。
- 游戏内道具实时交易。
(2) 链下投票与治理
- 案例:
- DAO 成员在通道内频繁投票,最终结果上链。
(3) 隐私保护交易
- 案例:
- 双方链下协商价格,仅公开最终交易。
4.优缺点
✅ 优点
- 零延迟:交易即时完成。
- 零 Gas 费:链下交互无需付费。
- 隐私性:交易细节不上链。
❌ 缺点
- 通道管理复杂:需预先锁定资金。
- 适用性有限:仅适合固定参与者间的交互。
- 流动性要求:长期占用资金。
状态通道技术本质上是使用了中心化的节点,用户在链上质押一笔较大额的资金,然后在链下用签了名的“欠条”进行付款,积攒了一定量的“欠条”之后,任何一方都可以选择关闭通道进行结算。链上的智能合约只认可同时拥有双方签名的转账信息,Alice 和咖啡店都拥有自己的签名,再加上“欠条”上对方的签名,才能凑齐签名通过多签验证,因此无法提取不属于自己的资金。
但这样做产生了 2 个新的问题:
- Alice 和咖啡店之间攒“欠条”的约定仅适合于最简单的转账交易,去中心化金融要实现的交易比转账复杂得多,那么想要实现更复杂的交易要怎么办呢?为了解决这个问题,引出了侧链方案。
- Alice 可以给咖啡店发送资金,若超市与咖啡店有通道,也可以借助咖啡店向超市发送资金,但是如何给未参与雷电网络的个体发送资金呢?这个问题,则引出了 Plasma 方案。
2.2 侧链(Sidechain)
为了解决状态通道无法执行复杂交易的问题,侧链方案进入人们视野。
侧链可以理解为一条相对独立的区块链,它们往往采用与主链(一般是以太坊)类似的架构,方便主链上的项目迁移至侧链。
我们可以在主链的智能合约内锁定一定量的资产,然后在侧链上铸造等量资产,实现“原子交换”。用这种方式将资产存入侧链,在侧链上进行各种交易,然后在必要时转移回主链。
侧链核心特性
| 特性 | 说明 |
|---|---|
| 独立性 | 拥有自己的共识机制(如 PoA、PoS)、区块参数和智能合约。 |
| 双向锚定 | 资产可从主链锁定后映射到侧链,也能反向返回。 |
| 互操作性 | 通过桥接协议(Bridge)与主链通信。 |
| 定制化 | 可针对特定需求优化(如高TPS、低Gas费、隐私增强)。 |
侧链会进行一定的定制化,获得更高的性能,帮助主链分担交易压力。
- 采用 POS 共识机制(Proof of Stake),大幅提高了出块速度以达到扩容的目的。如 Polygon 侧链,将出块时间缩短至 2 秒。
- 采用 POA 共识机制(Proof of Authority),用更少的经过授权的超级节点进行通信,以实现侧链上的超高性能。如负责游戏资产交易的 Ronin 侧链,因游戏内的 NFT 资产本就比较中心化,所以这种更中心化的方案也可以接受。
侧链的工作原理
(1) 资产跨链流程(以以太坊 ↔ Polygon 为例)
- 存款(主链 → 侧链)
- 用户将 ETH 存入主链的桥合约,合约锁定资产并生成证明。
- 侧链验证证明后,在侧链上 mint 等量的封装资产(如 WETH)。
- 提款(侧链 → 主链)
- 用户销毁侧链的 WETH,提交销毁证明到主链桥合约。
- 主链合约验证后解锁原始 ETH。
(2) 共识机制差异
- 主链:通常采用高安全共识(如以太坊的 PoS)。
- 侧链:可能使用更高效的共识(如 Polygon PoS 链的 Bor 共识)。
为什么需要侧链?
| 主链瓶颈 | 侧链解决方案 |
|---|---|
| 低TPS(如以太坊15 TPS) | 侧链可达数千 TPS(如 Polygon 7,000 TPS)。 |
| 高Gas费 | 侧链交易成本极低(如 BSC 的 $0.01 交易费)。 |
| 功能限制 | 侧链可定制模块(如隐私交易、游戏专用链)。 |
典型侧链项目
| 侧链 | 锚定主链 | 特点 | 用例 |
|---|---|---|---|
| Polygon PoS | 以太坊 | 高TPS,EVM兼容 | DeFi、NFT |
| Gnosis Chain | 以太坊 | 注重去中心化,xDai 合并 | 支付、DAO |
| Liquid Network | 比特币 | 联邦桥接,支持机密交易 | 比特币快速结算 |
| Ronin | 以太坊 | Axie Infinity 游戏专用链 | GameFi |
侧链的安全风险
(1) 桥接攻击
- 案例:2022 年 Ronin 桥被盗 6.25 亿美元(私钥泄露)。
- 防御:使用多重签名、零知识证明桥(如 zkBridge)。
(2) 共识中心化
- 部分侧链(如 BSC)由少数节点控制,可能被操纵。
(3) 资产锚定失效
- 若桥合约漏洞导致双向锚定断裂,侧链资产可能脱钩。
侧链通过 牺牲部分主链安全性 换取高性能和低成本,是区块链生态的重要扩容手段。用户在使用时需权衡效率、成本与风险,优先选择经过时间验证的侧链和桥接协议。
2.3 Plasma
随着状态通道和侧链方案在实践中暴露出不足,Plasma 方案被提出并得到重视,它解决了前面两者暴露出的两个问题:
- 无法给未参与的个体发送资金:未加入 Plasma 链的账户也可以收到资金,然后自行提取到 Layer 1。
- 无法继承 Layer 1 安全性:Plasma 定期向主链提交信息,以继承 Layer 1 安全性。
Plasma 是以太坊创始人 Vitalik Buterin 和 Joseph Poon 在 2017 年提出的一种 区块链扩容方案,旨在通过构建多层链下结构(“子链”),将大部分交易从主链(如以太坊)卸载到子链上处理,从而显著提升吞吐量并降低交易成本。尽管后期因技术复杂性被 Rollup 取代,但 Plasma 的设计思想仍对 Layer2 发展影响深远。
Plasma 的核心思想
(1) 分层结构
- 主链(Root Chain):以太坊等底层区块链,负责最终结算和争议仲裁。
- 子链(Plasma Chain):独立的链下区块链,处理高频交易,定期向主链提交状态承诺(Merkle Root)。
(2) 关键机制
- 状态承诺:子链将交易批量打包后,生成 Merkle Root 并提交到主链。
- 欺诈证明(Fraud Proof):若子链作恶(如篡改交易),用户可提交证明至主链,触发惩罚和状态回滚。
- 资金退出(Exit):用户需通过主链的“退出游戏”机制安全取回资金。
Plasma 的工作原理
(1) 存款(主链 → Plasma 链)
- 用户将资产(如 ETH)锁定在主链的 Plasma 智能合约中。
- Plasma 链生成对应的资产凭证(如 1:1 映射的代币)。
(2) 链下交易(Plasma 链内)
- 用户在 Plasma 链上自由交易(如转账、支付),无需主链确认。
- 子链区块生产者(Operator)定期将交易打包,并提交 Merkle Root 到主链。
(3) 提款(Plasma 链 → 主链)
- 用户发起提款请求,启动 7天挑战期(类似 Optimistic Rollup)。
- 若无争议,主链释放锁定的资产;若有欺诈,提交证明取消提款。
Plasma 的优缺点
✅ 优点
- 高吞吐量:交易在子链处理,主链仅存储压缩数据。
- 低成本:Gas 费由子链承担,主链仅需极低开销。
- 安全性继承:依赖主链的欺诈证明机制确保资金安全。
❌ 缺点
- 退出延迟:提款需等待挑战期(7天),流动性受限。
- 数据可用性问题:**若子链运营商隐藏数据,用户无法构造欺诈证明。**
- 通用性差:难以支持复杂智能合约(仅适合支付等简单逻辑)。
为什么 Plasma 逐渐被淘汰?
- 数据可用性问题:用户无法获取子链完整数据时,无法挑战无效交易。
- 用户体验差:提款延迟长,且需主动监控欺诈。
- Rollup 的崛起:
- ZK Rollup 通过零知识证明解决数据问题。
- Optimistic Rollup 保留欺诈证明但强制数据上链,平衡安全与成本。
默克尔树利用了哈希算法(Hash Algorithm),每个子节点的内容,都影响着上一个节点的哈希值。因此保存在默克尔树内的数据,若被改变了哪怕一个字符,都将导致上方一连串节点的哈希值改变,最终传导至默克尔树的根部也发生改变。任何人都可以自行运算哈希算法来检查计算出的哈希值与公开的哈希值是否对应,以此确认内容是否被篡改。
2.4 Rollup
虽然 Plasma 最终未能大规模使用,但它的一些理念在后续的 Layer 2 方案中被吸收和发展。
既然困扰 Plasma 最大的问题是数据可用性,也就是监督者不容易获取交易数据以进行检验的问题。那我们如果不仅仅上传一个根证明,而是把必要的关键数据通通上传至 Layer 1 ,是不是就解决了这个棘手问题呢?
这个思路带来了目前最具可行性的 Layer 2 扩容方案: Rollup。Rollup 意为“打包”,也就是将一段时间内发生的交易先进行压缩,再进行打包,然后周期性地上传至主网。目前主流的 Rollup 方案分为两大路线,分别为 Optimistic Rollup(乐观的 Rollup)与 Zero-knowledge Rollup(零知识证明的 Rollup)。
- Optimistic Rollup:OP-Rollup 是将一段时间内的所有交易细节全部压缩打包,定期发送至 Layer 1。这种机制乐观地相信大部分交易都是诚实的,继承了 Plasma 挑战期和欺诈证明机制。
- Zero-knowledge Rollup:ZK-Rollup 一般是将一段时间内的交易计算完成后,将状态变化的结果压缩打包,并附上交易已经在 Layer 2 被正确执行的零知识证明,定期发送至 Layer 1。用零知识证明代替监督者,依赖数学而非验证者(Rely on Math, not Validators)。
Rollup 的核心思想
(1) 链下执行 + 链上验证
- 链下:交易在 Rollup 链(Layer2)上执行。
- 链上:交易数据(或有效性证明)提交到主链(Layer1),确保安全性。
(2) 数据压缩
- Rollup 将多笔交易压缩为 单个批次,减少链上存储开销。
- 例如:1000 笔交易 → 1 个 Rollup 区块 → 1 笔主链交易。
Rollup 的两种类型
(1) Optimistic Rollup(乐观汇总)
- 假设交易合法,默认不验证,依赖 欺诈证明(Fraud Proof) 争议机制。
- 特点:
- 兼容 EVM(如 Arbitrum、Optimism)。
- 提款需等待 7天挑战期。
- 成本低,适合通用智能合约。
工作流程:
- 交易在 Layer2 执行。
- 排序器(Sequencer)将交易数据(Calldata)提交到主链。
- 若有欺诈,验证者在挑战期内提交证明,回滚错误状态。
(2) ZK Rollup(零知识证明汇总)
- 每批交易生成 零知识证明(ZK-SNARK/STARK),主链即时验证。
- 特点:
- 无需挑战期,提款即时到账。
- 证明生成计算量大,早期难兼容 EVM(现 zkEVM 已突破)。
- 隐私性更强(可隐藏交易细节)。
工作流程:
- 交易在 Layer2 执行。
- 生成有效性证明(Proof)并提交到主链。
- 主链验证证明后,更新状态。
Rollup 的优缺点
✅ 优点
- 高扩展性:吞吐量提升百倍。
- 安全性:依赖主链验证,抗审查。
- 低成本:Gas 费仅为链上的 1/10~1/100。
❌ 缺点
- Optimistic 的延迟:提款需等待 7 天(可通过流动性提供商缓解)。
- ZK 的硬件需求:证明生成需要高性能服务器。
- 中心化风险:排序器可能被垄断(逐步去中心化中)。
零知识证明(Zero-Knowledge Proof, ZKP)详解
零知识证明 是一种密码学技术,允许一方(证明者)向另一方(验证者)证明某个陈述的真实性,而无需透露任何额外信息。其核心思想是:“我知道一个秘密,但我不会告诉你秘密是什么”。
在区块链领域,ZKP 是隐私保护(如 Zcash)和扩容(如 ZK Rollup)的核心技术。
1. 零知识证明的三大核心特性
- 完备性(Completeness):
- 如果陈述为真,诚实验证者一定会被说服。
- 可靠性(Soundness):
- 如果陈述为假,作弊的证明者无法欺骗验证者。
- 零知识性(Zero-Knowledge):
- 验证者除了“陈述为真”外,无法获取任何其他信息。
2. 经典类比:洞穴寓言
假设有一个环形洞穴,中间有一道需要密码才能打开的门。
- 证明者知道密码,想向验证者证明这一点,但不想泄露密码。
- 过程:
- 验证者站在洞口,随机要求证明者从左侧(A)或右侧(B)进入。
- 证明者无论从哪边进入,都能用密码开门并从另一侧出来。
- 重复多次后,验证者确信证明者确实知道密码,但始终不知道密码是什么。
3. 零知识证明的两种主要类型
(1) 交互式零知识证明(Interactive ZKP)
- 需要多轮通信(如洞穴寓言中的多次进出)。
- 缺点:效率低,不适合区块链。
(2) 非交互式零知识证明(Non-Interactive ZKP, NIZK)
- 证明者生成单次证明,验证者可随时检查。
- 区块链常用:如 ZK-SNARKs、ZK-STARKs。
4. 区块链中的 ZKP 技术
(1) ZK-SNARKs(简洁非交互式知识论证)
- 特点:
- 证明体积小(约 200 字节),验证速度快。
- 需要“可信设置”(Trusted Setup),存在潜在风险。
- 应用:
- Zcash(隐私转账)。
- zkSync(ZK Rollup)。
(2) ZK-STARKs
- 特点:
- 无需可信设置,抗量子计算。
- 证明体积较大(约 100 KB),但验证速度仍快。
- 应用:
- StarkNet(以太坊 Layer2)。
(3) Bulletproofs
- 特点:
- 无需可信设置,适合范围证明(如 Confidential Transactions)。
- 应用:
- Monero(隐私币)。
5. 零知识证明的区块链应用
(1) 隐私保护
- 匿名交易:Zcash 使用 ZK-SNARKs 隐藏发送方、接收方和金额。
- 身份验证:证明年龄 >18 岁,而无需透露出生日期。
(2) 扩容(ZK Rollup)
- 将数千笔交易打包,生成 ZKP 证明提交到主链,验证者只需检查证明即可确认有效性。
- 代表项目:zkSync、StarkNet、Scroll。
(3) 去中心化存储验证
- 证明文件已正确存储,而无需下载全部数据(如 Filecoin)。
6. 零知识证明的优缺点
✅ 优点
- 隐私性:隐藏敏感数据(如交易详情)。
- 扩展性:减少链上计算负担(如 ZK Rollup)。
- 安全性:数学上无法伪造证明。
❌ 挑战
- 计算密集型:生成证明需要高性能硬件。
- 可信设置(ZK-SNARKs):初始参数若泄露,可能伪造证明。
- 开发门槛高:需要密码学专业知识。
2.5 Layer 2 对比
核心特性对比
| 维度 | State Channel | Sidechain | Plasma | Rollup |
|---|---|---|---|---|
| 安全性 | 依赖最终结算 | 依赖侧链共识 | 依赖主链欺诈证明 | 继承主链安全性 |
| 交易速度 | 即时(链下) | 较快(依赖侧链性能) | 较快(链下执行) | 较快(链下执行) |
| 成本 | 链下免费,仅开/关通道付费 | 低(侧链Gas费) | 极低 | 极低(数据压缩) |
| 去中心化 | 需预存资金,参与者固定 | 可变(PoA/PoS) | 依赖运营商 | 逐步去中心化 |
| 数据存储 | 仅最终状态上链 | 独立链上存储 | 仅提交Merkle Root | 交易数据全上链(Rollup) |
| 适用场景 | 高频小额支付(如游戏) | 独立生态(如GameFi) | 简单支付/资产转移 | 通用智能合约 |
工作原理对比
(1) State Channel(状态通道)
- 流程:
- 双方锁定资金在主链。
- 链下无限次交易(仅双方签名)。
- 最终结算状态上链。
- 例子:比特币闪电网络、以太坊的Raiden Network。
(2) Sidechain(侧链)
- 流程:
- 资产通过桥锁定在主链,映射到侧链。
- 侧链独立运行(自有共识机制)。
- 提款时反向桥接回主链。
- 例子:Polygon PoS链、Ronin(Axie Infinity侧链)。
(3) Plasma
- 流程:
- 资产锁定在主链Plasma合约。
- 子链处理交易,定期提交Merkle Root到主链。
- 提款需挑战期(防欺诈)。
- 例子:早期OMG Network(已转向Rollup)。
(4) Rollup
- 流程:
- 交易在链下执行并压缩。
- 数据批量提交到主链(Optimistic需欺诈证明,ZK需有效性证明)。
- 例子:Optimism(OP)、Arbitrum、zkSync。
安全性对比
| 方案 | 安全模型 | 主要风险 |
|---|---|---|
| State Channel | 依赖参与者诚实 | 对手方离线时资金可能锁定 |
| Sidechain | 依赖侧链共识 | 桥接攻击(如Ronin被盗6.25亿美元) |
| Plasma | 主链欺诈证明 | 数据不可用性问题(运营商隐藏数据) |
| Rollup | 继承主链安全 | Optimistic的7天延迟,ZK的证明中心化 |
优缺点总结
| 方案 | 优点 | 缺点 |
|---|---|---|
| State Channel | 零延迟,零Gas费,隐私性好 | 仅限固定参与者,需预存资金 |
| Sidechain | 高性能,灵活定制 | 安全性依赖侧链,桥接风险 |
| Plasma | 高吞吐量,低成本 | 退出延迟长,不支持复杂逻辑 |
| Rollup | 继承主链安全,支持智能合约 | Optimistic有延迟,ZK开发门槛高 |
未来趋势
- Rollup 主导:Optimistic 和 ZK Rollup 成为以太坊扩容主流。
- State Channel 小众化:仅用于特定场景(如微支付)。
- Sidechain 专用化:游戏、社交等垂直领域。
- Plasma 淘汰:被 Rollup 取代(因数据可用性问题)。
3 Rollup详情
3.1 如何压缩
以 OP-Rollup 的为例,我们要向 Layer 1 上传一段时间内的所有交易详情,如果不对这部分数据进行高度压缩,那分担负载的效果就非常小了。我们以单笔交易为例,它身上其实有许多可改进的空间。
比如一笔常见的转账交易,它的原数交易数据可能是以下这样的:
4232f4610000000000000000000000007ea2be2df7ba6e54b1a9c70676f668455e329d29000000000000000000000000d548a5e31de2b4c2681a58a3be5302abcae4bc5700000000000000000000000000000000000000000000000000000000000186a0
(Method ID / 零填充[1] / 代币合约地址 / 零填充 / 收款的账户地址 / 零填充 / 提币数量)
[1]零填充:之所以要填充零占用空间,是因为以太坊中的交易数据是固定长度编码的,比如 Method ID 占用 128 位(32 个十六进制字母),地址和金额占用 256 位(64 个十六进制字母),不够长的信息字段需要填充 0 以保持数据对齐和一致性。
原始交易数据可以通过以下手段压缩:
- 用科学计数法把转账数量压缩成 64 位数据,并删除不必要的 0。(数量的精度会略微下降,但实践中影响不大)
- 调用的方法如果很常见,可以删除所调用的 Method ID,因为如“转账一笔 ERC20 [3] 代币”的交易,可以通过交易内容的特征推测
- 常用行为设置绿色通道(Helper ID):大部分发送代币的行为都是如 USDC、WETH 等常用代币,可以用更短的一个 Helper ID,来表示调用方法是“发送”,发送的代币是“USDC”这两个信息。
- 登记一个“电话簿”,记录收款人地址,将 40 位的地址压缩为第 XXX 页的第 X 个地址。
- 如果发送的是 ETH,连 Helper ID 都可以省掉。
最终我们需要上传至 Layer 1 的数据从一段非常长的信息
4232f4610000000000000000000000007ea2be2df7ba6e54b1a9c70676f668455e329d29000000000000000000000000d548a5e31de2b4c2681a58a3be5302abcae4bc5700000000000000000000000000000000000000000000000000000000000186a0
变为了
059c570186a0
(收款账户“电话簿”编号 / 提币数量)
数据压缩过程
- 原始状态
原始交易数据未经压缩
4232f4610000000000000000000000007ea2be2df7ba6e54b1a9c70676f668455e329d29000000000000000000000000d548a5e31de2b4c2681a58a3be5302abcae4bc5700000000000000000000000000000000000000000000000000000000000186a0
(Method ID / 零填充 / 代币合约地址 / 零填充 / 收款的账户地址 / 零填充 / 提币数量)
- 压缩状态1
用科学计数法把转账数量压缩成 64 位数据,并删除不必要的 0。(数量的精度会略微下降,但实践中影响不大)
4232f4617ea2be2df7ba6e54b1a9c70676f668455e329d29d548a5e31de2b4c2681a58a3be5302abcae4bc570186a0
(Method ID / 代币合约地址 / 收款的账户地址 / 提币数量)
- 压缩状态2
调用的方法如果很常见,可以删除所调用的 Method ID,因为如“转账一笔 ERC20 [3] 代币”的交易,可以通过交易内容的特征推测
7ea2be2df7ba6e54b1a9c70676f668455e329d29d548a5e31de2b4c2681a58a3be5302abcae4bc570186a0
(代币合约地址 / 收款的账户地址 / 提币数量)
- 压缩状态3
常用行为设置绿色通道(Helper ID):大部分发送代币的行为都是如 USDC、WETH 等常用代币,可以用更短的一个 Helper ID,来表示调用方法是“发送”,发送的代币是“USDC”这两个信息。
0000eed548a5e31de2b4c2681a58a3be5302abcae4bc570186a0
(Helper ID / 收款的账户地址 / 提币数量)
- 压缩状态4
登记一个“电话簿”,记录收款人地址,将 40 位的地址压缩为第 XXX 页的第 X 个地址。
0000ee059c010186a0
(Helper ID / 收款账户“电话簿”编号 / 提币数量)
- 压缩状态5
如果发送的是 ETH,连 Helper ID 都可以省掉。
059c010186a0
(收款账户“电话簿”编号 / 提币数量)
Layer 1 存储数据的成本是非常高昂的,Layer 2 的执行成本绝大部分的都消耗在了这一步,因此压缩需要上传的数据上可以显著降低 Layer 2 整体的交易成本。
3.2 进一步压缩
数据压缩是个远早于区块链就存在的技术,除了前面对交易的定制化压缩之外,还有许多压缩算法能帮助进一步压缩数据空间。
比如我们生活中往往都接触过 zip、rar、7z 压缩包,它们就是使用了压缩算法将各种文件的体积减小。 Optimism 的 Zlib 压缩算法、 Arbitrum 的 Brotli 压缩算法都能起到类似的作用。
3.3 Optimistic Rollup
Optimistic Rollup 是“乐观的打包”,它假设绝大部分的参与者都是诚实的,允许一批数量较少的验证者节点(Validator),对交易进行收集、排序、验证。同时还设置了挑战者的角色(Challenger),其职责是监督验证者提交的信息是否诚实。
OP-Rollup 会定期向主网上传两种数据:
- 状态根(State Root): 状态根可以快速确认 Layer 2 小账本的内容是否被篡改。
- 压缩后的全部交易数据:包含各种交易细节,比如交易附带的“用户签名”。
虽然上传了近段时间的全部交易详情,但以太坊主网并不负责直接验证这些交易,只起到一个公示的作用。
与 Plasma 类似,OP-Rollup 也使用默克尔树的形式保存了一个“小账本”,记录了全体账户的所有状态(账户余额)。如果我们相信目前的交易验证者(Validator)都是诚实的,那么状态根能快速确认当前 Layer 2 的小账本记录的内容是否被篡改,确保安全性。
反之,假如我们对目前的交易合法性产生质疑,任何第三方都可以在主网获取最近一段时间内所有交易的副本,重新验证之后,将自己验证的结果与 Layer 2 的小账本的记录做对比,确认小账本上的记录均为合法。如果发现作恶,挑战者就可以在 Layer 1 提交欺诈证明来改写 Layer 2 的状态。挑战成功后,不诚实的验证者将受到惩罚,挑战者将获得奖励。同时,受影响的交易将被回滚 [1],进行重新验证。
[1] 回滚的影响范围取决于具体 Layer 2 的设计机制。有些选择仅回滚无效的交易;有些选择将受影响的区块变为孤块,从未受影响的区块后继续,这将导致一段时间内的交易都将被回滚,进行重新验证;有些选择用多轮挑战等其他手段,缩小需要回滚的范围。
这个过程中,负责监督的挑战者(Challenger)是直接与 Layer 1 的智能合约交互的,一层对二层的状态有着最终裁决权。
这种设计之下,即使只有一个诚实的挑战者,也足以确保整个 Layer 2 的交易安全。不过代价是 OP-Rollup 必须提供一个退出窗口期,让挑战者有时间去检验并提交欺诈证明,因此使用官方桥从 OP-Rollup 网络提款往往需要 7 - 14 天的等待期。
OP-Rollup 的逻辑简单易懂,而且上传了全部交易细节,因此对 EVM [2] (以太坊虚拟机)的兼容性也非常好,很有利于落地实施。但漫长的挑战期实在是太痛苦了,有办法解决退出等待时间过长的问题吗?
[2] EVM 即 Ethereum Virtual Machine,是以太坊中智能合约的执行环境。虚拟机(Virtual Machine)是通过软件模拟的具有完整硬件系统功能的、运行在隔离环境中的完整计算机系统。开发者不必关心底层细节如何实现,只要在以太坊虚拟机中开发,就能确保代码执行环境的一致性。
3.4 Zero-Knowledge Proof
造成漫长等待期的原因,是因为 OP-Rollup 需要人的参与(挑战者扮演的角色)。如果能让整个过程不需要人的参与,只需要算法的参与,那就完美了。
零知识证明是指向他人证明某个命题为真,但又不透露“该命题为真”之外的任何信息。例如,有一个环形的长廊,在走廊中间某处有一道安装了密码锁的门。如果 A 要向 B 证明自己拥有该门的密码,无需向 B 展示自己打开密码锁的过程。只需要让 B 看着 A 从入口进入走廊,然后又从另一侧的出口走出走廊,就可以完全证明 A 拥有密码,同时免除了暴露密码的风险。
零知识证明具备以下性质:
- 完备性(Completeness):若命题为真,任何证明者可以向验证者提出令人信服的证据,即“真的可被验证”。
- 可靠性(Soundness):若命题为假,则不存在不诚实的证明者能骗过验证者,即“假的会被发现”。
- 零知识性(Zero-knowledge):证明某个命题为真,但又不透露“该命题为真”之外的其他任何信息。
工程实践上我们还要求零知识证明的算法拥有以下性质:
- 简洁性(Succinctness):证明很小且验证速度快。
- 零知识(Zero Knowledge):可以隐藏计算的输入信息。
ZK-Rollup 会周期性向主网上传 3 种数据:
- 状态根:状态根可以快速确认 Layer 2 小账本的内容是否被篡改。
- 交易数据:经过压缩和聚合的交易数据,例如将多个交易合并为一批次的状态变化结果。通过使用零知识证明保证交易的安全性,可以舍弃一些不必要的信息,例如前面提到的“用户签名”。
- 有效性证明:即零知识证明,让 Layer 1 的智能合约在经过简单验证后,就能确认交易已经被正确执行。
ZK-Rollup 与 OP-Rollup 最大的不同,就在于 Layer 1 是否对 Layer 2 上传的数据进行验证。
ZK-Rollup 方案依靠 Layer 1 上的智能合约,用很小的代价检验 ZK Proof 的有效性,如果检验通过则表示这批交易已经被正确执行,那就更新状态。如果检验不通过,则拒绝这一批次的交易。
OP-Rollup 则完全将 Layer 1 当成了解决数据可用性的公告板,依赖挑战者的监督,两者的安全性和交易确认速度都会产生明显差异。
ZK-Rollup 的优点显而易见:
- 依靠数学而非验证者,安全性更有保障,并且确认时间更短。
- 更高的压缩率,让 Layer 2 的扩容上限更高。
3.5 ZK 技术原理 STARK vs SNARK
本内容暂时无法理解
ZK-Rollup 的基础组件
ZK-Rollup 用了一些特定的数学工具,来实现在不透露原始输入数据的情况下确保交易已被正确执行,它通常包含以下主要技术:
- KZG 多项式承诺:因两个多项式最多拥有 n2 个交点,而定义域却存在极多的点,那么我们只需要检查有限的若干次,就能确信对方确实以正确的多项式进行了计算。若将信息编码在多项式中,则靠多次确认多项式在特定点上的输出结果,即可确认交易已被正确验证(确认过程原本是需要交互的,但可用其他方法变为非交互式)。
- 哈希算法:能将任意长度的数据映射为固定长度的哈希值,用于压缩证明。
- 椭圆曲线加密:可以将椭圆曲线上的两个点用难以预测的方式映射起来,用于构建证明系统。可用来进行一些复杂的证明,比如在不公开哈希值的情况下证明两个哈希相等。
- 随机数等其它组件:用于随机数来确认起始需要检查的点,并用类似“上一个哈希影响下一个哈希”的方式确认一连串需要检查的点,以确保检查点的随机性与非交互性。
SNARK
目前零知识证明主要有两种技术路线,SNARK 与 STARK。SNARK 出现更早,更加成熟,目前被更多的项目方采用。
SNARK:Succinct Non-Interactive Argument of Knowledge
- 简洁(Succinct):验证速度快于计算证明。
- 非交互式(Non-Interactive):无需证明者与验证者之间进行交互。如比特币的公私钥对也是一种零知识证明,但它要求私钥拥有者对一段文字进行签名才能证明自己拥有私钥,这需要发生一次交互。
- 统计学上的可靠(Argument):相对于数学上绝对的证明(即 100% 可靠),实现了统计学上的可靠(如 99.99999999%)。
- 包含信息(Knowledge):可将某些信息编码进零知识证明中,如一笔交易已被正确执行。
STARK
STARK:Scalable Transparent Argument of Knowledge
- 可扩展的(Scalable):在进行大规模交易的证明时,验证时间仍然较短。
- 透明的(Transparent):随机数公开可验证,无需像 SNARK 一样设置初始可信环境。
- 统计学上的可靠(Argument):相对于数学上绝对的证明(即 100% 可靠),实现了统计学上的可靠(如 99.99999999%)。
- 包含信息(Knowledge):可将某些信息编码进零知识证明中,如一笔交易已被正确执行。
对比两条技术路线,STARK 在 Layer 2 上处理大量交易时,其零知识证明生成速度和验证速度更快的特点将具有优势,并且具有抗量子性 [1],无需初始可信环境 [2],更加安全。而 SNARK 发展时间更久更成熟,将会更早取得应用。
SNARK 证明体积更小,并且随着技术发展,已经可以在升级后沿用最初的可信环境,在安全性上不会显著弱于 STARK。SNARK 与 STARK 的关系更像是 OP-Rollup 与 ZK-Rollup 之间的关系,前者可能更早落地,后者拥有更大潜力。
从底层技术路线去研究 ZK-Rollup 显得有点复杂了,有更简单的方式去理解 ZK-Rollup 吗?
[1] 抗量子性指能够在量子计算机攻击下保证信息安全。传统的加密算法(如 RSA、DSA 和 ECC 等)可能在将来的大规模量子计算机上被有效地破解,因此需要使用新的抗量子密码学算法来替代,确保加密在未来的量子计算机时代仍然安全。
[2] 初始可信环境是指在协议部署的最初,需要信任部署者诚实地部署了一个安全环境。比如参与部署的多个实体中,有一人销毁了自己的私钥,即可确认初始信息没有任何人能掌控。初始可信环境主要与随机数有关,零知识证明的计算过程非常依赖随机数作为输入,但如果初始的随机数被掌握,可能使得后续的计算变得可预测,产生被攻击的风险。
3.6 ZK 发展路线 ZK-VM vs ZK-EVM
ZK-VM:从零知识证明的角度出发
第一种思路是从零知识证明技术出发,专门开发适用于零知识证明的算法,从而构建一个 ZK-VM [1] (零知识虚拟机),而不是原生兼容 EVM 的 ZK-EVM [2] (零知识以太坊虚拟机),在此基础上尽可能实现 EVM 兼容。
StarkWare 和 zkSync 都采用了这种路线。StarkWare 的 Cairo 语言和 zkSync 的 Zinc 语言都是原生的零知识编程语言,甚至前者的账户地址系统与以太坊也存在很大的差异。
这种路线的优点是能够充分发挥零知识证明的潜力,实现最大化的扩展性。但缺点是开发者需要学习新的编程语言,并且现有项目需要将 Solidity 语言 [3] 的代码转换为 ZK-VM 的代码,这个过程中可能出现许多意想不到的问题,需要重新调试,重新审计。
ZK-EVM:从 EVM 兼容性的角度出发
反过来我们也可以从兼容 EVM 这个目的出发,将 EVM 的交易在操作码 [4] 层面切割成更小的步骤,对每个步骤去找对应的零知识证明算法,力求实现完全的 EVM 兼容。 这样做可以使开发者几乎无感地切换到二层网络,方便现有项目迁移,最大程度地保留目前的 EVM 生态成果。Scroll 和 Polygon Hermez 都采用了这种思路。
但是这种路线的缺点也显而易见,EVM 上的交易并非为零知识而设计,因此这种方法往往生成的证明体积较大,所需的时间也更长。
读到这里,我们已经了解了 Rollup 的当前进展。特别是零知识证明技术,令人感到十分神奇,使 Rollup 具备了非常大的潜力。但是仅仅通过 Rollup 实现扩容仍然存在上限,未来我们还有其他提升的空间吗?
[1] VM(Virtual Machine)即虚拟机,一个由软件模拟硬件的可控代码执行环境。 ZK-VM(Zero Knowledge - Virtual Machine) 是适应于零知识证明的虚拟机。
[2] ZK-EVM(Zero Knowledge - Ethereum Virtual Machine)是指利用了零知识证明技术的以太坊虚拟机,与原始的以太坊虚拟机有良好的兼容性。
[3] Solidity 语言是以太坊原生的开发语言,大部分运行在以太坊网络上的智能合约均采用 Solidity 编写。
[4] 计算机能直接读懂的语言是 0 和 1 ,操作码(Opcode)是非常底层的,与硬件(或是虚拟机中的虚拟硬件)直接交流的代码。操作码是指令集中每个指令的唯一标识符,在计算机执行指令时,用于识别具体指令的一个数字或符号。例如,在 x86 指令集中,加法指令(ADD)有一个特定的操作码,用于标识该指令。
此外还有一些相关概念:
- 指令集(Instruction Set): 指令集是一种用于编程的低级语言,它是计算机硬件能够理解和执行的一组指令。每种处理器都有自己的指令集,这些指令集定义了处理器可以执行的基本操作,如数据移动、算术和逻辑运算、条件分支等。指令集也被称为指令集架构(ISA,Instruction Set Architecture)。
- 字节码(Bytecode): 字节码是一种中间代码,介于源代码和机器代码之间。字节码通常由虚拟机(如 Java 虚拟机,JVM)执行,而不是直接由硬件执行。字节码的目的是提供一种平台无关的代码表示形式,这样不同平台上的虚拟机都可以执行相同的字节码。字节码通常比源代码更接近机器代码,但仍需要经过解释或编译为特定硬件的指令集。
指令集是计算机硬件能够执行的一组基本操作,每个操作都有一个唯一的操作码(Opcode)。字节码是一种平台无关的中间代码形式,它在执行时需要虚拟机将其转换为特定硬件的指令集。在这个过程中,字节码中的指令也会有相应的操作码。总之,操作码是指令的标识符,它在指令集和字节码中都有应用。
4 未来展望
4.1 其它解决方案:Validium 和 Volition
纵览二层扩容方案的发展历程,其实都源自于数据可用性影响了安全性与实用性。
- 侧链方案,数据对主链来说不可用,所以无法继承主链安全性。
- Plasma 方案,状态根可以保障链下账本的不被篡改,但具体交易数据对一层网络来说也不可用,导致资金退出困难。
- OP-Rollup 方案,让所有交易的详细数据都存在一层网络上,确保了全部交易数据的可用性,从而确保二层网络的安全。
- ZK-Rollup 方案,提供关键交易数据以及能证明链下交易已经被正确执行的零知识证明,实现安全性的同时,还能一定程度保证隐私性。Rely on Math,Not Validator.
那么基于零知识证明和数据可用性的新组合,我们可以得到 Validium 和 Volition (由 StarkNet 提出)两种未来可行的方案。
Validium
ZK-Rollup 仍向主网上传了交易数据,那如果我们进一步牺牲一点点安全性,连交易数据也不上传到一层,仅上传状态根和证明交易已被正确执行的零知识证明,由二层网络自行解决交易数据的保存,就可以进一步降低交易成本,这就是 Validium。
它有点像零知识版的 Plasma,Plasma 需要用户参与监督交易是否被诚实执行,而采用了零知识证明之后,不诚实的交易无法生成证明,极大地提升了节点作恶的难度。并且因为交易数据对于一层网络来说完全不可用,Validium 将具有更高的隐私性。
Volition
Volition 是 Validium 方案的改进版本,允许用户可以自行选择其交易数据是否在一层网络可用,涉及大额资金的交易可以采用成本略高但安全性更好的交易上链模式。资金量较小的、更追求隐私的交易可以使用交易记录不上链的模式。
1. Validium:链下数据 + ZK 证明
核心特点
- 数据存储:交易数据存储在链外(由第三方委员会或去中心化网络维护,如 StarkEx 的 DAC)。
- 安全性依赖:依赖数据可用性委员会(DAC)的诚实性,若委员会作恶可能冻结资金(但无法盗取,因 ZK 证明保证状态正确)。
- 优势:
- 极低的交易成本(无需支付以太坊主网的数据存储费用)。
- 高吞吐量(适合高频交易场景,如交易所、游戏)。
- 劣势:
- 牺牲部分去中心化(需信任 DAC)。
- 用户无法独立验证数据(需委员会配合提供数据)。
典型应用
- dYdX(V3 版本):采用 Validium 模式处理现货交易,降低手续费。
- Immutable X:为 NFT 交易提供零 Gas 费体验。
2. Volition:用户自选数据存储模式
核心特点
- 混合架构:允许用户为每笔交易选择数据存储方式:
- ZK-Rollup 模式:数据上链(高安全性,高成本)。
- Validium 模式:数据链下(低成本,依赖 DAC)。
- 灵活性:同一应用中,不同用户(甚至同一用户的不同交易)可自由选择模式。
- 优势:
- 平衡安全性与成本(例如,大额交易选 Rollup,小额选 Validium)。
- 无需迁移即可切换模式。
- 劣势:
- 实现复杂度较高。
典型应用
- StarkEx(StarkWare 的引擎):支持 Volition,供开发者灵活配置。
- Sorare(梦幻足球 NFT 平台):对普通用户用 Validium,对机构用户用 Rollup。
| 维度 | Validium | Volition |
|---|---|---|
| 数据存储 | 强制链下(DAC) | 用户可选链上(Rollup)或链下(Validium) |
| 安全性 | 依赖 DAC | 用户自主控制安全等级 |
| 成本 | 极低(无链上数据费) | 按需支付(Rollup 模式更贵) |
| 适用场景 | 高频、低价值交易(如交易所) | 需灵活性的应用(如混合型 DeFi/NFT) |
| 代表项目 | dYdX V3, Immutable X | StarkEx 生态项目(如 Sorare) |
4.2 Deneb 更新与 Layer 2
以太坊 Deneb 更新(原 EIP-4844 )是以太坊扩容路线 DankSharding 的前置步骤,旨在保证以太坊信标链安全性的前提下,为 Layer 2 扩容提供更大的储存资源。
Deneb 更新添加了一种新的交易:Blob 交易(大型二进制对象 Binary Large Object)。在主链上只留存指针,指针指向一个 Blob 块,上面可以储存约 128KB 的二进制数据。
以太坊矿工只负责在一段时间内(如一个月)保存 Blob 上的数据,通过随机抽样的方式确保 Blob 上二进制数据的真实性,但不验证存在 Blob 上的交易。
Blob 交易看起来对常规交易的扩容没有帮助,但这对于 Layer 2 打包的交易数据来说简直是完美契合。Layer 2 原先定期上传给 Layer 1 上的打包交易数据本来就不会执行,只是起到保障数据可用性的作用。
而 Blob 本身就相当于一个公示板,消息在公示板上的存续时间超过了 OP-Rollup 的挑战期,实践上完全够用,存储成本却降低了许多,这将促使 Layer 2 的交易成本进一步降低。
Blob 增加的唯一缺憾是超过保存期之后,Layer 2 如果想保存自己的全部历史交易数据,需要用另外的方案自行解决这些数据的可用性问题。
总体来说,Deneb 更新之后,Layer 2 将可以在保证安全性的同时进一步降低交易成本,变得更具实用价值。
探索到这里,我们增加了这么多性能,在应用层能有什么提升吗? 还是单纯只是量的堆积?
4.3 账户抽象与大规模应用
钱包毫无疑问是 Web3 最重要的流量入口,是用户进入 Web3 世界最重要的工具,大部分用户主要接触到的钱包都是 EOA 钱包(外部拥有账户),即通过私钥和助记词掌握整个钱包的权限(如 MetaMask、Coinbase Wallet、Trust Wallet 等),这种 EOA 钱包有如下问题:
- 高学习成本:用户需要了解复杂的非对称加密知识,理解任何人拥有私钥就能拥有账户,失去私钥就是失去资金的控制权。
- 单点失效问题:私钥泄露丢失,或忘记密码时,既不能用手机或邮箱,也不能柜面处理用身份证件恢复,资产将永久丢失。
- 风险控制难度较高:存在很多恶意攻击手段,试图盗取私钥;或在不盗取私钥的前提下,用恶意授权、恶意签名等方式盗取用户资产。新用户需要漫长的学习,具备谨慎的使用习惯才能保护资产安全。
- 不支持智能合约:无法实现复杂多样的高级功能,如多签、批量发送代币等等。
账户抽象(Account Abstraction)本质上是个智能合约钱包。是指将某些功能和具体实现细节抽象出来,用一系列的智能合约模拟出一个“账户”的效果,脱离了 EOA 账户用私钥控制地址的底层原理,允许其它更人性化的确认账户所有权的方式,并让整个账户的功能更加灵活。它解决了现有 EOA 账户的问题:
- 更符合现有的账户使用习惯:可以像传统 Web2 服务一样登陆,使用邮箱、手机短信、两步验证等验证方法。
- 更多安全保障机制:出现安全风险时可以紧急暂停账户功能,并采用社交恢复等手段重新掌握账户控制权。
- 可以接入第三方安全模块:接入专业的风控模块,过滤风险操作,从底层降低被攻击的可能。
- 支持智能合约的更多功能:让用户在不具备代码能力的情况下使用多签、批量发送多种代币、批量授权额度等等操作。
甚至还增加了许多新的可能:
- 代理支付 Gas 费:允许第三方支付 Gas 费,可以由钱包运营商补贴 Gas 费来吸引用户,钱包作为入口展现商业价值,用户享受更便宜的服务。
- 条件交易:在满足一定条件时自动执行某些交易。
- 跨链操作:可以和跨链桥智能合约实现原生的交互,更灵活地实现资产跨链和其他跨链交互。
- 更多 DeFi 场景:账户抽象为 DeFi 提供了更多可能,如批量交易、自动借贷、流动性挖矿等。
账户抽象极大地拓展了以太坊的可能性,但账户抽象的问题在于一切交易都基于智能合约完成,Gas 成本较高,这让它在以太坊主网上显得过于昂贵。
Layer 2 作为一个执行层,天然适配账户抽象,用户不会感知到私钥甚至不会感知到 Gas 费的存在。智能合约钱包本身就是程序,能引入风控等第三方服务,让转账和交互变得安全,有更多的丰富业务场景可以实现。可以说将来区块链技术的大规模应用技术离不开账户抽象,而账户抽象需要成本更低的 Layer 2 才能成立。
区块链岗位全景图
一、技术岗
1. 前端工程师
主要职责:
- 设计和开发基于区块链技术的前端应用,支持去中心化平台的交互。
- 通过 React、Vue 等框架实现高效的用户界面,支持钱包连接、交易签名、信息验证等功能。
- 集成并优化智能合约的前端交互,确保链上数据与用户界面的无缝连接。
- 与后端团队协作,基于 GraphQL 或 RESTful API 获取链上和链下数据。
- 持续优化前端性能,提升用户体验,确保在不同设备和浏览器上的兼容性。
- 关注 Web3 技术趋势,参与技术评审与分享,不断优化产品架构与代码质量。
职位要求:
- 本科及以上学历,计算机科学或相关专业,具备扎实的计算机基础。
- 精通 HTML、CSS、JavaScript,熟悉 React、Vue 等前端框架,能够独立构建复杂的 UI 界面。
- 熟悉 Web3.js、Viem、Metamask 等 Web3 技术栈,能够与智能合约进行交互。(现在 Ethers.js / Web3.js 已经不怎么使用了,大家现在基本上都是用的 Viem)
- 了解常用的区块链网络,如以太坊、Solana 等,具备 Dapp 开发经验者优先。
- 熟悉 Git 版本管理工具,具备良好的代码编写规范,注重代码可维护性。
- 良好的沟通能力和团队协作精神,能够在快速发展的环境中高效工作。
- 具有良好的问题解决能力,能在面对复杂的技术难题时,提出创新的解决方案。
- 有开源项目或 Web3 相关项目的经验优先。
1
2
3
4
5
6
7
8# 常用技术栈
- HTML5
- CSS3
- JavaScript (ES6+)
- React / Vue
- TypeScript
- Next.js
- Ethers.js / Web3.js / Viem
2. 后端工程师
主要职责:
- 设计、开发和维护去中心化应用(Dapp)的后端服务,包括链上数据交互、智能合约集成和事务处理。
- 与前端团队合作,确保前后端数据交互的高效性和稳定性,支持多种 Web3 钱包(如 Metamask)的集成。
- 基于 Node.js、Python 等技术栈构建高性能的 RESTful 或 GraphQL API,以支持 Web3 平台的需求。
- 与智能合约团队合作,确保智能合约与后端服务的无缝连接,优化链上数据的读取和写入效率。
- 优化后端性能,确保系统的高可用性、高吞吐量和低延迟,满足高并发访问需求。
- 定期进行系统架构和代码的评审,不断提升代码质量与技术标准。
- 参与 Web3 技术的前沿研究,保持对新兴区块链技术的学习和应用,推动公司技术迭代。
职位要求:
- 本科及以上学历,计算机科学或相关专业,具备扎实的计算机基础。
- 精通 Node.js、Go、Python 等后端开发语言,具有构建高并发、分布式系统的经验。
- 熟悉 Viem、Web3.js、Ethers.js 等 Web3 工具,能够与区块链进行交互并处理链上数据。
- 具备 RESTful API 或 GraphQL 开发经验,能够设计高效的 API 服务,支持前端与区块链的交互。
- 熟悉数据库技术,具备 MySQL、PostgreSQL 或 NoSQL 数据库的开发与优化经验。
- 对智能合约有一定的了解,具备与智能合约交互、读取链上数据等相关经验。
- 熟悉消息队列(如 RabbitMQ、Kafka)及事件驱动架构,能够处理异步事务。
- 熟悉容器化技术(如 Docker、Kubernetes),具备 CI/CD 经验者优先。
- 良好的代码编写规范与文档写作能力,具备良好的团队协作精神和沟通能力。
- 有 Web3 项目开发经验或开源贡献者优先。
1
2
3
4
5
6# 常用技术栈
- Node.js / Go / Python
- Viem / Web3.js / Ethers.js
- RESTful API / GraphQL
- MySQL / PostgreSQL
- Docker / Kubernetes
3. 智能合约工程师
主要职责:
- 设计、开发和部署智能合约,确保合约在区块链网络上的安全性、可靠性和高效性。
- 使用 Solidity 编写智能合约,涵盖各类去中心化应用的需求,如 NFT、DeFi、DAO 等。
- 与团队合作,定义智能合约的功能需求,并根据需求设计合适的智能合约架构。
- 部署智能合约至区块链网络(如以太坊、Polygon、Arbitrum、Base 等),并确保合约的高效执行。
- 编写智能合约的单元测试,进行代码审计与安全性测试,确保合约代码无漏洞,避免潜在的安全风险。
- 优化智能合约性能,减少 Gas 费用。
- 研究和应用最新的区块链技术和智能合约最佳实践,推动技术的持续进步。
- 与前端和后端开发团队紧密协作,确保智能合约与其他系统组件的顺畅集成。
- 为团队成员提供智能合约相关的技术支持和指导,推动团队的技术提升。
职位要求:
- 本科及以上学历,计算机科学或相关专业,具备扎实的计算机基础。
- 3 年以上智能合约开发经验,熟练使用 Solidity 或类似的智能合约开发语言。
- 熟悉 Ethereum、Polygon、Arbitrum、Base 等主流区块链平台,能够在这些平台上部署和维护智能合约。
- 了解智能合约开发的安全性问题,具备智能合约审计和漏洞修复经验,熟悉常见的攻击模式(如重入攻击、溢出、权限管理等)。
- 熟悉区块链的基本原理,理解 Gas 费用、交易确认、区块链共识机制等概念。
- 熟练使用 Foundry、Hardhat、Remix 等智能合约开发框架,具备项目开发、测试与部署经验。
- 具备一定的 Viem、Web3.js、Ethers.js 等 Web3 工具使用经验,能够与前端或其他系统进行无缝集成。
- 熟悉 IPFS、NFT、Token 标准(ERC-20、ERC-721、ERC-1155 等)及去中心化身份(DID)等 Web3 相关技术。
- 具有良好的代码编写规范,注重代码的可读性和可维护性。
- 良好的沟通能力和团队协作精神,能够在快速发展的环境中有效工作。
1
2
3
4
5
6# 常用技术栈
- Solidity
- Remix
- Foundry / Hardhat
- Phalcon / Tenderly
- Yul
二、非技术岗
1. 产品与运营
- 职位描述:
- 在 Web3 产品生命周期中负责协调产品发布、用户反馈收集和持续改进流程,以提升用户体验和产品迭代效率。
- 执行以用户获取、留存和参与度提升为目标的增长战略,并监控实施效果。
- 与产品、技术、市场及合规团队紧密合作,确保产品上市(go-to-market)策略与各部门需求保持一致。
- 持续分析运营数据,跟踪关键绩效指标(KPIs),并根据数据提出优化建议。
- 职位要求:
- 熟悉产品上线(Go-to-market)全流程,擅长跨部门资源协调与项目推进。
- 具备扎实的数据分析能力,能熟练使用 SQL、Excel 或其他数据工具进行数据统计和洞察提炼。
2. 社区管理
职位描述
- 构建并管理 Telegram、Twitter(X)、Discord 等社交平台的社区,实现持续的用户互动与增长;
- 组织线上 AMA(问答)、活动、竞赛等形式多样的社区互动,以提升用户活跃度和品牌粘性;
- 跟踪社区健康度指标和情感分析,定期向管理层汇报洞察与优化建议;
- 与营销团队协作,制定并执行内容日历,发布社区公告和运营手册。
职位要求
- Web3、DAO 或 NFT 社区管理经验,深刻理解去中心化应用生态;
- 出色的文案撰写与沟通能力,能够有效引导社区讨论并快速响应用户反馈;
- 熟练使用社区数据分析工具,能够监测并解读用户行为与舆情动态;
- 具备活动策划与执行能力,能够独立组织线上及线下社区活动。
1
2
3
4# 常用平台
- Telegram
- Twitter (X)
- Discord
3. 研究分析
职位描述
- 收集、整理并分析 Web3 行业市场与用户数据,编写可行性研究报告,为产品与运营提供决策支持;
- 跟踪区块链协议技术演进及生态动态,撰写深度研究报告或白皮书;
- 进行竞争对手分析,评估市场趋势与用户行为模式,为战略规划提供数据驱动的建议;
- 支持项目的加密经济模型设计与博弈论分析,以保证项目的经济激励合理性。
职位要求
- 熟练使用 Excel、SPSS 或 Python 等数据分析工具,具备定量和定性研究方法经验;
- 深入了解区块链生态、DeFi 协议及加密经济学原理;
- 优秀的报告撰写与演示能力,能够清晰传达研究结论与建议;
- 精通链上数据分析工具(Glassnode、Token Terminal)。
1
2
3
4
5
6# 常用工具
- Excel
- SPSS
- Python
- Glassnode
- Token Terminal
8月7日
| 今日学习内容 |
|---|
| MyFirstLayer2 剩余学习 |
| 行业赛道全览 |
行业赛道全览
8月8日
| 今日学习内容 |
|---|
| 安全与合规 |
| CryptoZombiesx的solidity学习/Solidity: Beginner to Intermediate Smart Contracts/lesson1搭建僵尸工厂 |
CryptoZombiesx的solidity学习
Solidity: Beginner to Intermediate Smart Contracts
lesson1 搭建僵尸工厂
第2章: 合约
从最基本的开始入手:
Solidity 的代码都包裹在合约里面. 一份合约就是以太应币应用的基本模块, 所有的变量和函数都属于一份合约, 它是你所有应用的起点.
一份名为 HelloWorld 的空合约如下:
1 | contract HelloWorld { |
版本指令
所有的 Solidity 源码都必须冠以 “version pragma” — 标明 Solidity 编译器的版本. 以避免将来新的编译器可能破坏你的代码。
例如: pragma solidity ^0.4.19; (当前 Solidity 的最新版本是 0.4.19).
综上所述, 下面就是一个最基本的合约 — 每次建立一个新的项目时的第一段代码:
1 | pragma solidity ^0.4.19; |
实战演习
为了建立我们的僵尸部队, 让我们先建立一个基础合约,称为 ZombieFactory。
- 在右边的输入框里输入
0.4.19,我们的合约基于这个版本的编译器。 - 建立一个空合约
ZombieFactory。
一切完毕,点击下面 “答案” . 如果没效果,点击 “提示”。
1 | pragma solidity ^0.4.19; |
第3章: 状态变量和整数
真棒!我们已经为我们的合约做了一个外壳, 下面学习 Solidity 中如何使用变量。
状态变量是被永久地保存在合约中。也就是说它们被写入以太币区块链中. 想象成写入一个数据库。
例子:
1 | contract Example { |
在上面的例子中,定义 myUnsignedInteger 为 uint 类型,并赋值100。
无符号整数: uint
uint 无符号数据类型, 指其值不能是负数,对于有符号的整数存在名为 int 的数据类型。
注: Solidity中,
uint实际上是uint256代名词, 一个256位的无符号整数。你也可以定义位数少的uints —uint8,uint16,uint32, 等…… 但一般来讲你愿意使用简单的uint, 除非在某些特殊情况下,这我们后面会讲。
实战演习
我们的僵尸DNA将由一个十六位数字组成。
定义 dnaDigits 为 uint 数据类型, 并赋值 16。
1 | pragma solidity ^0.4.19; |
第4章: 数学运算
在 Solidity 中,数学运算很直观明了,与其它程序设计语言相同:
- 加法:
x + y - 减法:
x - y, - 乘法:
x * y - 除法:
x / y - 取模 / 求余:
x % y(例如,13 % 5余3, 因为13除以5,余3)
Solidity 还支持 *乘方操作* (如:x 的 y次方) // 例如: 5 ** 2 = 25
1 | uint x = 5 ** 2; // equal to 5^2 = 25 |
实战演习
为了保证我们的僵尸的DNA只含有16个字符,我们先造一个uint数据,让它等于10^16。这样一来以后我们可以用模运算符 % 把一个整数变成16位。
- 建立一个
uint类型的变量,名字叫dnaModulus, 令其等于 10 的dnaDigits次方.
1 | pragma solidity ^0.4.19; |
第5章: 结构体
有时你需要更复杂的数据类型,Solidity 提供了 结构体:
1 | struct Person { |
结构体允许你生成一个更复杂的数据类型,它有多个属性。
注:我们刚刚引进了一个新类型,
string。 字符串用于保存任意长度的 UTF-8 编码数据。 如:string greeting = "Hello world!"。
实战演习
在我们的程序中,我们将创建一些僵尸!每个僵尸将拥有多个属性,所以这是一个展示结构体的完美例子。
- 建立一个
struct命名为Zombie. - 我们的
Zombie结构体有两个属性:name(类型为string), 和dna(类型为uint)。
1 | pragma solidity ^0.4.19; |
第6章: 数组
如果你想建立一个集合,可以用 数组这样的数据类型. Solidity 支持两种数组: 静态数组和动态数组:
1 | // 固定长度为2的静态数组: |
你也可以建立一个 结构体类型的数组 例如,上一章提到的 Person:
1 | Person[] people; // 这是动态数组,我们可以不断添加元素 |
记住:状态变量被永久保存在区块链中。所以在你的合约中创建动态数组来保存成结构的数据是非常有意义的。
公共数组
你可以定义 public 数组, Solidity 会自动创建 getter 方法. 语法如下:
1 | Person[] public people; |
其它的合约可以从这个数组读取数据(但不能写入数据),所以这在合约中是一个有用的保存公共数据的模式。
实战演习
为了把一个僵尸部队保存在我们的APP里,并且能够让其它APP看到这些僵尸,我们需要一个公共数组。
- 创建一个数据类型为
Zombie的结构体数组,用public修饰,命名为:zombies.
1 | pragma solidity ^0.4.19; |
第7章: 定义函数
在 Solidity 中函数定义的句法如下:
1 | function eatHamburgers(string _name, uint _amount) { |
这是一个名为 eatHamburgers 的函数,它接受两个参数:一个 string类型的 和 一个 uint类型的。现在函数内部还是空的。
注:: 习惯上函数里的变量都是以(
_)开头 (但不是硬性规定) 以区别全局变量。我们整个教程都会沿用这个习惯。
我们的函数定义如下:
1 | eatHamburgers("vitalik", 100); |
实战演习
在我们的应用里,我们要能创建一些僵尸,让我们写一个函数做这件事吧!
- 建立一个函数
createZombie。 它有两个参数: _name (类型为string), 和 _dna (类型为uint)。
暂时让函数空着——我们在后面会增加内容。
1 | pragma solidity ^0.4.19; |
第8章: 使用结构体和数组
创建新的结构体
还记得上个例子中的 Person 结构吗?
1 | struct Person { |
现在我们学习创建新的 Person 结构,然后把它加入到名为 people 的数组中.
1 | // 创建一个新的Person: |
你也可以两步并一步,用一行代码更简洁:
1 | people.push(Person(16, "Vitalik")); |
注:
array.push()在数组的 尾部 加入新元素 ,所以元素在数组中的顺序就是我们添加的顺序, 如:
1 | uint[] numbers; |
实战演习
让我们创建名为createZombie的函数来做点儿什么吧。
- 在函数体里新创建一个
Zombie, 然后把它加入zombies数组中。 新创建的僵尸的name和dna,来自于函数的参数。 - 让我们用一行代码简洁地完成它。
1 | pragma solidity ^0.4.19; |
第9章: 私有 / 公共函数
Solidity 定义的函数的属性默认为公共。 这就意味着任何一方 (或其它合约) 都可以调用你合约里的函数。
显然,不是什么时候都需要这样,而且这样的合约易于受到攻击。 所以将自己的函数定义为私有是一个好的编程习惯,只有当你需要外部世界调用它时才将它设置为公共。
如何定义一个私有的函数呢?
1 | uint[] numbers; |
这意味着只有我们合约中的其它函数才能够调用这个函数,给 numbers 数组添加新成员。
可以看到,在**函数名字后面使用关键字 private 即可。和函数的参数类似,私有函数的名字用(_)起始。**
实战演习
我们合约的函数 createZombie 的默认属性是公共的,这意味着任何一方都可以调用它去创建一个僵尸。 咱们来把它变成私有吧!
- 变
createZombie为私有函数,不要忘记遵守命名的规矩哦!
1 | pragma solidity ^0.4.19; |
第10章: 函数的更多属性
本章中我们将学习函数的返回值和修饰符。
返回值
要想函数返回一个数值,按如下定义:
1 | string greeting = "What's up dog"; |
Solidity 里,函数的定义里可包含返回值的数据类型(如本例中 string)。
函数的修饰符
上面的函数实际上没有改变 Solidity 里的状态,即,它没有改变任何值或者写任何东西。
这种情况下我们可以把函数定义为 view, 意味着它只能读取数据不能更改数据:
1 | function sayHello() public view returns (string) { |
Solidity 还支持 pure 函数, 表明这个函数甚至都不访问应用里的数据,例如:
1 | function _multiply(uint a, uint b) private pure returns (uint) { |
这个函数甚至都不读取应用里的状态 — 它的返回值完全取决于它的输入参数,在这种情况下我们把函数定义为 pure.
注:可能很难记住何时把函数标记为 pure/view。 幸运的是, Solidity 编辑器会给出提示,提醒你使用这些修饰符。
实战演习
我们想建立一个帮助函数,它根据一个字符串随机生成一个DNA数据。
- 创建一个
private函数,命名为_generateRandomDna。它只接收一个输入变量_str(类型string), 返回一个uint类型的数值。 - 此函数只读取我们合约中的一些变量,所以标记为
view。 - 函数内部暂时留空,以后我们再添加代码。
1 | pragma solidity ^0.4.19; |
第11章: Keccak256 和 类型转换
如何让 _generateRandomDna 函数返回一个全(半) 随机的 uint?
Ethereum 内部有一个散列函数keccak256,它用了SHA3版本。一个散列函数基本上就是把一个字符串转换为一个256位的16进制数字。字符串的一个微小变化会引起散列数据极大变化。
这在 Ethereum 中有很多应用,但是现在我们只是用它造一个伪随机数。
例子:
1 | //6e91ec6b618bb462a4a6ee5aa2cb0e9cf30f7a052bb467b0ba58b8748c00d2e5 |
显而易见,输入字符串只改变了一个字母,输出就已经天壤之别了。
注: 在区块链中安全地产生一个随机数是一个很难的问题, 本例的方法不安全,但是在我们的Zombie DNA算法里不是那么重要,已经很好地满足我们的需要了。
类型转换
有时你需要变换数据类型。例如:
1 | uint8 a = 5; |
上面, a * b 返回类型是 uint, 但是当我们尝试用 uint8 类型接收时, 就会造成潜在的错误。如果把它的数据类型转换为 uint8, 就可以了,编译器也不会出错。
实战演习
给 _generateRandomDna 函数添加代码! 它应该完成如下功能:
- 第一行代码取
_str的keccak256散列值生成一个伪随机十六进制数,类型转换为uint, 最后保存在类型为uint名为rand的变量中。 - 我们只想让我们的DNA的长度为16位 (还记得
dnaModulus?)。所以第二行代码应该return上面计算的数值对dnaModulus求余数(%)。
1 | pragma solidity ^0.4.19; |
第12章: 放在一起
我们就快完成我们的随机僵尸制造器了,来写一个公共的函数把所有的部件连接起来。
写一个公共函数,它有一个参数,用来接收僵尸的名字,之后用它生成僵尸的DNA。
实战演习
- 创建一个
public函数,命名为createRandomZombie. 它将被传入一个变量_name(数据类型是string)。 *(注: 定义公共函数public和定义一个私有private函数的做法一样)*。 - 函数的第一行应该调用
_generateRandomDna函数,传入_name参数, 结果保存在一个类型为uint的变量里,命名为randDna。 - 第二行调用
_createZombie函数, 传入参数:_name和randDna。 - 整个函数应该是4行代码 (包括函数的结束符号
})。
1 | pragma solidity ^0.4.19; |
第13章: 事件
我们的合约几乎就要完成了!让我们加上一个事件.
事件 是合约和区块链通讯的一种机制。你的前端应用“监听”某些事件,并做出反应。
例子:
1 | // 这里建立事件 |
你的 app 前端可以监听这个事件。JavaScript 实现如下:
1 | YourContract.IntegersAdded(function(error, result) { |
实战演习
我们想每当一个僵尸创造出来时,我们的前端都能监听到这个事件,并将它显示出来。
1。 定义一个 事件 叫做 NewZombie。 它有3个参数: zombieId (uint), name (string), 和 dna (uint)。
2。 修改 _createZombie 函数使得当新僵尸造出来并加入 zombies数组后,生成事件NewZombie。
3。 需要定义僵尸id。 array.push() 返回数组的长度类型是uint - 因为数组的第一个元素的索引是 0, array.push() - 1 将是我们加入的僵尸的索引。 zombies.push() - 1 就是 id,数据类型是 uint。在下一行中你可以把它用到 NewZombie 事件中。
1 | pragma solidity ^0.4.19; |
第14章: Web3.js
我们的 Solidity 合约完工了! 现在我们要写一段 JavaScript 前端代码来调用这个合约。
以太坊有一个 JavaScript 库,名为Web3.js。
在后面的课程里,我们会进一步地教你如何安装一个合约,如何设置Web3.js。 但是现在我们通过一段代码来了解 Web3.js 是如何和我们发布的合约交互的吧。
如果下面的代码你不能全都理解,不用担心。
1 | // 下面是调用合约的方式: |
我们的 JavaScript 所做的就是获取由zombieDetails 产生的数据, 并且利用浏览器里的 JavaScript 神奇功能 (我们用 Vue.js),置换出图像以及使用CSS过滤器。在后面的课程中,你可以看到全部的代码。
8月9日
| 今日学习内容 |
|---|
| 安全与合规 |
| Chainlink预言机的solidity课程 |
Chainlink预言机的solidity课程
solidity数据类型、函数、存储模式、数据结构
今天主要看了B站Chainlink预言机的solidity课程,然后跟着使用remix工具,进行简单的合约编写以及部署,学习到的包括数据结构、函数等内容,在昨天的CryptoZombiesx的课程中也都学过一遍,所以也就算是复习一遍了。
还有就是你觉得这个课程讲的真的很好,不仅讲解了密码学中包括公私钥加密原理,甚至还讲解了助记词产生过程以及助记词生成私钥的过程。强烈推荐!!
1 | // SPDX-License-Identifier: MIT |
SPDX-License-Identifier:明确声明其使用的开源许可证。它通常以注释的形式出现在文件头部,帮助开发者、法律团队和自动化工具快速识别代码的许可条款
view:函数中只有读取操作,没有修改操作
pure:函数中种只需要进行运算,不需要读取任何变量
四个可见度标识符:

存储模式:
永久性存储:storage
暂时性存储(交易结束后值就消失了):memory、calldata
1、storage:永久存在合约内,合约中声明的默认是该类型,但不需要显示写出该关键词
2、memory:变量在运行时可以更改
3、calldata:变量在运行时不能更改,例如函数传参,用calldata传参数,函数中该值是不能改变的
4、stack
5、codes
6、logs
数据结构:
1、struct:结构体
2、array:数组
3、mapping:映射(键值对表示)
solidity的工厂模式
工厂模式介绍
在 Solidity 中,工厂模式(Factory Pattern) 是一种常用的智能合约设计模式,用于 动态创建和管理其他合约的实例。工厂合约(Factory Contract)负责部署子合约(Child Contracts),通常用于以下场景:
- 批量创建相同逻辑的合约(如代币、NFT、多签钱包等)。
- 降低重复部署的成本(通过复用逻辑合约)。
- 统一管理子合约地址。
1 | contract Factory { |
引入合约方式
直接引入同一个文件系统下的合约
1 | import { HelloWorld } from "./test.sol"; |
也可以直接引入网上的URL以及可以精准写入sol文件中具体的合约名称
1 | import { HelloWorld } from "https://11111/test.sol"; |
在实际应用中,涉及到公司的内容,会有更专业的引入方式,通过引入包的方式
1 | import { HelloWorld } from "@companyName/product/contract"; |
8月10日
| 今日学习内容 |
|---|
| CryptoZombiesx的solidity学习/Solidity: Beginner to Intermediate Smart Contracts/lesson2 僵尸攻击人类 |
CryptoZombiesx的solidity学习
Solidity: Beginner to Intermediate Smart Contracts
lesson2 僵尸攻击人类
第2章: 映射(Mapping)和地址(Address)
我们通过给数据库中的僵尸指定“主人”, 来支持“多玩家”模式。
如此一来,我们需要引入2个新的数据类型:mapping(映射) 和 address(地址)。
Addresses (地址)
以太坊区块链由 _ account _ (账户)组成,你可以把它想象成银行账户。一个帐户的余额是 以太 (在以太坊区块链上使用的币种),你可以和其他帐户之间支付和接受以太币,就像你的银行帐户可以电汇资金到其他银行帐户一样。
每个帐户都有一个“地址”,你可以把它想象成银行账号。这是账户唯一的标识符,它看起来长这样:
1 | 0x0cE446255506E92DF41614C46F1d6df9Cc969183 |
(这是 CryptoZombies 团队的地址,如果你喜欢 CryptoZombies 的话,请打赏我们一些以太币!😉)
我们将在后面的课程中介绍地址的细节,现在你只需要了解地址属于特定用户(或智能合约)的。
所以我们可以指定“地址”作为僵尸主人的 ID。当用户通过与我们的应用程序交互来创建新的僵尸时,新僵尸的所有权被设置到调用者的以太坊地址下。
Mapping(映射)
在第1课中,我们看到了 结构体 和 数组 。 映射 是另一种在 Solidity 中存储有组织数据的方法。
映射是这样定义的:
1 | //对于金融应用程序,将用户的余额保存在一个 uint类型的变量中: |
映射本质上是存储和查找数据所用的键-值对。在第一个例子中,键是一个 address,值是一个 uint,在第二个例子中,键是一个uint,值是一个 string。
实战演习
为了存储僵尸的所有权,我们会使用到两个映射:一个记录僵尸拥有者的地址,另一个记录某地址所拥有僵尸的数量。
1.创建一个叫做 zombieToOwner 的映射。其键是一个uint(我们将根据它的 id 存储和查找僵尸),值为 address。映射属性为public。
2.创建一个名为 ownerZombieCount 的映射,其中键是 address,值是 uint。
1 | // 在这里定义映射 |
第3章: Msg.sender
现在有了一套映射来记录僵尸的所有权了,我们可以修改 _createZombie 方法来运用它们。
为了做到这一点,我们要用到 msg.sender。
msg.sender
在 Solidity 中,有一些全局变量可以被所有函数调用。 其中一个就是 msg.sender,它指的是当前调用者(或智能合约)的 address。
注意:在 Solidity 中,功能执行始终需要从外部调用者开始。 一个合约只会在区块链上什么也不做,除非有人调用其中的函数。所以
msg.sender总是存在的。
以下是使用 msg.sender 来更新 mapping 的例子:
1 | mapping (address => uint) favoriteNumber; |
在这个小小的例子中,任何人都可以调用 setMyNumber 在我们的合约中存下一个 uint 并且与他们的地址相绑定。 然后,他们调用 whatIsMyNumber 就会返回他们存储的 uint。
使用 msg.sender 很安全,因为它具有以太坊区块链的安全保障 —— 除非窃取与以太坊地址相关联的私钥,否则是没有办法修改其他人的数据的。
实战演习
我们来修改第1课的 _createZombie 方法,将僵尸分配给函数调用者吧。
- 首先,在得到新的僵尸
id后,更新zombieToOwner映射,在id下面存入msg.sender。 - 然后,我们为这个
msg.sender名下的ownerZombieCount加 1。
跟在 JavaScript 中一样, 在 Solidity 中你也可以用 ++ 使 uint 递增。
1 | uint number = 0; |
修改两行代码即可。
1 | function _createZombie(string _name, uint _dna) private { |
第4章: Require
在第一课中,我们成功让用户通过调用 createRandomZombie函数 并输入一个名字来创建新的僵尸。 但是,如果用户能持续调用这个函数来创建出无限多个僵尸加入他们的军团,这游戏就太没意思了!
于是,我们作出限定:每个玩家只能调用一次这个函数。 这样一来,新玩家可以在刚开始玩游戏时通过调用它,为其军团创建初始僵尸。
我们怎样才能限定每个玩家只调用一次这个函数呢?
答案是使用require。 require使得函数在执行过程中,当不满足某些条件时抛出错误,并停止执行:
1 | function sayHiToVitalik(string _name) public returns (string) { |
如果你这样调用函数 sayHiToVitalik(“Vitalik”) ,它会返回“Hi!”。而如果调用的时候使用了其他参数,它则会抛出错误并停止执行。
因此,在调用一个函数之前,用 require 验证前置条件是非常有必要的。
实战演习
在我们的僵尸游戏中,我们不希望用户通过反复调用 createRandomZombie 来給他们的军队创建无限多个僵尸 —— 这将使得游戏非常无聊。
我们使用了 require 来确保这个函数只有在每个用户第一次调用它的时候执行,用以创建初始僵尸。
- 在
createRandomZombie的前面放置require语句。 使得函数先检查ownerZombieCount [msg.sender]的值为0,不然就抛出一个错误。
注意:在 Solidity 中,关键词放置的顺序并不重要
- 虽然参数的两个位置是等效的。 但是,由于我们的答案检查器比较呆板,它只能认定其中一个为正确答案
- 于是在这里,我们就约定把
ownerZombieCount [msg.sender]放前面吧
1 | function createRandomZombie(string _name) public { |
第5章: 继承(Inheritance)
我们的游戏代码越来越长。 当代码过于冗长的时候,最好将代码和逻辑分拆到多个不同的合约中,以便于管理。
有个让 Solidity 的代码易于管理的功能,就是合约 *inheritance* (继承):
1 | contract Doge { |
由于 BabyDoge 是从 Doge 那里 *inherits* (继承)过来的。 这意味着当你编译和部署了 BabyDoge,它将可以访问 catchphrase() 和 anotherCatchphrase()和其他我们在 Doge 中定义的其他公共函数。
这可以用于逻辑继承(比如表达子类的时候,Cat 是一种 Animal)。 但也可以简单地将类似的逻辑组合到不同的合约中以组织代码。
实战演习
在接下来的章节中,我们将要为僵尸实现各种功能,让它可以“猎食”和“繁殖”。 通过将这些运算放到父类 ZombieFactory 中,使得所有 ZombieFactory 的继承者合约都可以使用这些方法。
- 在
ZombieFactory下创建一个叫ZombieFeeding的合约,它是继承自 `ZombieFactory 合约的。
1 | // Start here |
第6章: 引入(Import)
哇!你有没有注意到,我们只是清理了下右边的代码,现在你的编辑器的顶部就多了个选项卡。 尝试点击它的标签,看看会发生什么吧!
代码已经够长了,我们把它分成多个文件以便于管理。 通常情况下,当 Solidity 项目中的代码太长的时候我们就是这么做的。
在 Solidity 中,当你有多个文件并且想把一个文件导入另一个文件时,可以使用 import 语句:
1 | import "./someothercontract.sol"; |
这样当我们在合约(contract)目录下有一个名为 someothercontract.sol 的文件( ./ 就是同一目录的意思),它就会被编译器导入。
实战演习
现在我们已经建立了一个多文件架构,并用 import 来读取来自另一个文件中合约的内容:
1.将 zombiefactory.sol 导入到我们的新文件 zombiefeeding.sol 中。
1 | // put import statement here |
第7章: Storage与Memory
在 Solidity 中,有两个地方可以存储变量 —— storage 或 memory。
Storage 变量是指**永久存储在区块链中的变量。 Memory 变量则是临时的**,当外部函数对某合约调用完成时,内存型变量即被移除。 你可以把它想象成存储在你电脑的硬盘或是RAM中数据的关系。
大多数时候你都用不到这些关键字,默认情况下 Solidity 会自动处理它们。 状态变量(在函数之外声明的变量)默认为“存储”形式,并永久写入区块链;而在函数内部声明的变量是“内存”型的,它们函数调用结束后消失。
然而也有一些情况下,你需要手动声明存储类型,主要用于处理函数内的 结构体 和 数组 时:
1 | contract SandwichFactory { |
如果你还没有完全理解究竟应该使用哪一个,也不用担心 —— 在本教程中,我们将告诉你何时使用 storage 或是 memory,并且当你不得不使用到这些关键字的时候,Solidity 编译器也发警示提醒你的。
现在,只要知道在某些场合下也需要你显式地声明 storage 或 memory就够了!
实战演习
是时候给我们的僵尸增加“猎食”和“繁殖”功能了!
当一个僵尸猎食其他生物体时,它自身的DNA将与猎物生物的DNA结合在一起,形成一个新的僵尸DNA。
- 创建一个名为
feedAndMultiply的函数。 使用两个参数:_zombieId(uint类型 )和_targetDna(也是uint类型)。 设置属性为public的。 - 我们不希望别人用我们的僵尸去捕猎。 首先,我们确保对自己僵尸的所有权。 通过添加一个
require语句来确保msg.sender只能是这个僵尸的主人(类似于我们在createRandomZombie函数中做过的那样)。
注意:同样,因为我们的答案检查器比较呆萌,只认识把
msg.sender放在前面的答案,如果你切换了参数的顺序,它就不认得了。 但你正常编码时,如何安排参数顺序都是正确的。
- 为了获取这个僵尸的DNA,我们的函数需要声明一个名为
myZombie数据类型为Zombie的本地变量(这是一个storage型的指针)。 将其值设定为在zombies数组中索引为_zombieId所指向的值。
到目前为止,包括函数结束符 } 的那一行, 总共4行代码。
1 | // Start here |
第8章: 僵尸的DNA
我们来把 feedAndMultiply 函数写完吧。
获取新的僵尸DNA的公式很简单:计算猎食僵尸DNA和被猎僵尸DNA之间的平均值。
例如:
1 | function testDnaSplicing() public { |
以后,我们也可以让函数变得更复杂些,比方给新的僵尸的 DNA 增加一些随机性之类的。但现在先从最简单的开始 —— 以后还可以回来完善它嘛。
实战演习
- 首先我们确保
_targetDna不长于16位。要做到这一点,我们可以设置_targetDna为_targetDna % dnaModulus,并且只取其最后16位数字。 - 接下来为我们的函数声明一个名叫
newDna的uint类型的变量,并将其值设置为myZombie的 DNA 和_targetDna的平均值(如上例所示)。
注意:您可以用
myZombie.name或myZombie.dna访问myZombie的属性。
- 一旦我们计算出新的DNA,再调用
_createZombie就可以生成新的僵尸了。如果你忘了调用这个函数所需要的参数,可以查看zombiefactory.sol选项卡。请注意,需要先给它命名,所以现在我们把新的僵尸的名字设为NoName- 我们回头可以编写一个函数来更改僵尸的名字。
注意:对于 Solidity 高手,你可能会注意到我们的代码存在一个问题。别担心,下一章会解决这个问题的 ;)
1 | function feedAndMultiply(uint _zombieId, uint _targetDna) public { |
第9章: 更多关于函数可见性
我们上一课的代码有问题!
编译的时候编译器就会报错。
错误在于,我们尝试从 ZombieFeeding 中调用 _createZombie 函数,但 _createZombie 却是 ZombieFactory 的 private (私有)函数。这意味着任何继承自 ZombieFactory 的子合约都不能访问它。
internal 和 external
除 public 和 private 属性之外,Solidity 还使用了另外两个描述函数可见性的修饰词:internal(内部) 和 external(外部)。
internal 和 private 类似,不过, 如果某个合约继承自其父合约,这个合约即可以访问父合约中定义的“内部”函数。(嘿,这听起来正是我们想要的那样!)。
external 与public 类似,只不过这些函数只能在合约之外调用 - 它们不能被合约内的其他函数调用。稍后我们将讨论什么时候使用 external 和 public。
声明函数 internal 或 external 类型的语法,与声明 private 和 public类 型相同:
1 | contract Sandwich { |
实战演习
将
_createZombie()函数的属性从private改为internal, 使得其他的合约也能访问到它。我们已经成功把你的注意力集中在到
zombiefactory.sol这个选项卡上啦。
1 | // 在这里修改函数的功能 |
第10章: 僵尸吃什么?
是时候让我们的僵尸去捕猎! 那僵尸最喜欢的食物是什么呢?
Crypto 僵尸喜欢吃的是…
CryptoKitties! 😱😱😱
(正经点,我可不是开玩笑😆)
为了做到这一点,我们要读出 CryptoKitties 智能合约中的 kittyDna。这些数据是公开存储在区块链上的。区块链是不是很酷?
别担心 —— 我们的游戏并不会伤害到任何真正的CryptoKitty。 我们只 读取 CryptoKitties 数据,但却无法在物理上删除它。
与其他合约的交互
如果我们的合约需要和区块链上的其他的合约会话,则需先定义一个 interface (接口)。
先举一个简单的栗子。 假设在区块链上有这么一个合约:
1 | contract LuckyNumber { |
这是个很简单的合约,您可以用它存储自己的幸运号码,并将其与您的以太坊地址关联。 这样其他人就可以通过您的地址查找您的幸运号码了。
现在假设我们有一个外部合约,使用 getNum 函数可读取其中的数据。
首先,我们定义 LuckyNumber 合约的 interface :
1 | contract NumberInterface { |
请注意,这个过程虽然看起来像在定义一个合约,但其实内里不同:
首先,我们只声明了要与之交互的函数 —— 在本例中为 getNum —— 在其中我们没有使用到任何其他的函数或状态变量。
其次,我们并没有使用大括号({ 和 })定义函数体,我们单单用分号(;)结束了函数声明。这使它看起来像一个合约框架。
编译器就是靠这些特征认出它是一个接口的。
在我们的 app 代码中使用这个接口,合约就知道其他合约的函数是怎样的,应该如何调用,以及可期待什么类型的返回值。
在下一课中,我们将真正调用其他合约的函数。目前我们只要声明一个接口,用于调用 CryptoKitties 合约就行了。
实战演习
我们已经为你查看过了 CryptoKitties 的源代码,并且找到了一个名为 getKitty的函数,它返回所有的加密猫的数据,包括它的“基因”(我们的僵尸游戏要用它生成新的僵尸)。
该函数如下所示:
1 | function getKitty(uint256 _id) external view returns ( |
这个函数看起来跟我们习惯的函数不太一样。 它竟然返回了…一堆不同的值! 如果您用过 JavaScript 之类的编程语言,一定会感到奇怪 —— 在 Solidity中,您可以让一个函数返回多个值。
现在我们知道这个函数长什么样的了,就可以用它来创建一个接口:
1.定义一个名为 KittyInterface 的接口。 请注意,因为我们使用了 contract 关键字, 这过程看起来就像创建一个新的合约一样。
2.在interface里定义了 getKitty 函数(不过是复制/粘贴上面的函数,但在 returns 语句之后用分号,而不是大括号内的所有内容。
1 | // Create KittyInterface here |
第11章: 使用接口
继续前面 NumberInterface 的例子,我们既然将接口定义为:
1 | contract NumberInterface { |
我们可以在合约中这样使用:
1 | contract MyContract { |
通过这种方式,只要将您合约的可见性设置为public(公共)或external(外部),它们就可以与以太坊区块链上的任何其他合约进行交互。
实战演习
我们来建个自己的合约去读取另一个智能合约– CryptoKitties 的内容吧!
- 我已经将代码中 CryptoKitties 合约的地址保存在一个名为
ckAddress的变量中。在下一行中,请创建一个名为kittyContract的 KittyInterface,并用ckAddress为它初始化 —— 就像我们为numberContract所做的一样。
1 | contract ZombieFeeding is ZombieFactory { |
第12章: 处理多返回值
getKitty 是我们所看到的第一个返回多个值的函数。我们来看看是如何处理的:
1 | function multipleReturns() internal returns(uint a, uint b, uint c) { |
实战演习
是时候与 CryptoKitties 合约交互起来了!
我们来定义一个函数,从 kitty 合约中获取它的基因:
创建一个名为
feedOnKitty的函数。它需要2个uint类型的参数,_zombieId和_kittyId,这是一个public类型的函数。函数首先要声明一个名为
kittyDna的uint。注意:在我们的
KittyInterface中,genes是一个uint256类型的变量,但是如果你记得,我们在第一课中提到过,uint是uint256的别名,也就是说它们是一回事。这个函数接下来调用
kittyContract.getKitty函数, 传入_kittyId,将返回的genes存储在kittyDna中。记住 ——getKitty会返回一大堆变量。 (确切地说10个 - 我已经为你数过了,不错吧!)。但是我们只关心最后一个–genes。数逗号的时候小心点哦!最后,函数调用了
feedAndMultiply,并传入了_zombieId和kittyDna两个参数。
1 | // define function here |
第13章: 奖励: Kitty 基因
我们的功能逻辑主体已经完成了…现在让我们来添一个奖励功能吧。
这样吧,给从小猫制造出的僵尸添加些特征,以显示他们是猫僵尸。
要做到这一点,咱们在新僵尸的DNA中添加一些特殊的小猫代码。
还记得吗,第一课中我们提到,我们目前只使用16位DNA的前12位数来指定僵尸的外观。所以现在我们可以使用最后2个数字来处理“特殊”的特征。
这样吧,把猫僵尸DNA的最后两个数字设定为99(因为猫有9条命)。所以在我们这么来写代码:如果这个僵尸是一只猫变来的,就将它DNA的最后两位数字设置为99。
if 语句
if语句的语法在 Solidity 中,与在 JavaScript 中差不多:
1 | function eatBLT(string sandwich) public { |
实战演习
让我们在我们的僵尸代码中实现小猫的基因。
首先,我们修改下
feedAndMultiply函数的定义,给它传入第三个参数:一条名为_species的字符串。接下来,在我们计算出新的僵尸的DNA之后,添加一个
if语句来比较_species和字符串"kitty"的keccak256哈希值。在
if语句中,我们用99替换了新僵尸DNA的最后两位数字。可以这么做:newDna = newDna - newDna % 100 + 99;。解释:假设
newDna是334455。那么newDna % 100是55,所以newDna - newDna % 100得到334400。最后加上99可得到334499。最后,我们修改了
feedOnKitty中的函数调用。当它调用feedAndMultiply时,增加“kitty”作为最后一个参数。
1 | // 这里修改函数定义 |
第14章: 放在一起
至此,你已经学完第二课了!
查看下→_→的演示,看看他们怎么运行起来得吧。继续,你肯定等不及看完这一页😉。点击小猫,攻击!看到你斩获一个新的小猫僵尸了吧!
JavaScript 实现
我们只用编译和部署 ZombieFeeding,就可以将这个合约部署到以太坊了。我们最终完成的这个合约继承自 ZombieFactory,因此它可以访问自己和父辈合约中的所有 public 方法。
我们来看一个与我们的刚部署的合约进行交互的例子, 这个例子使用了 JavaScript 和 web3.js:
1 | var abi = /* abi generated by the compiler */ |
实战演习
选择一只你想猎食的小猫。你自家僵尸的 DNA 会和小猫的 DNA 结合,生成一个新的小猫僵尸,加入你的军团!
看到新僵尸上那可爱的猫咪腿了么?这是新僵尸最后DNA中最后两位数字 99 的功劳!
你想要的话随时可以重新开始。捕获了一只猫咪僵尸,你一定很高兴吧!(不过你只能持有一只),继续前进到下一章,完成第二课吧!
8月11日
| 今日学习内容 |
|---|
| Chainlink预言机的solidity进阶课程部分内容 |
| 智能合约开发部分内容 |
Chainlink预言机的solidity进阶课程
预言机网络(Chainlink)
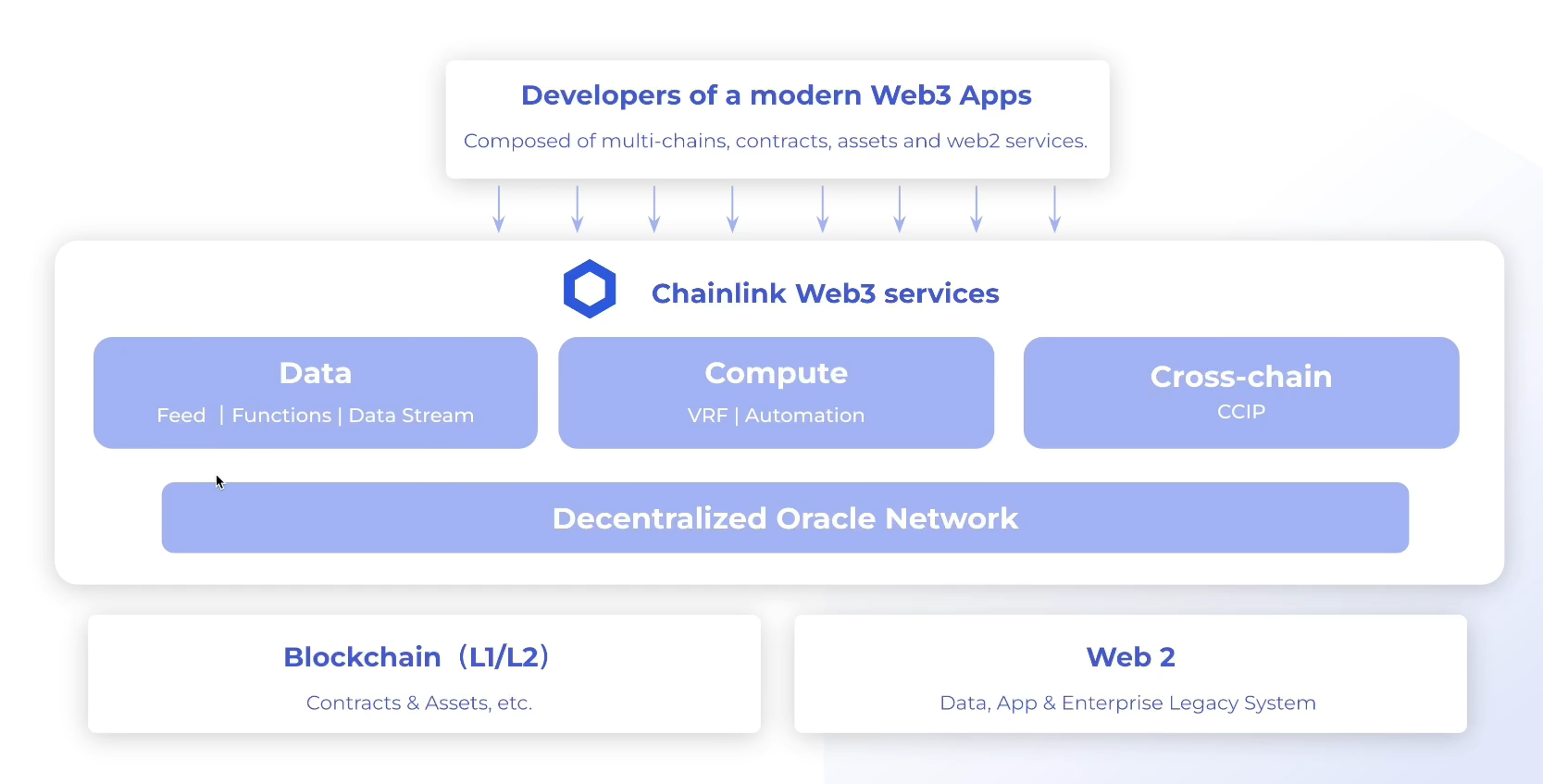
Chainlink 是一个 去中心化的预言机网络(Decentralized Oracle Network),主要解决区块链无法直接获取外部数据的问题。图中展示的是其如何为 现代Web3应用 提供多链、多服务的支持。
(1)Chainlink Web3 服务
| 服务类型 | 功能 | 具体产品 |
|---|---|---|
| Data | 提供链外数据(如价格、天气等) | • Feeds(价格预言机) • Functions(链上请求API) • Data Stream(实时数据流) |
| Compute | 提供可验证的随机数和自动化执行 | • VRF(可验证随机数) • Automation(智能合约自动化) |
| Cross-chain | 跨链通信和数据传输 | CCIP(跨链互操作协议) |
(2)连接对象
- 区块链(Blockchain):支持多链(图中标注 1.1/1.2 可能指不同链版本或主网/测试网)。
- 合约与资产(Contracts & Assets):如DeFi协议、NFT项目等。
- Web2系统:传统企业数据、API服务和遗留系统(如银行支付网关)。
喂价(Data Feed)
Data Feed 架构
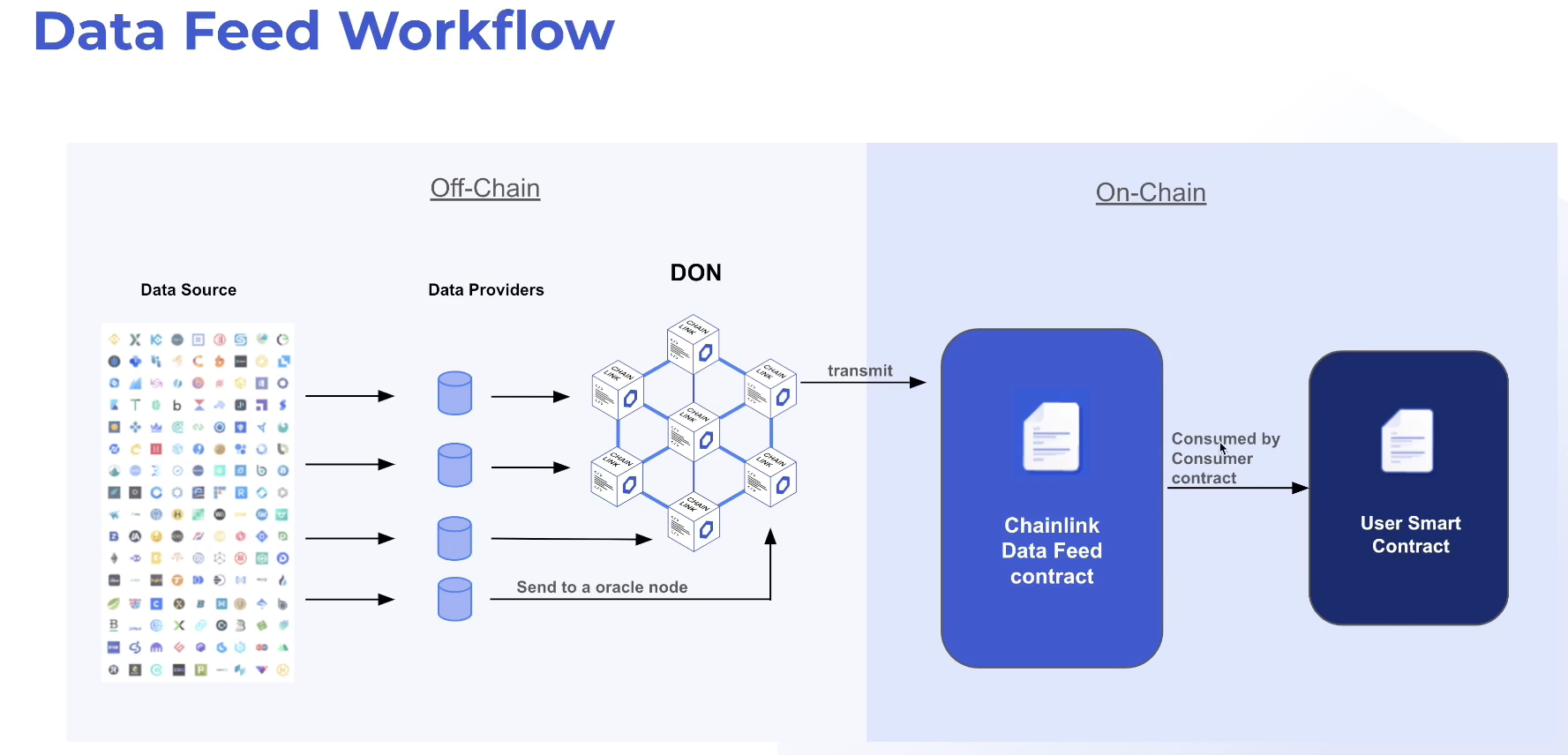
DON:去中心化的预言机网络
DON从数据提供商那里获取数据,将数据在DON网络中进行一次聚合,聚合之后将数据写入链上所部署的ChainLink Data Feed 合约中,用户合约可以通过Data Feed 合约的地址进行调用,从而获取到当前代币的价格
Data Feed 结构
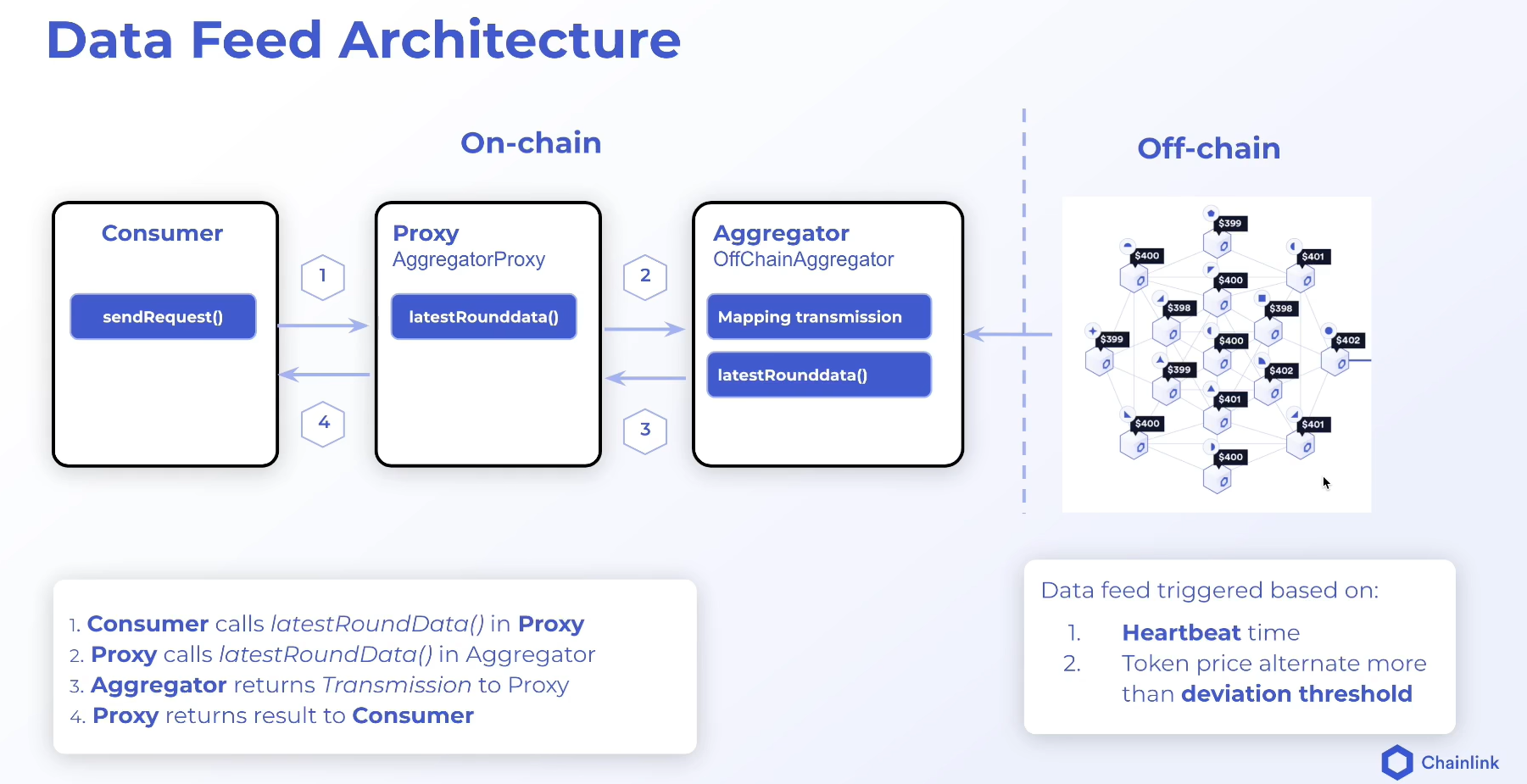
Aggregator:聚合合约,用于收集链下的数据,将其存入到transmission中
通过查看chainlink文档中,Data Feed合约内容,用户可以通过调用合约中的getChainlinkDataFeedLatestAnswer函数来获取代币实时数据,合约会返回一个answer值,就是链下代币值。
部署一个FundMe的智能合约
需求:
- 创建一个收款函数
- 记录投资人并且查看
- 在锁定期内,达到目标值,生产商可以提款
- 在锁定期内,未达到目标值,投资人可以退款
1 | // SPDX-License-Identifier: MIT |
payable:要有这个参数才能执行收款
创建一个构造函数,去chainlink中找到价格信息来源地址
1 | constructor(){ |
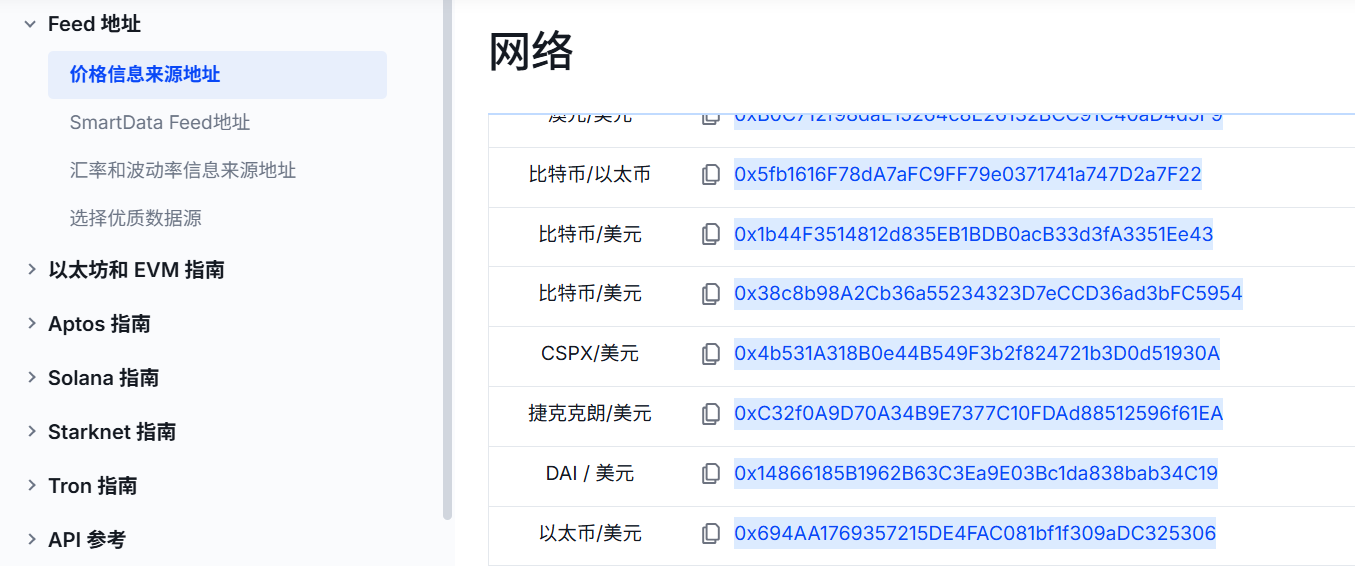
写一个新的函数用于转换ETH和USD
1 | function fund() external payable { |
注意:getChainlinkDataFeedLatestAnswer()获得的值是一个int类型的,需要强制转换为uint256类型
转账的三种类型
- transfer:失败则直接回退
1 | 结构:addr.transfer(value) |
| 代码片段 | 作用 |
|---|---|
address(this).balance |
获取当前合约地址持有的 ETH 余额(单位:wei,1 ETH = 10¹⁸ wei) |
payable(msg.sender) |
将调用者地址转换为可接收 ETH 的 payable 类型 |
.transfer(...) |
向目标地址发送 ETH(自动处理 wei 单位,失败时回滚交易) |
- send:失败返回false布尔值
1 | 结构:addr.send(value) |
- call:可以在转账的同时带上数据,返回函数返回值以及布尔值
1 | 结构:(bool ,result) = addr.call{value: value}("") |
提款
1 | function refund() external { |
这个函数存在一个bug,就是一个人将自己的存款提出后,未对该账户进行清零,导致这个人可以继续refund,提取别人的存款
改进,加一句提款后清零账户,fundersToAmount[msg.sender] = 0
1 | function refund() external { |
时间锁
1 | uint256 deploymentTimestamp; //合约部署时候的时间戳(针对于1970年1月1日算起) |
在solidity中没有专门的时间类型,使用整形数据类型。
修改构造函数,初始化时间戳和需要锁定时间
1 | constructor(uint256 _lockTime){ |
更改fund函数
1 | function fund() external payable { |
更改getfund函数
1 | function getFund() external { |
更改refund函数,更改处于getfund相同
1 | function refund() external windowClose { |
modifier修改器
统一处理require函数
1 | modifier windowClose(){ |
如果_;在前面
1 | modifier windowClose(){ |
智能合约开发
Dapp 架构和开发流程
Dapp:去中心化应用,运行在区块链或分布式网络上,应用的逻辑和数据是由多个参与者共同维护。
Dapp 架构
三个核心部分:
- 前端(User Interface):
- 前端是 Dapp 与用户交互的界面,通常由 HTML、CSS 和 JavaScript(如 React、Vue 等框架)构建。与传统 Web 应用不同,Dapp 前端会连接区块链来调用智能合约,呈现数据和执行交易。
- 前端还需要集成区块链钱包(如 MetaMask)来进行身份验证和签署交易,确保用户的隐私和安全。
- 智能合约(Smart Contracts):
- 智能合约是 Dapp 的核心,它定义了应用的业务逻辑,并部署在区块链上。智能合约通过执行自动化的规则来确保交易和操作的透明性与不可篡改性。
- 在以太坊平台上,智能合约通常使用 Solidity 编程语言编写,并通过 Ethereum Virtual Machine (EVM) 执行。
- 数据检索器(Indexer):
- 智能合约通常以
Event形式释放日志事件,比如释放代表 NFT 转移的Transfer事件,数据检索器会检索这些数据并将其写入到 PostgreSQL 等传统数据库中 - Dapp 在前端进行数据展示时需要检索器内的数据。一个简单的示例是某 NFT 项目需要展示用户持有的所有 NFT,但是 NFT 合约并不会提供通过输入地址参数返回该地址下的所有 NFT 的函数,此时我们可以运行数据检索器将
Transfer事件读取后写入传统数据库内,前端可以在传统数据库内检索用户持有的 NFT 数据
- 区块链和去中心化存储(Blockchain & Decentralized Storage):
- 区块链用于存储智能合约的状态数据及交易记录。去中心化存储如 IPFS(InterPlanetary File System)或 Arweave,用于存储大规模的非结构化数据(如图片、文档等),确保数据不易丢失和篡改。
- 通过使用去中心化存储,Dapp 确保所有数据在多个节点上备份,保证数据的持久性和去中心化特性。
Dapp 开发流程
需求分析与规划
在开发 Dapp 之前,首先需要进行需求分析和规划,明确应用的目标和功能。此阶段包括:
- 确定功能需求:需要定义用户可以进行的操作,比如转账、查询余额、创建投票等。
- 选择区块链平台:决定在哪个平台上构建 Dapp(如以太坊、Solana、Polygon 等),这通常取决于目标用户群、交易成本、可扩展性等因素。
- 设计用户体验(UX):定义 Dapp 的界面设计和交互流程,确保用户能够轻松使用应用并与区块链交互。
智能合约开发
智能合约是 Dapp 的核心,负责执行去中心化的业务逻辑和存储重要的数据。在这一阶段,开发者需要:
- 编写智能合约:使用 Solidity 或其他智能合约语言编写合约,确保合约的功能满足需求分析中定义的要求。
- 编写测试用例:为智能合约编写单元测试,确保合约逻辑正确、无漏洞。
- 审计和优化:对合约进行安全审计,确保合约的安全性,避免常见漏洞(如重入攻击、整数溢出等)。
检索器开发
检索器是获取链上数据的核心,负责捕获智能合约释放的事件并以合理的方式将其存入数据库的不同的表内部。在这一阶段,开发者需要:
- 确定功能需要的数据内容: 前端使用的数据大部份都直接来自检索器,所以开发者需要确定前端工程师所需要的数据
- 编写检索器程序: 目前主流的检索器框架,如 ponder 和 subgraph 都是用了 TypeScript 语言作为检索器的程序编写语言,开发者主要编写事件数据清理以及事件数据写入数据库的代码
- 部署和运维: 编写程序完成后,一般使用 Docker 部署到云服务器中,当然目前很多检索器框架也提供 SaaS 服务,同时检索器作为一个常规的数据库应用需要运维
前端开发
前端是用户与 Dapp 交互的主要界面,因此开发前端时需要:
- 选择前端框架:可以使用现代前端框架(如 React、Vue)来构建 UI。前端将通过 JavaScript 与智能合约进行交互。
- 连接钱包:通过集成 MetaMask 等 Web3 钱包,用户可以连接到 Dapp,并授权其与智能合约交互。
- 显示区块链数据:前端需要从区块链和检索器内获取数据(如账户余额、交易记录),并通过用户界面展示。
- 处理交易签名与确认:当用户发起交易时,前端需要与钱包进行交互,获取用户的签名并将交易发送到区块链。
与区块链交互
前端和智能合约通过 Viem(推荐)、Ethers.js 或 Wagmi 等现代化库进行交互。这些库提供更好的 TypeScript 支持和性能优化:
- 读取数据:前端通过智能合约的公共函数读取区块链上的状态数据(如余额、合约信息)。
- 发送交易:当用户发起交易时,前端需要通过钱包签署交易并发送到区块链,执行合约中的某个功能(如转账)。
部署与上线
一旦开发完成,Dapp 进入部署阶段。具体步骤包括:
- 部署智能合约:推荐使用 Hardhat 或 Foundry(现代化开发工具)将智能合约部署到测试网(如 Sepolia、Holesky)或主网。
- 前端部署:将前端应用部署到去中心化平台(如 IPFS)或传统的 Web 服务(Vercel)。
- 发布和维护:将 Dapp 上线,进行用户反馈收集,定期更新合约和前端,修复潜在问题。
8月12日
| 今日学习内容 |
|---|
| CryptoZombiesx的solidity学习\Solidity: Beginner to Intermediate Smart Contracts\lesson3 高级 Solidity 理论 |
| CryptoZombiesx的solidity学习\Solidity: Beginner to Intermediate Smart Contracts\lesson4 僵尸作战系统 |
| CryptoZombiesx的solidity学习\Solidity: Beginner to Intermediate Smart Contracts\lesson5 ERC721 标准和加密收藏品 |
| openzeppelin攻防挑战前三关 |
CryptoZombiesx的solidity学习
Solidity: Beginner to Intermediate Smart Contracts
lesson3 高级 Solidity 理论
第1章: 智能协议的永固性
到现在为止,我们讲的 Solidity 和其他语言没有质的区别,它长得也很像 JavaScript。
但是,在有几点以太坊上的 DApp 跟普通的应用程序有着天壤之别。
第一个例子,在你把智能协议传上以太坊之后,它就变得不可更改, 这种永固性意味着你的代码永远不能被调整或更新。
你编译的程序会一直,永久的,不可更改的,存在以太坊上。这就是 Solidity 代码的安全性如此重要的一个原因。如果你的智能协议有任何漏洞,即使你发现了也无法补救。你只能让你的用户们放弃这个智能协议,然后转移到一个新的修复后的合约上。
但这恰好也是智能合约的一大优势。代码说明一切。如果你去读智能合约的代码,并验证它,你会发现,一旦函数被定义下来,每一次的运行,程序都会严格遵照函数中原有的代码逻辑一丝不苟地执行,完全不用担心函数被人篡改而得到意外的结果。
外部依赖关系
在第2课中,我们将加密小猫(CryptoKitties)合约的地址硬编码到 DApp 中去了。有没有想过,如果加密小猫出了点问题,比方说,集体消失了会怎么样? 虽然这种事情几乎不可能发生,但是,如果小猫没了,我们的 DApp 也会随之失效 – 因为我们在 DApp 的代码中用“硬编码”的方式指定了加密小猫的地址,如果这个根据地址找不到小猫,我们的僵尸也就吃不到小猫了,而按照前面的描述,我们却没法修改合约去应付这个变化!
因此,我们不能硬编码,而要采用“函数”,以便于 DApp 的关键部分可以以参数形式修改。
比方说,我们不再一开始就把猎物地址给写入代码,而是写个函数 setKittyContractAddress, 运行时再设定猎物的地址,这样我们就可以随时去锁定新的猎物,也不用担心加密小猫集体消失了。
实战演习
请修改第2课的代码,使得可以通过程序更改 CryptoKitties 合约地址。
- 删除采用硬编码 方式的
ckAddress代码行。 - 之前创建
kittyContract变量的那行代码,修改为对kittyContract变量的声明 – 暂时不给它指定具体的实例。 - 创建名为
setKittyContractAddress的函数, 它带一个参数_address(address类型), 可见性设为external。 - 在函数内部,添加一行代码,将
kittyContract变量设置为返回值:KittyInterface(_address)。
注意:你可能会注意到这个功能有个安全漏洞,别担心 - 咱们到下一章里解决它;)
1 | contract ZombieFeeding is ZombieFactory { |
第2章: Ownable Contracts
上一章中,您有没有发现任何安全漏洞呢?
呀!setKittyContractAddress 可见性居然申明为“外部的”(external),岂不是任何人都可以调用它! 也就是说,任何调用该函数的人都可以更改 CryptoKitties 合约的地址,使得其他人都没法再运行我们的程序了。
我们确实是希望这个地址能够在合约中修改,但我可没说让每个人去改它呀。
要对付这样的情况,通常的做法是指定合约的“所有权” - 就是说,给它指定一个主人(没错,就是您),只有主人对它享有特权。
OpenZeppelin库的Ownable 合约
下面是一个 Ownable 合约的例子: 来自 _ OpenZeppelin _ Solidity 库的 Ownable 合约。 OpenZeppelin 是主打安保和社区审查的智能合约库,您可以在自己的 DApps中引用。等把这一课学完,您不要催我们发布下一课,最好利用这个时间把 OpenZeppelin 的网站看看,保管您会学到很多东西!
把楼下这个合约读读通,是不是还有些没见过代码?别担心,我们随后会解释。
1 | /** |
下面有没有您没学过的东东?
- 构造函数:
function Ownable()是一个 _ constructor_ (构造函数),构造函数不是必须的,它与合约同名,构造函数一生中唯一的一次执行,就是在合约最初被创建的时候。 - 函数修饰符:
modifier onlyOwner()。 修饰符跟函数很类似,不过是用来修饰其他已有函数用的, 在其他语句执行前,为它检查下先验条件。 在这个例子中,我们就可以写个修饰符onlyOwner检查下调用者,确保只有合约的主人才能运行本函数。我们下一章中会详细讲述修饰符,以及那个奇怪的_;。 indexed关键字:别担心,我们还用不到它。
所以Ownable 合约基本都会这么干:
- 合约创建,构造函数先行,将其
owner设置为msg.sender(其部署者) - 为它加上一个修饰符
onlyOwner,它会限制陌生人的访问,将访问某些函数的权限锁定在owner上。 - 允许将合约所有权转让给他人。
onlyOwner 简直人见人爱,大多数人开发自己的 Solidity DApps,都是从复制/粘贴 Ownable 开始的,从它再继承出的子类,并在之上进行功能开发。
既然我们想把 setKittyContractAddress 限制为 onlyOwner ,我们也要做同样的事情。
实战演习
首先,将 Ownable 合约的代码复制一份到新文件 ownable.sol 中。 接下来,创建一个 ZombieFactory,继承 Ownable。
1.在程序中导入 ownable.sol 的内容。 如果您不记得怎么做了,参考下 zombiefeeding.sol。
2.修改 ZombieFactory 合约, 让它继承自 Ownable。 如果您不记得怎么做了,看看 zombiefeeding.sol。
1 | // 1. 在这里导入 |
第3章: onlyOwner 函数修饰符
现在我们有了个基本版的合约 ZombieFactory 了,它继承自 Ownable 接口,我们也可以给 ZombieFeeding 加上 onlyOwner 函数修饰符。
这就是合约继承的工作原理。记得:
1 | ZombieFeeding 是个 ZombieFactory |
因此 ZombieFeeding 也是个 Ownable, 并可以通过 Ownable 接口访问父类中的函数/事件/修饰符。往后,ZombieFeeding 的继承者合约们同样也可以这么延续下去。
函数修饰符
函数修饰符看起来跟函数没什么不同,不过关键字modifier 告诉编译器,这是个modifier(修饰符),而不是个function(函数)。它不能像函数那样被直接调用,只能被添加到函数定义的末尾,用以改变函数的行为。
咱们仔细读读 onlyOwner:
1 | /** |
onlyOwner 函数修饰符是这么用的:
1 | contract MyContract is Ownable { |
注意 likeABoss 函数上的 onlyOwner 修饰符。 当你调用 likeABoss 时,首先执行 onlyOwner 中的代码, 执行到 onlyOwner 中的 _; 语句时,程序再返回并执行 likeABoss 中的代码。
可见,尽管函数修饰符也可以应用到各种场合,但最常见的还是放在函数执行之前添加快速的 require检查。
因为给函数添加了修饰符 onlyOwner,使得唯有合约的主人(也就是部署者)才能调用它。
注意:主人对合约享有的特权当然是正当的,不过也可能被恶意使用。比如,万一,主人添加了个后门,允许他偷走别人的僵尸呢?
所以非常重要的是,部署在以太坊上的 DApp,并不能保证它真正做到去中心,你需要阅读并理解它的源代码,才能防止其中没有被部署者恶意植入后门;作为开发人员,如何做到既要给自己留下修复 bug 的余地,又要尽量地放权给使用者,以便让他们放心你,从而愿意把数据放在你的 DApp 中,这确实需要个微妙的平衡。
实战演习
现在我们可以限制第三方对 setKittyContractAddress的访问,除了我们自己,谁都无法去修改它。
- 将
onlyOwner函数修饰符添加到setKittyContractAddress中。
1 | // 修改这个函数: |
第4章: Gas
厉害!现在我们懂了如何在禁止第三方修改我们的合约的同时,留个后门给咱们自己去修改。
让我们来看另一种使得 Solidity 编程语言与众不同的特征:
Gas - 驱动以太坊DApps的能源
在 Solidity 中,你的用户想要每次执行你的 DApp 都需要支付一定的 ***gas***,gas 可以用以太币购买,因此,用户每次跑 DApp 都得花费以太币。
一个 DApp 收取多少 gas 取决于功能逻辑的复杂程度。每个操作背后,都在计算完成这个操作所需要的计算资源,(比如,存储数据就比做个加法运算贵得多), 一次操作所需要花费的 *gas* 等于这个操作背后的所有运算花销的总和。
由于运行你的程序需要花费用户的真金白银,在以太坊中代码的编程语言,比其他任何编程语言都更强调优化。同样的功能,使用笨拙的代码开发的程序,比起经过精巧优化的代码来,运行花费更高,这显然会给成千上万的用户带来大量不必要的开销。
*为什么要用 gas* 来驱动?
以太坊就像一个巨大、缓慢、但非常安全的电脑。当你运行一个程序的时候,网络上的每一个节点都在进行相同的运算,以验证它的输出 —— 这就是所谓的“去中心化” 由于数以千计的节点同时在验证着每个功能的运行,这可以确保它的数据不会被被监控,或者被刻意修改。
可能会有用户用无限循环堵塞网络,抑或用密集运算来占用大量的网络资源,为了防止这种事情的发生,以太坊的创建者为以太坊上的资源制定了价格,想要在以太坊上运算或者存储,你需要先付费。
注意:如果你使用侧链,倒是不一定需要付费,比如咱们在 Loom Network 上构建的 CryptoZombies 就免费。你不会想要在以太坊主网上玩儿“魔兽世界”吧? - 所需要的 gas 可能会买到你破产。但是你可以找个算法理念不同的侧链来玩它。我们将在以后的课程中咱们会讨论到,什么样的 DApp 应该部署在太坊主链上,什么又最好放在侧链。
省 gas 的招数:结构封装 (Struct packing)
在第1课中,我们提到除了基本版的 uint 外,还有其他变种 uint:uint8,uint16,uint32等。
通常情况下我们不会考虑使用 uint 变种,因为无论如何定义 uint的大小,Solidity 为它保留256位的存储空间。例如,使用 uint8 而不是uint(uint256)不会为你节省任何 gas。
除非,把 uint 绑定到 struct 里面。
如果一个 struct 中有多个 uint,则尽可能使用较小的 uint, Solidity 会将这些 uint 打包在一起,从而占用较少的存储空间。例如:
1 | struct NormalStruct { |
所以,当 uint 定义在一个 struct 中的时候,尽量使用最小的整数子类型以节约空间。 **并且把同样类型的变量放一起**(即在 struct 中将把变量按照类型依次放置),这样 Solidity 可以将存储空间最小化。例如,有两个 struct:
1 | uint c; uint32 a; uint32 b;` 和 `uint32 a; uint c; uint32 b; |
前者比后者需要的gas更少,因为前者把uint32放一起了。
实战演习
在本课中,咱们给僵尸添2个新功能:level 和 readyTime - 后者是用来实现一个“冷却定时器”,以限制僵尸猎食的频率。
让我们回到 zombiefactory.sol。
- 为
Zombie结构体 添加两个属性:level(uint32)和readyTime(uint32)。因为希望同类型数据打成一个包,所以把它们放在结构体的末尾。
32位足以保存僵尸的级别和时间戳了,这样比起使用普通的uint(256位),可以更紧密地封装数据,从而为我们省点 gas。
1 | contract ZombieFactory is Ownable { |
第5章: 时间单位
level 属性表示僵尸的级别。以后,在我们创建的战斗系统中,打胜仗的僵尸会逐渐升级并获得更多的能力。
readyTime 稍微复杂点。我们希望增加一个“冷却周期”,表示僵尸在两次猎食或攻击之之间必须等待的时间。如果没有它,僵尸每天可能会攻击和繁殖1,000次,这样游戏就太简单了。
为了记录僵尸在下一次进击前需要等待的时间,我们使用了 Solidity 的时间单位。
时间单位
Solidity 使用自己的本地时间单位。
变量 now 将返回当前的unix时间戳(自1970年1月1日以来经过的秒数)。我写这句话时 unix 时间是 1515527488。
注意:Unix时间传统用一个32位的整数进行存储。这会导致“2038年”问题,当这个32位的unix时间戳不够用,产生溢出,使用这个时间的遗留系统就麻烦了。所以,如果我们想让我们的 DApp 跑够20年,我们可以使用64位整数表示时间,但为此我们的用户又得支付更多的 gas。真是个两难的设计啊!
Solidity 还包含秒(seconds),分钟(minutes),小时(hours),天(days),周(weeks) 和 年(years) 等时间单位。它们都会转换成对应的秒数放入 uint 中。所以 1分钟 就是 60,1小时是 3600(60秒×60分钟),1天是86400(24小时×60分钟×60秒),以此类推。
下面是一些使用时间单位的实用案例:
1 | uint lastUpdated; |
有了这些工具,我们可以为僵尸设定“冷静时间”功能。
实战演习
现在咱们给DApp添加一个“冷却周期”的设定,让僵尸两次攻击或捕猎之间必须等待 1天。
声明一个名为
cooldownTime的uint,并将其设置为1 days。(没错,”1 days“使用了复数, 否则通不过编译器)因为在上一章中我们给
Zombie结构体中添加level和readyTime两个参数,所以现在创建一个新的Zombie结构体时,需要修改_createZombie(),在其中把新旧参数都初始化一下。修改
zombies.push那一行, 添加加2个参数:1(表示当前的level)和uint32(now + cooldownTime)(现在+冷却时间,表示下次允许攻击的时间readyTime)。
注意:必须使用
uint32(...)进行强制类型转换,因为now返回类型uint256。所以我们需要明确将它转换成一个uint32类型的变量。
now + cooldownTime 将等于当前的unix时间戳(以秒为单位)加上”1天“里的秒数 - 这将等于从现在起1天后的unix时间戳。然后我们就比较,看看这个僵尸的 readyTime是否大于 now,以决定再次启用僵尸的时机有没有到来。
下一章中,我们将讨论如何通过 readyTime 来规范僵尸的行为。
1 | // 1. 在这里定义 `cooldownTime` |
第6章: 僵尸冷却
现在,Zombie 结构体中定义好了一个 readyTime 属性,让我们跳到 zombiefeeding.sol, 去实现一个”冷却周期定时器“。
按照以下步骤修改 feedAndMultiply:
- ”捕猎“行为会触发僵尸的”冷却周期“
- 僵尸在这段”冷却周期“结束前不可再捕猎小猫
这将限制僵尸,防止其无限制地捕猎小猫或者整天不停地繁殖。将来,当我们增加战斗功能时,我们同样用”冷却周期“限制僵尸之间打斗的频率。
首先,我们要定义一些辅助函数,设置并检查僵尸的 readyTime。
将结构体作为参数传入
由于结构体的存储指针可以以参数的方式传递给一个 private 或 internal 的函数,因此结构体可以在多个函数之间相互传递。
遵循这样的语法:
1 | function _doStuff(Zombie storage _zombie) internal { |
这样我们可以将某僵尸的引用直接传递给一个函数,而不用是通过参数传入僵尸ID后,函数再依据ID去查找。
实战演习
- 先定义一个
_triggerCooldown函数。它要求一个参数,_zombie,表示一某个僵尸的存储指针。这个函数可见性设置为internal。 - 在函数中,把
_zombie.readyTime设置为uint32(now + cooldownTime)。 - 接下来,创建一个名为
_isReady的函数。这个函数的参数也是名为_zombie的Zombie storage。这个功能只具有internal可见性,并返回一个bool值。 - 函数计算返回
(_zombie.readyTime <= now),值为true或false。这个功能的目的是判断下次允许猎食的时间是否已经到了。
1 | // 1. 在这里定义 `_triggerCooldown` 函数 |
第7章: 公有函数和安全性
现在来修改 feedAndMultiply ,实现冷却周期。
回顾一下这个函数,前一课上我们将其可见性设置为public。你必须仔细地检查所有声明为 public 和 external的函数,一个个排除用户滥用它们的可能,谨防安全漏洞。请记住,如果这些函数没有类似 onlyOwner 这样的函数修饰符,用户能利用各种可能的参数去调用它们。
检查完这个函数,用户就可以直接调用这个它,并传入他们所希望的 _targetDna 或 species 。打个游戏还得遵循这么多的规则,还能不能愉快地玩耍啊!
仔细观察,这个函数只需被 feedOnKitty() 调用,因此,想要防止漏洞,最简单的方法就是设其可见性为 internal。
实战演习
- 目前函数
feedAndMultiply可见性为public。我们将其改为internal以保障合约安全。因为我们不希望用户调用它的时候塞进一堆乱七八糟的 DNA。 feedAndMultiply过程需要参考cooldownTime。首先,在找到myZombie之后,添加一个require语句来检查_isReady()并将myZombie传递给它。这样用户必须等到僵尸的冷却周期结束后才能执行feedAndMultiply功能。- 在函数结束时,调用
_triggerCooldown(myZombie),标明捕猎行为触发了僵尸新的冷却周期。
1 | // 1. 使这个函数的可见性为 internal |
第8章: 进一步了解函数修饰符
相当不错!我们的僵尸现在有了“冷却定时器”功能。
接下来,我们将添加一些辅助方法。我们为您创建了一个名为 zombiehelper.sol 的新文件,并且将 zombiefeeding.sol 导入其中,这让我们的代码更整洁。
我们打算让僵尸在达到一定水平后,获得特殊能力。但是达到这个小目标,我们还需要学一学什么是“函数修饰符”。
带参数的函数修饰符
之前我们已经读过一个简单的函数修饰符了:onlyOwner。函数修饰符也可以带参数。例如:
1 | // 存储用户年龄的映射 |
看到了吧, olderThan 修饰符可以像函数一样接收参数,是“宿主”函数 driveCar 把参数传递给它的修饰符的。
来,我们自己生产一个修饰符,通过传入的level参数来限制僵尸使用某些特殊功能。
实战演习
- 在
ZombieHelper中,创建一个名为aboveLevel的modifier,它接收2个参数,_level(uint类型) 以及_zombieId(uint类型)。 - 运用函数逻辑确保僵尸
zombies[_zombieId].level大于或等于_level。 - 记住,修饰符的最后一行为
_;,表示修饰符调用结束后返回,并执行调用函数余下的部分。
1 | pragma solidity ^0.4.19; |
第9章: 僵尸修饰符
现在让我们设计一些使用 aboveLevel 修饰符的函数。
作为游戏,您得有一些措施激励玩家们去升级他们的僵尸:
- 2级以上的僵尸,玩家可给他们改名。
- 20级以上的僵尸,玩家能给他们定制的 DNA。
是实现这些功能的时候了。以下是上一课的示例代码,供参考:
1 | // 存储用户年龄的映射 |
实战演习
- 创建一个名为
changeName的函数。它接收2个参数:_zombieId(uint类型)以及_newName(string类型),可见性为external。它带有一个aboveLevel修饰符,调用的时候通过_level参数传入2, 当然,别忘了同时传_zombieId参数。 - 在这个函数中,首先我们用
require语句,验证msg.sender是否就是zombieToOwner [_zombieId]。 - 然后函数将
zombies[_zombieId] .name设置为_newName。 - 在
changeName下创建另一个名为changeDna的函数。它的定义和内容几乎和changeName相同,不过它第二个参数是_newDna(uint类型),在修饰符aboveLevel的_level参数中传递20。现在,他可以把僵尸的dna设置为_newDna了。
1 | // 在这里开始 |
第10章: 利用 ‘View’ 函数节省 Gas
酷炫!现在高级别僵尸可以拥有特殊技能了,这一定会鼓动我们的玩家去打怪升级的。你喜欢的话,回头我们还能添加更多的特殊技能。
现在需要添加的一个功能是:我们的 DApp 需要一个方法来查看某玩家的整个僵尸军团 - 我们称之为 getZombiesByOwner。
实现这个功能只需从区块链中读取数据,所以它可以是一个 view 函数。这让我们不得不回顾一下“gas优化”这个重要话题。
“view” 函数不花 “gas”
当玩家从外部调用一个view函数,是不需要支付一分 gas 的。
这是因为 view 函数不会真正改变区块链上的任何数据 - 它们只是读取。因此用 view 标记一个函数,意味着告诉 web3.js,运行这个函数只需要查询你的本地以太坊节点,而不需要在区块链上创建一个事务(事务需要运行在每个节点上,因此花费 gas)。
稍后我们将介绍如何在自己的节点上设置 web3.js。但现在,你关键是要记住,在所能只读的函数上标记上表示“只读”的“external view 声明,就能为你的玩家减少在 DApp 中 gas 用量。
注意:如果一个
view函数在另一个函数的内部被调用,而调用函数与view函数的不属于同一个合约,也会产生调用成本。这是因为如果主调函数在以太坊创建了一个事务,它仍然需要逐个节点去验证。所以标记为view的函数只有在外部调用时才是免费的。
实战演习
我们来写一个”返回某玩家的整个僵尸军团“的函数。当我们从 web3.js 中调用它,即可显示某一玩家的个人资料页。
这个函数的逻辑有点复杂,我们需要好几个章节来描述它的实现。
- 创建一个名为
getZombiesByOwner的新函数。它有一个名为_owner的address类型的参数。 - 将其申明为
external view函数,这样当玩家从web3.js中调用它时,不需要花费任何 gas。 - 函数需要返回一个
uint [](uint数组)。
先这么声明着,我们将在下一章中填充函数体。
1 | // 在这里创建你的函数 |
第11章: 存储非常昂贵
Solidity 使用storage(存储)是相当昂贵的,”写入“操作尤其贵。
这是因为,无论是写入还是更改一段数据, 这都将永久性地写入区块链。”永久性“啊!需要在全球数千个节点的硬盘上存入这些数据,随着区块链的增长,拷贝份数更多,存储量也就越大。这是需要成本的!
为了降低成本,不到万不得已,避免将数据写入存储。这也会导致效率低下的编程逻辑 - 比如每次调用一个函数,都需要在 memory(内存) 中重建一个数组,而不是简单地将上次计算的数组给存储下来以便快速查找。
在大多数编程语言中,遍历大数据集合都是昂贵的。但是在 Solidity 中,使用一个标记了external view的函数,遍历比 storage 要便宜太多,因为 view 函数不会产生任何花销。 (gas可是真金白银啊!)。
我们将在下一章讨论for循环,现在我们来看一下看如何如何在内存中声明数组。
在内存中声明数组
在数组后面加上 memory关键字, 表明这个数组是仅仅在内存中创建,不需要写入外部存储,并且在函数调用结束时它就解散了。与在程序结束时把数据保存进 storage 的做法相比,内存运算可以大大节省gas开销 – 把这数组放在view里用,完全不用花钱。
以下是申明一个内存数组的例子:
1 | function getArray() external pure returns(uint[]) { |
这个小例子展示了一些语法规则,下一章中,我们将通过一个实际用例,展示它和 for 循环结合的做法。
注意:内存数组 必须 用长度参数(在本例中为
3)创建。目前不支持array.push()之类的方法调整数组大小,在未来的版本可能会支持长度修改。
实战演习
我们要要创建一个名为 getZombiesByOwner 的函数,它以uint []数组的形式返回某一用户所拥有的所有僵尸。
- 声明一个名为
result的uint [] memory'(内存变量数组) - 将其设置为一个新的
uint类型数组。数组的长度为该_owner所拥有的僵尸数量,这可通过调用ownerZombieCount [_ owner]来获取。 - 函数结束,返回
result。目前它只是个空数列,我们到下一章去实现它。
1 | function getZombiesByOwner(address _owner) external view returns(uint[]) { |
第12章: For 循环
在之前的章节中,我们提到过,函数中使用的数组是运行时在内存中通过 for 循环实时构建,而不是预先建立在存储中的。
为什么要这样做呢?
为了实现 getZombiesByOwner 函数,一种“无脑式”的解决方案是在 ZombieFactory 中存入”主人“和”僵尸军团“的映射。
1 | mapping (address => uint[]) public ownerToZombies |
然后我们每次创建新僵尸时,执行 ownerToZombies [owner] .push(zombieId) 将其添加到主人的僵尸数组中。而 getZombiesByOwner 函数也非常简单:
1 | function getZombiesByOwner(address _owner) external view returns (uint[]) { |
这个做法有问题
做法倒是简单。可是如果我们需要一个函数来把一头僵尸转移到另一个主人名下(我们一定会在后面的课程中实现的),又会发生什么?
这个“换主”函数要做到:
1.将僵尸push到新主人的 ownerToZombies 数组中, 2.从旧主的 ownerToZombies 数组中移除僵尸, 3.将旧主僵尸数组中“换主僵尸”之后的的每头僵尸都往前挪一位,把挪走“换主僵尸”后留下的“空槽”填上, 4.将数组长度减1。
但是第三步实在是太贵了!因为每挪动一头僵尸,我们都要执行一次写操作。如果一个主人有20头僵尸,而第一头被挪走了,那为了保持数组的顺序,我们得做19个写操作。
由于写入存储是 Solidity 中最费 gas 的操作之一,使得换主函数的每次调用都非常昂贵。更糟糕的是,每次调用的时候花费的 gas 都不同!具体还取决于用户在原主军团中的僵尸头数,以及移走的僵尸所在的位置。以至于用户都不知道应该支付多少 gas。
注意:当然,我们也可以把数组中最后一个僵尸往前挪来填补空槽,并将数组长度减少一。但这样每做一笔交易,都会改变僵尸军团的秩序。
由于从外部调用一个 view 函数是免费的,我们也可以在 getZombiesByOwner 函数中用一个for循环遍历整个僵尸数组,把属于某个主人的僵尸挑出来构建出僵尸数组。那么我们的 transfer 函数将会便宜得多,因为我们不需要挪动存储里的僵尸数组重新排序,总体上这个方法会更便宜,虽然有点反直觉。
使用 for 循环
for循环的语法在 Solidity 和 JavaScript 中类似。
来看一个创建偶数数组的例子:
1 | function getEvens() pure external returns(uint[]) { |
这个函数将返回一个形为 [2,4,6,8,10] 的数组。
实战演习
我们回到 getZombiesByOwner 函数, 通过一条 for 循环来遍历 DApp 中所有的僵尸, 将给定的‘用户id’与每头僵尸的‘主人’进行比较,并在函数返回之前将它们推送到我们的result 数组中。
1.声明一个变量 counter,属性为 uint,设其值为 0 。我们用这个变量作为 result 数组的索引。
2.声明一个 for 循环, 从 uint i = 0 到 i <zombies.length。它将遍历数组中的每一头僵尸。
3.在每一轮 for 循环中,用一个 if 语句来检查 zombieToOwner [i] 是否等于 _owner。这会比较两个地址是否匹配。
4.在 if 语句中:
- 通过将
result [counter]设置为i,将僵尸ID添加到result数组中。 - 将counter加1(参见上面的for循环示例)。
就是这样 - 这个函数能返回 _owner 所拥有的僵尸数组,不花一分钱 gas。
1 | function getZombiesByOwner(address _owner) external view returns(uint[]) { |
第13章: 放在一起
恭喜您啊,居然把第三课也学完了!
让我们回顾一下:
- 添加了一种新方法来修改CryptoKitties合约
- 学会使用
onlyOwner进行调用权限限制 - 了解了 gas 和 gas 的优化
- 为僵尸添加了 “级别” 和 “冷却周期”属性
- 当僵尸达到一定级别时,允许修改僵尸的名字和 DNA
- 最后,定义了一个函数,用以返回某个玩家的僵尸军团
领奖时间
作为完成第三课的奖励,您的两个僵尸都已经升级了!
现在 NoName(你在第2课创建的小猫僵尸)已经升级到第2级,你可以调用 changeName 给它取个名字。 终于不再是无名之辈了!
去给您的 NoName 取个名字吧,等你做完下一章,本课程就结束了。
lesson4 僵尸作战系统
第1章: 可支付
截至目前,我们只接触到很少的 函数修饰符。 要记住所有的东西很难,所以我们来个概览:
- 我们有决定函数何时和被谁调用的可见性修饰符:
private意味着它只能被合约内部调用;internal就像private但是也能被继承的合约调用;external只能从合约外部调用;最后public可以在任何地方调用,不管是内部还是外部。 - 我们也有状态修饰符, 告诉我们函数如何和区块链交互:
view告诉我们运行这个函数不会更改和保存任何数据;pure告诉我们这个函数不但不会往区块链写数据,它甚至不从区块链读取数据。这两种在被从合约外部调用的时候都不花费任何gas(但是它们在被内部其他函数调用的时候将会耗费gas)。 - 然后我们有了自定义的
modifiers,例如在第三课学习的:onlyOwner和aboveLevel。 对于这些修饰符我们可以自定义其对函数的约束逻辑。
这些修饰符可以同时作用于一个函数定义上:
1 | function test() external view onlyOwner anotherModifier { /* ... */ } |
在这一章,我们来学习一个新的修饰符 payable.
payable 修饰符
payable 方法是让 Solidity 和以太坊变得如此酷的一部分 —— 它们是一种可以接收以太的特殊函数。
先放一下。当你在调用一个普通网站服务器上的API函数的时候,你无法用你的函数传送美元——你也不能传送比特币。
但是在以太坊中, 因为钱 (以太), 数据 (事务负载), 以及合约代码本身都存在于以太坊。你可以在同时调用函数 并付钱给另外一个合约。
这就允许出现很多有趣的逻辑, 比如向一个合约要求支付一定的钱来运行一个函数。
来看个例子
1 | contract OnlineStore { |
在这里,msg.value 是一种可以查看向合约发送了多少以太的方法,另外 ether 是一个內建单元。
这里发生的事是,一些人会从 web3.js 调用这个函数 (从DApp的前端), 像这样 :
1 | // 假设 `OnlineStore` 在以太坊上指向你的合约: |
注意这个 value 字段, JavaScript 调用来指定发送多少(0.001)以太。如果把事务想象成一个信封,你发送到函数的参数就是信的内容。 添加一个 value 很像在信封里面放钱 —— 信件内容和钱同时发送给了接收者。
注意: 如果一个函数没标记为
payable, 而你尝试利用上面的方法发送以太,函数将拒绝你的事务。
实战演习
我们来在僵尸游戏里面创建一个payable 函数。
假定在我们的游戏中,玩家可以通过支付ETH来升级他们的僵尸。ETH将存储在你拥有的合约中 —— 一个简单明了的例子,向你展示你可以通过自己的游戏赚钱。
- 定义一个
uint,命名为levelUpFee, 将值设定为0.001 ether。 - 定义一个名为
levelUp的函数。 它将接收一个uint参数_zombieId。 函数应该修饰为external以及payable。 - 这个函数首先应该
require确保msg.value等于levelUpFee。 - 然后它应该增加僵尸的
level:zombies[_zombieId].level++。
1 | // 1. 在这里定义 levelUpFee |
第2章: 提现
在上一章,我们学习了如何向合约发送以太,那么在发送之后会发生什么呢?
在你发送以太之后,它将被存储进以合约的以太坊账户中, 并冻结在哪里 —— 除非你添加一个函数来从合约中把以太提现。
你可以写一个函数来从合约中提现以太,类似这样:
1 | contract GetPaid is Ownable { |
注意我们使用 Ownable 合约中的 owner 和 onlyOwner,假定它已经被引入了。
你可以通过 transfer 函数向一个地址发送以太, 然后 this.balance 将返回当前合约存储了多少以太。 所以如果100个用户每人向我们支付1以太, this.balance 将是100以太。
你可以通过 transfer 向任何以太坊地址付钱。 比如,你可以有一个函数在 msg.sender 超额付款的时候给他们退钱:
1 | uint itemFee = 0.001 ether; |
或者在一个有卖家和卖家的合约中, 你可以把卖家的地址存储起来, 当有人买了它的东西的时候,把买家支付的钱发送给它 seller.transfer(msg.value)。
有很多例子来展示什么让以太坊编程如此之酷 —— 你可以拥有一个不被任何人控制的去中心化市场。
实战演习
在我们的合约里创建一个
withdraw函数,它应该几乎和上面的GetPaid一样。以太的价格在过去几年内翻了十几倍,在我们写这个教程的时候 0.01 以太相当于1美元,如果它再翻十倍 0.001 以太将是10美元,那我们的游戏就太贵了。
所以我们应该再创建一个函数,允许我们以合约拥有者的身份来设置
levelUpFee。a. 创建一个函数,名为
setLevelUpFee, 其接收一个参数uint _fee,是external并使用修饰符onlyOwner。b. 这个函数应该设置
levelUpFee等于_fee。
1 | // 1. 在这里创建 withdraw 函数 |
第3章: 僵尸战斗
在我们学习了可支付函数和合约余额之后,是时候为僵尸战斗添加功能了。
遵循上一章的格式,我们新建一个攻击功能合约,并将代码放进新的文件中,引入上一个合约。
实战演习
再来新建一个合约吧。熟能生巧。
如果你不记得怎么做了, 查看一下 zombiehelper.sol — 不过最好先试着做一下,检查一下你掌握的情况。
- 在文件开头定义 Solidity 的版本
^0.4.19. import自zombiehelper.sol.- 声明一个新的
contract,命名为ZombieBattle, 继承自ZombieHelper。函数体就先空着吧。
1 | pragma solidity ^0.4.19; |
第4章: 随机数
你太棒了!接下来我们梳理一下战斗逻辑。
优秀的游戏都需要一些随机元素,那么我们在 Solidity 里如何生成随机数呢?
真正的答案是你不能,或者最起码,你无法安全地做到这一点。
我们来看看为什么
用 keccak256 来制造随机数
Solidity 中最好的随机数生成器是 keccak256 哈希函数.
我们可以这样来生成一些随机数
1 | // 生成一个0到100的随机数: |
这个方法首先拿到 now 的时间戳、 msg.sender、 以及一个自增数 nonce (一个仅会被使用一次的数,这样我们就不会对相同的输入值调用一次以上哈希函数了)。
然后利用 keccak 把输入的值转变为一个哈希值, 再将哈希值转换为 uint, 然后利用 % 100 来取最后两位, 就生成了一个0到100之间随机数了。
这个方法很容易被不诚实的节点攻击
在以太坊上, 当你在和一个合约上调用函数的时候, 你会把它广播给一个节点或者在网络上的 *transaction* 节点们。 网络上的节点将收集很多事务, 试着成为第一个解决计算密集型数学问题的人,作为“工作证明”,然后将“工作证明”(Proof of Work, PoW)和事务一起作为一个 *block* 发布在网络上。
一旦一个节点解决了一个PoW, 其他节点就会停止尝试解决这个 PoW, 并验证其他节点的事务列表是有效的,然后接受这个节点转而尝试解决下一个节点。
这就让我们的随机数函数变得可利用了
我们假设我们有一个硬币翻转合约——正面你赢双倍钱,反面你输掉所有的钱。假如它使用上面的方法来决定是正面还是反面 (random >= 50 算正面, random < 50 算反面)。
如果我正运行一个节点,我可以 只对我自己的节点 发布一个事务,且不分享它。 我可以运行硬币翻转方法来偷窥我的输赢 — 如果我输了,我就不把这个事务包含进我要解决的下一个区块中去。我可以一直运行这个方法,直到我赢得了硬币翻转并解决了下一个区块,然后获利。
所以我们该如何在以太坊上安全地生成随机数呢
因为区块链的全部内容对所有参与者来说是透明的, 这就让这个问题变得很难,它的解决方法不在本课程讨论范围,你可以阅读 这个 StackOverflow 上的讨论 来获得一些主意。 一个方法是利用 *oracle* 来访问以太坊区块链之外的随机数函数。
当然, 因为网络上成千上万的以太坊节点都在竞争解决下一个区块,我能成功解决下一个区块的几率非常之低。 这将花费我们巨大的计算资源来开发这个获利方法 — 但是如果奖励异常地高(比如我可以在硬币翻转函数中赢得 1个亿), 那就很值得去攻击了。
所以尽管这个方法在以太坊上不安全,在实际中,除非我们的随机函数有一大笔钱在上面,你游戏的用户一般是没有足够的资源去攻击的。
因为在这个教程中,我们只是在编写一个简单的游戏来做演示,也没有真正的钱在里面,所以我们决定接受这个不足之处,使用这个简单的随机数生成函数。但是要谨记它是不安全的。
实战演习
我们来实现一个随机数生成函数,好来计算战斗的结果。虽然这个函数一点儿也不安全。
- 给我们合约一个名为
randNonce的uint,将其值设置为0。 - 建立一个函数,命名为
randMod(random-modulus)。它将作为internal函数,传入一个名为_modulus的uint,并returns一个uint。 - 这个函数首先将为
randNonce加一, (使用randNonce++语句)。 - 最后,它应该 (在一行代码中) 计算
now,msg.sender, 以及randNonce的keccak256哈希值并转换为uint—— 最后return% _modulus的值。 (天! 听起来太拗口了。如果你有点理解不过来,看一下我们上面计算随机数的例子,它们的逻辑非常相似)
1 | contract ZombieBattle is ZombieHelper { |
第5章: 僵尸对战
我们的合约已经有了一些随机性的来源,可以用进我们的僵尸战斗中去计算结果。
我们的僵尸战斗看起来将是这个流程:
- 你选择一个自己的僵尸,然后选择一个对手的僵尸去攻击。
- 如果你是攻击方,你将有70%的几率获胜,防守方将有30%的几率获胜。
- 所有的僵尸(攻守双方)都将有一个
winCount和一个lossCount,这两个值都将根据战斗结果增长。 - 若攻击方获胜,这个僵尸将升级并产生一个新僵尸。
- 如果攻击方失败,除了失败次数将加一外,什么都不会发生。
- 无论输赢,当前僵尸的冷却时间都将被激活。
这有一大堆的逻辑需要处理,我们将把这些步骤分解到接下来的课程中去。
实战演习
- 给我们合约一个
uint类型的变量,命名为attackVictoryProbability, 将其值设定为70。 - 创建一个名为
attack的函数。它将传入两个参数:_zombieId(uint类型) 以及_targetId(也是uint)。它将是一个external函数。
函数体先留空吧。
1 | // 在这里创建 attackVictoryProbability |
第6章: 重构通用逻辑
不管谁调用我们的 attack 函数 —— 我们想确保用户的确拥有他们用来攻击的僵尸。如果你能用其他人的僵尸来攻击将是一个很大的安全问题。
你能想一下我们如何添加一个检查步骤来看看调用这个函数的人就是他们传入的 _zombieId 的拥有者么?
想一想,看看你能不能自己找到一些答案。
花点时间…… 参考我们前面课程的代码来获得灵感。
答案在下面,在你有一些想法之前不要继续阅读。
答案
我们在前面的课程里面已经做过很多次这样的检查了。 在 changeName(), changeDna(), 和 feedAndMultiply()里,我们做过这样的检查:
1 | require(msg.sender == zombieToOwner[_zombieId]); |
这和我们 attack 函数将要用到的检查逻辑是相同的。 正因我们要多次调用这个检查逻辑,让我们把它移到它自己的 modifier 中来清理代码并避免重复编码。
实战演习
我们回到了 zombiefeeding.sol, 因为这是我们第一次调用检查逻辑的地方。让我们把它重构进它自己的 modifier。
创建一个
modifier, 命名为ownerOf。它将传入一个参数,_zombieId(一个uint)。它的函数体应该
requiremsg.sender等于zombieToOwner[_zombieId], 然后继续这个函数剩下的内容。 如果你忘记了修饰符的写法,可以参考zombiehelper.sol。将这个函数的
feedAndMultiply定义修改为其使用修饰符ownerOf。现在我们使用
modifier了,你可以删除这行了:require(msg.sender == zombieToOwner[_zombieId]);
1 | // 1. 在这里创建 modifier |
第7章: 更多重构
在 zombiehelper.sol里有几处地方,需要我们实现我们新的 modifier—— ownerOf。
实战演习
- 修改
changeName()使其使用ownerOf - 修改
changeDna()使其使用ownerOf
1 | // 1. 使用 `ownerOf` 修改这个函数: |
第8章: 回到攻击!
重构完成了,回到 zombieattack.sol。
继续来完善我们的 attack 函数, 现在我们有了 ownerOf 修饰符来用了。
实战演习
将
ownerOf修饰符添加到attack来确保调用者拥有_zombieId.我们的函数所需要做的第一件事就是获得一个双方僵尸的
storage指针, 这样我们才能很方便和它们交互:a. 定义一个
Zombie storage命名为myZombie,使其值等于zombies[_zombieId]。b. 定义一个
Zombie storage命名为enemyZombie, 使其值等于zombies[_targetId]。我们将用一个0到100的随机数来确定我们的战斗结果。 定义一个
uint,命名为rand, 设定其值等于randMod函数的返回值,此函数传入100作为参数。
1 | // 1. 在这里增加 modifier |
第9章: 僵尸的输赢
对我们的僵尸游戏来说,我们将要追踪我们的僵尸输赢了多少场。有了这个我们可以在游戏里维护一个 “僵尸排行榜”。
有多种方法在我们的DApp里面保存一个数值 — 作为一个单独的映射,作为一个“排行榜”结构体,或者保存在 Zombie 结构体内。
每个方法都有其优缺点,取决于我们打算如何和这些数据打交道。在这个教程中,简单起见我们将这个状态保存在 Zombie 结构体中,将其命名为 winCount 和 lossCount。
我们跳回 zombiefactory.sol, 将这些属性添加进 Zombie 结构体.
实战演习
修改
Zombie结构体,添加两个属性:a.
winCount, 一个uint16b.
lossCount, 也是一个uint16注意: 记住, 因为我们能在结构体中包装
uint, 我们打算用适合我们的最小的uint。 一个uint8太小了, 因为 2^8 = 256 —— 如果我们的僵尸每天都作战,不到一年就溢出了。但是 2^16 = 65536 (uint16)—— 除非一个僵尸连续179年每天作战,否则我们就是安全的。现在我们的
Zombie结构体有了新的属性, 我们需要修改_createZombie()中的函数定义。修改僵尸生成定义,让每个新僵尸都有
0赢和0输。
1 | struct Zombie { |
第10章: 僵尸胜利了 😄
有了 winCount 和 lossCount,我们可以根据僵尸哪个僵尸赢了战斗来更新它们了。
在第六章我们计算出来一个0到100的随机数。现在让我们用那个数来决定那谁赢了战斗,并以此更新我们的状态。
实战演习
创建一个
if语句来检查rand是不是 *小于或者等于*attackVictoryProbability。如果以上条件为
true, 我们的僵尸就赢了!所以:a. 增加
myZombie的winCount。b. 增加
myZombie的level。 (升级了啦!!!!!!!)c. 增加
enemyZombie的lossCount. (输家!!!!!! 😫 😫 😫)d. 运行
feedAndMultiply函数。 在zombiefeeding.sol里查看调用它的语句。 对于第三个参数 (_species),传入字符串 “zombie”. (现在它实际上什么都不做,不过在稍后, 如果我们愿意,可以添加额外的方法,用来制造僵尸变的僵尸)。
1 | function attack(uint _zombieId, uint _targetId) external ownerOf(_zombieId) { |
第11章: 僵尸失败 😞
我们已经编写了你的僵尸赢了之后会发生什么, 该看看 输了 的时候要怎么做了。
在我们的游戏中,僵尸输了后并不会降级 —— 只是简单地给 lossCount 加一,并触发冷却,等待一天后才能再次参战。
要实现这个逻辑,我们需要一个 else 语句。
else 语句和 JavaScript 以及很多其他语言的 else 语句一样。
1 | if (zombieCoins[msg.sender] > 100000000) { |
实战演习
添加一个
else语句。 若我们的僵尸输了:a. 增加
myZombie的lossCount。b. 增加
enemyZombie的winCount。在
else最后, 对myZombie运行_triggerCooldown方法。这让每个僵尸每天只能参战一次。
1 | function attack(uint _zombieId, uint _targetId) external ownerOf(_zombieId) { |
lesson5 ERC721 标准和加密收藏品
第1章: 以太坊上的代币
让我们来聊聊 代币.
如果你对以太坊的世界有一些了解,你很可能听过人们聊到代币——尤其是 *ERC20 代币*.
一个 代币 在以太坊基本上就是一个遵循一些共同规则的智能合约——即它实现了所有其他代币合约共享的一组标准函数,例如 transfer(address _to, uint256 _value) 和 balanceOf(address _owner).
在智能合约内部,通常有一个映射, mapping(address => uint256) balances,用于追踪每个地址还有多少余额。
所以基本上一个代币只是一个追踪谁拥有多少该代币的合约,和一些可以让那些用户将他们的代币转移到其他地址的函数。
它为什么重要呢?
由于所有 ERC20 代币共享具有相同名称的同一组函数,它们都可以以相同的方式进行交互。
这意味着如果你构建的应用程序能够与一个 ERC20 代币进行交互,那么它就也能够与任何 ERC20 代币进行交互。 这样一来,将来你就可以轻松地将更多的代币添加到你的应用中,而无需进行自定义编码。 你可以简单地插入新的代币合约地址,然后哗啦,你的应用程序有另一个它可以使用的代币了。
其中一个例子就是交易所。 当交易所添加一个新的 ERC20 代币时,实际上它只需要添加与之对话的另一个智能合约。 用户可以让那个合约将代币发送到交易所的钱包地址,然后交易所可以让合约在用户要求取款时将代币发送回给他们。
交易所只需要实现这种转移逻辑一次,然后当它想要添加一个新的 ERC20 代币时,只需将新的合约地址添加到它的数据库即可。
其他代币标准
对于像货币一样的代币来说,ERC20 代币非常酷。 但是要在我们僵尸游戏中代表僵尸就并不是特别有用。
首先,僵尸不像货币可以分割 —— 我可以发给你 0.237 以太,但是转移给你 0.237 的僵尸听起来就有些搞笑。
其次,并不是所有僵尸都是平等的。 你的2级僵尸”Steve“完全不能等同于我732级的僵尸”H4XF13LD MORRIS 💯💯😎💯💯“。(你差得远呢,Steve)。
有另一个代币标准更适合如 CryptoZombies 这样的加密收藏品——它们被称为*ERC721 代币.*
*ERC721 代币*是不能互换的,因为每个代币都被认为是唯一且不可分割的。 你只能以整个单位交易它们,并且每个单位都有唯一的 ID。 这些特性正好让我们的僵尸可以用来交易。
请注意,使用像 ERC721 这样的标准的优势就是,我们不必在我们的合约中实现拍卖或托管逻辑,这决定了玩家能够如何交易/出售我们的僵尸。 如果我们符合规范,其他人可以为加密可交易的 ERC721 资产搭建一个交易所平台,我们的 ERC721 僵尸将可以在该平台上使用。 所以使用代币标准相较于使用你自己的交易逻辑有明显的好处。
实战演习
我们将在下一章深入讨论ERC721的实现。 但首先,让我们为本课设置我们的文件结构。
我们将把所有ERC721逻辑存储在一个叫ZombieOwnership的合约中。
- 在文件顶部声明我们
pragma的版本(格式参考之前的课程)。 - 将
zombieattack.solimport进来。 - 声明一个继承
ZombieAttack的新合约, 命名为ZombieOwnership。合约的其他部分先留空。
1 | // 从这里开始 |
第2章: ERC721 标准, 多重继承
让我们来看一看 ERC721 标准:
1 | contract ERC721 { |
这是我们需要实现的方法列表,我们将在接下来的章节中逐个学习。
虽然看起来很多,但不要被吓到了!我们在这里就是准备带着你一步一步了解它们的。
注意: ERC721目前是一个 草稿,还没有正式商定的实现。在本教程中,我们使用的是 OpenZeppelin 库中的当前版本,但在未来正式发布之前它可能会有更改。 所以把这 一个 可能的实现当作考虑,但不要把它作为 ERC721 代币的官方标准。
实现一个代币合约
在实现一个代币合约的时候,我们首先要做的是将接口复制到它自己的 Solidity 文件并导入它,import "./erc721.sol";。 接着,让我们的合约继承它,然后我们用一个函数定义来重写每个方法。
但等一下—— ZombieOwnership已经继承自 ZombieAttack了 —— 它如何能够也继承于 ERC721呢?
幸运的是在Solidity,你的合约可以继承自多个合约,参考如下:
1 | contract SatoshiNakamoto is NickSzabo, HalFinney { |
正如你所见,当使用多重继承的时候,你只需要用逗号 , 来隔开几个你想要继承的合约。在上面的例子中,我们的合约继承自 NickSzabo 和 HalFinney。
来试试吧。
实战演习
我们已经在上面为你创建了带着接口的 erc721.sol 。
- 将
erc721.sol导入到zombieownership.sol - 声明
ZombieOwnership继承自ZombieAttack和ERC721
1 | pragma solidity ^0.4.19; |
第3章: balanceOf 和 ownerOf
太棒了,我们来深入讨论一下 ERC721 的实现。
我们已经把所有你需要在本课中实现的函数的空壳复制好了。
在本章节,我们将实现头两个方法: balanceOf 和 ownerOf。
balanceOf
1 | function balanceOf(address _owner) public view returns (uint256 _balance); |
这个函数只需要一个传入 address 参数,然后返回这个 address 拥有多少代币。
在我们的例子中,我们的“代币”是僵尸。你还记得在我们 DApp 的哪里存储了一个主人拥有多少只僵尸吗?
ownerOf
1 | function ownerOf(uint256 _tokenId) public view returns (address _owner); |
这个函数需要传入一个代币 ID 作为参数 (我们的情况就是一个僵尸 ID),然后返回该代币拥有者的 address。
同样的,因为在我们的 DApp 里已经有一个 mapping (映射) 存储了这个信息,所以对我们来说这个实现非常直接清晰。我们可以只用一行 return 语句来实现这个函数。
注意:要记得,
uint256等同于uint。我们从课程的开始一直在代码中使用uint,但从现在开始我们将在这里用uint256,因为我们直接从规范中复制粘贴。
实战演习
我将让你来决定如何实现这两个函数。
每个函数的代码都应该只有1行 return 语句。看看我们在之前课程中写的代码,想想我们都把这个数据存储在哪。如果你觉得有困难,你可以点“我要看答案”的按钮来获得帮助。
- 实现
balanceOf来返回_owner拥有的僵尸数量。 - 实现
ownerOf来返回拥有 ID 为_tokenId僵尸的所有者的地址。
1 | function balanceOf(address _owner) public view returns (uint256 _balance) { |
第4章: 重构
嘿嘿!我们刚刚的代码中其实有个错误,以至于其根本无法通过编译,你发现了没?
在前一个章节我们定义了一个叫 ownerOf 的函数。但如果你还记得第4课的内容,我们同样在zombiefeeding.sol 里以 ownerOf 命名创建了一个 modifier(修饰符)。
如果你尝试编译这段代码,编译器会给你一个错误说你不能有相同名称的修饰符和函数。
所以我们应该把在 ZombieOwnership 里的函数名称改成别的吗?
不,我们不能那样做!!!要记得,我们正在用 ERC721 代币标准,意味着其他合约将期望我们的合约以这些确切的名称来定义函数。这就是这些标准实用的原因——如果另一个合约知道我们的合约符合 ERC721 标准,它可以直接与我们交互,而无需了解任何关于我们内部如何实现的细节。
所以,那意味着我们将必须重构我们第4课中的代码,将 modifier 的名称换成别的。
实战演习
我们回到了 zombiefeeding.sol 。我们将把 modifier 的名称从 ownerOf 改成 onlyOwnerOf。
- 把修饰符定义中的名称改成
onlyOwnerOf - 往下滑到使用此修饰符的函数
feedAndMultiply。我们也需要改这里的名称。
注意:我们在
zombiehelper.sol和zombieattack.sol里也使用了这个修饰符,但为了不在这节课的重构里花太多时间,我们已经将那些文件里的修饰符名称为你改好了。
1 | // 1. 把修饰符名称改成 `onlyOwnerOf` |
第5章: ERC721: 转移标准
好了,我们将冲突修复了!
现在我们将通过学习把所有权从一个人转移给另一个人来继续我们的 ERC721 规范的实现。
注意 ERC721 规范有两种不同的方法来转移代币:
1 | function transfer(address _to, uint256 _tokenId) public; |
- 第一种方法是代币的拥有者调用
transfer方法,传入他想转移到的address和他想转移的代币的_tokenId。 - 第二种方法是代币拥有者首先调用
approve,然后传入与以上相同的参数。接着,该合约会存储谁被允许提取代币,通常存储到一个mapping (uint256 => address)里。然后,当有人调用takeOwnership时,合约会检查msg.sender是否得到拥有者的批准来提取代币,如果是,则将代币转移给他。
你注意到了吗,transfer 和 takeOwnership 都将包含相同的转移逻辑,只是以相反的顺序。 (一种情况是代币的发送者调用函数;另一种情况是代币的接收者调用它)。
所以我们把这个逻辑抽象成它自己的私有函数 _transfer,然后由这两个函数来调用它。 这样我们就不用写重复的代码了。
实战演习
让我们来定义 _transfer 的逻辑。
定义一个名为
_transfer的函数。它会需要3个参数:address _from、address _to和uint256 _tokenId。它应该是一个私有函数。我们有2个映射会在所有权改变的时候改变:
ownerZombieCount(记录一个所有者有多少只僵尸)和zombieToOwner(记录什么人拥有什么)。我们的函数需要做的第一件事是为 接收 僵尸的人(
address _to)增 加ownerZombieCount。使用++来增加。接下来,我们将需要为 发送 僵尸的人(
address _from)减少ownerZombieCount。使用--来扣减。最后,我们将改变这个
_tokenId的zombieToOwner映射,这样它现在就会指向_to。骗你的,那不是最后一步。我们还需要再做一件事情。
ERC721规范包含了一个
Transfer事件。这个函数的最后一行应该用正确的参数触发Transfer——查看erc721.sol看它期望传入的参数并在这里实现。
1 | // 在这里定义 _transfer() |
第6章: ERC721: 转移-续
太好了!刚才那是最难的部分——现在实现公共的 transfer 函数应该十分容易,因为我们的 _transfer 函数几乎已经把所有的重活都干完了。
实战演习
我们想确保只有代币或僵尸的所有者可以转移它。还记得我们如何限制只有所有者才能访问某个功能吗?
没错,我们已经有一个修饰符能够完成这个任务了。所以将修饰符
onlyOwnerOf添加到这个函数中。现在该函数的正文只需要一行代码。它只需要调用
_transfer。记得把
msg.sender作为参数传递进address _from。
1 | // 1. 在这里添加修饰符 |
第7章: ERC721: 批准
现在,让我们来实现 approve。
记住,使用 approve 或者 takeOwnership 的时候,转移有2个步骤:
- 你,作为所有者,用新主人的
address和你希望他获取的_tokenId来调用approve - 新主人用
_tokenId来调用takeOwnership,合约会检查确保他获得了批准,然后把代币转移给他。
因为这发生在2个函数的调用中,所以在函数调用之间,我们需要一个数据结构来存储什么人被批准获取什么。
实战演习
首先,让我们来定义一个映射
zombieApprovals。它应该将一个uint映射到一个address。这样一来,当有人用一个
_tokenId调用takeOwnership时,我们可以用这个映射来快速查找谁被批准获取那个代币。在函数
approve上, 我们想要确保只有代币所有者可以批准某人来获取代币。所以我们需要添加修饰符onlyOwnerOf到approve。函数的正文部分,将
_tokenId的zombieApprovals设置为和_to相等。最后,在 ERC721 规范里有一个
Approval事件。所以我们应该在这个函数的最后触发这个事件。(参考erc721.sol来确认传入的参数,并确保_owner是msg.sender)
1 | // 1. 在这里定义映射 |
第8章: ERC721: takeOwnership
太棒了,现在让我们完成最后一个函数来结束 ERC721 的实现。(别担心,这后面我们还会讲更多内容😉)
最后一个函数 takeOwnership, 应该只是简单地检查以确保 msg.sender 已经被批准来提取这个代币或者僵尸。若确认,就调用 _transfer;
实战演习
首先,我们要用一个
require句式来检查_tokenId的zombieApprovals和msg.sender相等。这样如果
msg.sender未被授权来提取这个代币,将抛出一个错误。为了调用
_transfer,我们需要知道代币所有者的地址(它需要一个_from来作为参数)。幸运的是我们可以在我们的ownerOf函数中来找到这个参数。所以,定义一个名为
owner的address变量,并使其等于ownerOf(_tokenId)。最后,调用
_transfer, 并传入所有必须的参数。(在这里你可以用msg.sender作为_to, 因为代币正是要发送给调用这个函数的人)。注意: 我们完全可以用一行代码来实现第2、3两步。但是分开写会让代码更易读。一点个人建议 :)
1 | function takeOwnership(uint256 _tokenId) public { |
第9章: 预防溢出
恭喜你,我们完成了 ERC721 的实现。
并不是很复杂,对吧?很多类似的以太坊概念,当你只听人们谈论它们的时候,会觉得很复杂。所以最简单的理解方式就是你自己来实现它。
不过要记住那只是最简单的实现。还有很多的特性我们也许想加入到我们的实现中来,比如一些额外的检查,来确保用户不会不小心把他们的僵尸转移给0 地址(这被称作 “烧币”, 基本上就是把代币转移到一个谁也没有私钥的地址,让这个代币永远也无法恢复)。 或者在 DApp 中加入一些基本的拍卖逻辑。(你能想出一些实现的方法么?)
但是为了让我们的课程不至于离题太远,所以我们只专注于一些基础实现。如果你想学习一些更深层次的实现,可以在这个教程结束后,去看看 OpenZeppelin 的 ERC721 合约。
合约安全增强: 溢出和下溢
我们将来学习你在编写智能合约的时候需要注意的一个主要的安全特性:防止溢出和下溢。
什么是 溢出 (*overflow*)?
假设我们有一个 uint8, 只能存储8 bit数据。这意味着我们能存储的最大数字就是二进制 11111111 (或者说十进制的 2^8 - 1 = 255).
来看看下面的代码。最后 number 将会是什么值?
1 | uint8 number = 255; |
在这个例子中,我们导致了溢出 — 虽然我们加了1, 但是 number 出乎意料地等于 0了。 (如果你给二进制 11111111 加1, 它将被重置为 00000000,就像钟表从 23:59 走向 00:00)。
下溢(underflow)也类似,如果你从一个等于 0 的 uint8 减去 1, 它将变成 255 (因为 uint 是无符号的,其不能等于负数)。
虽然我们在这里不使用 uint8,而且每次给一个 uint256 加 1 也不太可能溢出 (2^256 真的是一个很大的数了),在我们的合约中添加一些保护机制依然是非常有必要的,以防我们的 DApp 以后出现什么异常情况。
使用 SafeMath
为了防止这些情况,OpenZeppelin 建立了一个叫做 SafeMath 的 库(*library*),默认情况下可以防止这些问题。
不过在我们使用之前…… 什么叫做库?
一个**库** 是 Solidity 中一种特殊的合约。其中一个有用的功能是给原始数据类型增加一些方法。
比如,使用 SafeMath 库的时候,我们将使用 using SafeMath for uint256 这样的语法。 SafeMath 库有四个方法 — add, sub, mul, 以及 div。现在我们可以这样来让 uint256 调用这些方法:
1 | using SafeMath for uint256; |
我们将在下一章来学习这些方法,不过现在我们先将 SafeMath 库添加进我们的合约。
实战演习
我们已经帮你把 OpenZeppelin 的 SafeMath 库包含进 safemath.sol了,如果你想看一下代码的话,现在可以看看,不过我们下一章将深入进去。
首先我们来告诉我们的合约要使用 SafeMath。我们将在我们的 ZombieFactory 里调用,这是我们的基础合约 — 这样其他所有继承出去的子合约都可以使用这个库了。
- 将
safemath.sol引入到zombiefactory.sol. - 添加定义:
using SafeMath for uint256;.
1 | // 1. 在这里引入 |
第10章: SafeMath 第二部分
来看看 SafeMath 的部分代码:
1 | library SafeMath { |
首先我们有了 library 关键字 — 库和 合约很相似,但是又有一些不同。 就我们的目的而言,库允许我们使用 using 关键字,它可以自动把库的所有方法添加给一个数据类型:
1 | using SafeMath for uint; |
注意 mul 和 add 其实都需要两个参数。 在我们声明了 using SafeMath for uint 后,我们用来调用这些方法的 uint 就自动被作为第一个参数传递进去了(在此例中就是 test)
我们来看看 add 的源代码看 SafeMath 做了什么:
1 | function add(uint256 a, uint256 b) internal pure returns (uint256) { |
基本上 add 只是像 + 一样对两个 uint 相加, 但是它用一个 assert 语句来确保结果大于 a。这样就防止了溢出。
assert 和 require 相似,若结果为否它就会抛出错误。 assert 和 require 区别在于,require 若失败则会返还给用户剩下的 gas, assert 则不会。所以大部分情况下,你写代码的时候会比较喜欢 require,assert 只在代码可能出现严重错误的时候使用,比如 uint 溢出。
所以简而言之, SafeMath 的 add, sub, mul, 和 div 方法只做简单的四则运算,然后在发生溢出或下溢的时候抛出错误。
在我们的代码里使用 SafeMath
为了防止溢出和下溢,我们可以在我们的代码里找 +, -, *, 或 /,然后替换为 add, sub, mul, div.
比如,与其这样做:
1 | myUint++; |
我们这样做:
1 | myUint = myUint.add(1); |
实战演习
在 ZombieOwnership 中有两个地方用到了数学运算,来替换成 SafeMath 方法把。
- 将
++替换成 SafeMath 方法。 - 将
--替换成 SafeMath 方法。
1 | function _transfer(address _from, address _to, uint256 _tokenId) private { |
第11章: SafeMath 第三部分
太好了,这下我们的 ERC721 实现不会有溢出或者下溢了。
回头看看我们在之前课程写的代码,还有其他几个地方也有可能导致溢出或下溢。
比如, 在 ZombieAttack 里面我们有:
1 | myZombie.winCount++; |
我们同样应该在这些地方防止溢出。(通常情况下,总是使用 SafeMath 而不是普通数学运算是个好主意,也许在以后 Solidity 的新版本里这点会被默认实现,但是现在我们得自己在代码里实现这些额外的安全措施)。
不过我们遇到个小问题 — winCount 和 lossCount 是 uint16, 而 level 是 uint32。 所以如果我们用这些作为参数传入 SafeMath 的 add 方法。 它实际上并不会防止溢出,因为它会把这些变量都转换成 uint256:
1 | function add(uint256 a, uint256 b) internal pure returns (uint256) { |
这就意味着,我们需要再实现两个库来防止 uint16 和 uint32 溢出或下溢。我们可以将其命名为 SafeMath16 和 SafeMath32。
代码将和 SafeMath 完全相同,除了所有的 uint256 实例都将被替换成 uint32 或 uint16。
我们已经将这些代码帮你写好了,打开 safemath.sol 合约看看代码吧。
现在我们需要在 ZombieFactory 里使用它们。
Putting it to the Test
分配:
- 声明我们将为
uint32使用SafeMath32。 - 声明我们将为
uint16使用SafeMath16。 - 在 ZombieFactory 里还有一处我们也应该使用 SafeMath 的方法, 我们已经在那里留了注释提醒你。
1 | contract ZombieFactory is Ownable { |
第12章: SafeMath 第4部分
真棒,现在我们已经为我们的 DApp 里面用到的 uint 数据类型都实现了 SafeMath 了。
让我们把 ZombieAttack 里所有潜在的问题都修复了吧。 (其实在 ZombieHelper 里也有一处 zombies[_zombieId].level++; 需要修复,不过我们已经帮你做好了,这样我们就不用再来一章了 😉)。
实战演习
放心大胆去对 ZombieAttack 里所有的 ++ 操作都使用 SafeMath 方法吧。为了方便你找,我们已经在相应的地方留了注释给你。
1 | pragma solidity ^0.4.19; |
第13章: 注释
僵尸游戏的 Solidity 代码终于完成啦。
在以后的课程中,我们将学习如何将游戏部署到以太坊,以及如何和 Web3.js 交互。
不过在你离开第五课之前,我们来谈谈如何 给你的代码添加注释.
注释语法
Solidity 里的注释和 JavaScript 相同。在我们的课程中你已经看到了不少单行注释了:
1 | // 这是一个单行注释,可以理解为给自己或者别人看的笔记 |
只要在任何地方添加一个 // 就意味着你在注释。如此简单所以你应该经常这么做。
不过我们也知道你的想法:有时候单行注释是不够的。毕竟你生来话痨。
所以我们有了多行注释:
1 | contract CryptoZombies { |
特别是,最好为你合约中每个方法添加注释来解释它的预期行为。这样其他开发者(或者你自己,在6个月以后再回到这个项目中)可以很快地理解你的代码而不需要逐行阅读所有代码。
Solidity 社区所使用的一个标准是使用一种被称作 *natspec* 的格式,看起来像这样:
1 | /// @title 一个简单的基础运算合约 |
@title(标题) 和 @author (作者)很直接了.
@notice (须知)向 用户 解释这个方法或者合约是做什么的。 @dev (开发者) 是向开发者解释更多的细节。
@param (参数)和 @return (返回) 用来描述这个方法需要传入什么参数以及返回什么值。
注意你并不需要每次都用上所有的标签,它们都是可选的。不过最少,写下一个 @dev 注释来解释每个方法是做什么的。
实战演习
如果你还没注意到:CryptoZombies 的答案检查器在工作的时候将忽略所有的注释。所以这一章我们其实无法检查你的 natspec 注释了。全靠你自己咯。
话说回来,到现在你应该已经是一个 Solidity 小能手了。我们就假定你已经学会这些了。
大胆去做些尝试把,给 ZombieOwnership 加上一些 natspec 标签:
@title— 例如:一个管理转移僵尸所有权的合约@author— 你的名字@dev— 例如:符合 OpenZeppelin 对 ERC721 标准草案的实现
1 | pragma solidity ^0.4.19; |
总结一下
这节课里面我们学到了
- 代币, ERC721 标准,以及可交易的物件/僵尸
- 库以及如何使用库
- 如何利用 SafeMath 来防止溢出和下溢
- 代码注释和 natspec 标准
在接下来的两节课中,我们将学习如何将游戏部署到以太坊以及和 *web3.js* 交互 (这样你就能为你的 DApp 打造一个界面了 )。
lesson6 应用前端和 Web3.js
第1章: 介绍 Web3.js
完成第五课以后,我们的僵尸 DApp 的 Solidity 合约部分就完成了。现在我们来做一个基本的网页好让你的用户能玩它。 要做到这一点,我们将使用以太坊基金发布的 JavaScript 库 —— *Web3.js*.
什么是 Web3.js?
还记得么?以太坊网络是由节点组成的,每一个节点都包含了区块链的一份拷贝。当你想要调用一份智能合约的一个方法,你需要从其中一个节点中查找并告诉它:
- 智能合约的地址
- 你想调用的方法,以及
- 你想传入那个方法的参数
以太坊节点只能识别一种叫做 *JSON-RPC* 的语言。这种语言直接读起来并不好懂。当你你想调用一个合约的方法的时候,需要发送的查询语句将会是这样的:
1 | // 哈……祝你写所有这样的函数调用的时候都一次通过 |
幸运的是 Web3.js 把这些令人讨厌的查询语句都隐藏起来了, 所以你只需要与方便易懂的 JavaScript 界面进行交互即可。
你不需要构建上面的查询语句,在你的代码中调用一个函数看起来将是这样:
1 | CryptoZombies.methods.createRandomZombie("Vitalik Nakamoto 🤔") |
我们将在接下来的几章详细解释这些语句,不过首先我们来把 Web3.js 环境搭建起来。
准备好了么?
取决于你的项目工作流程和你的爱好,你可以用一些常用工具把 Web3.js 添加进来:
1 | // 用 NPM |
甚至,你可以从 github 直接下载压缩后的 .js 文件 然后包含到你的项目文件中:
1 | <script language="javascript" type="text/javascript" src="web3.min.js"></script> |
因为我们不想让你花太多在项目环境搭建上,在本教程中我们将使用上面的 script 标签来将 Web3.js 引入。
实战演习
我们为你建立了一个HTML 项目空壳 —— index.html。假设在和 index.html 同个文件夹里有一份 web3.min.js
- 使用上面的
script标签代码把web3.js添加进去以备接下来使用。
1 | <!DOCTYPE html> |
第2章: Web3 提供者
太棒了。现在我们的项目中有了Web3.js, 来初始化它然后和区块链对话吧。
首先我们需要 *Web3 Provider*.
要记住,以太坊是由共享同一份数据的相同拷贝的 节点 构成的。 在 Web3.js 里设置 Web3 的 Provider(提供者) 告诉我们的代码应该和 哪个节点 交互来处理我们的读写。这就好像在传统的 Web 应用程序中为你的 API 调用设置远程 Web 服务器的网址。
你可以运行你自己的以太坊节点来作为 Provider。 不过,有一个第三方的服务,可以让你的生活变得轻松点,让你不必为了给你的用户提供DApp而维护一个以太坊节点— *Infura*.
Infura
Infura 是一个服务,它维护了很多以太坊节点并提供了一个缓存层来实现高速读取。你可以用他们的 API 来免费访问这个服务。 用 Infura 作为节点提供者,你可以不用自己运营节点就能很可靠地向以太坊发送、接收信息。
你可以通过这样把 Infura 作为你的 Web3 节点提供者:
1 | var web3 = new Web3(new Web3.providers.WebsocketProvider("wss://mainnet.infura.io/ws")); |
不过,因为我们的 DApp 将被很多人使用,这些用户不单会从区块链读取信息,还会向区块链 写 入信息,我们需要用一个方法让用户可以用他们的私钥给事务签名。
注意: 以太坊 (以及通常意义上的 blockchains )使用一个公钥/私钥对来对给事务做数字签名。把它想成一个数字签名的异常安全的密码。这样当我修改区块链上的数据的时候,我可以用我的公钥来 证明 我就是签名的那个。但是因为没人知道我的私钥,所以没人能伪造我的事务。
加密学非常复杂,所以除非你是个专家并且的确知道自己在做什么,你最好不要在你应用的前端中管理你用户的私钥。
不过幸运的是,你并不需要,已经有可以帮你处理这件事的服务了: *Metamask*.
Metamask
Metamask 是 Chrome 和 Firefox 的浏览器扩展, 它能让用户安全地维护他们的以太坊账户和私钥, 并用他们的账户和使用 Web3.js 的网站互动(如果你还没用过它,你肯定会想去安装的——这样你的浏览器就能使用 Web3.js 了,然后你就可以和任何与以太坊区块链通信的网站交互了)
作为开发者,如果你想让用户从他们的浏览器里通过网站和你的DApp交互(就像我们在 CryptoZombies 游戏里一样),你肯定会想要兼容 Metamask 的。
注意: Metamask 默认使用 Infura 的服务器做为 web3 提供者。 就像我们上面做的那样。不过它还为用户提供了选择他们自己 Web3 提供者的选项。所以使用 Metamask 的 web3 提供者,你就给了用户选择权,而自己无需操心这一块。
使用 Metamask 的 web3 提供者
Metamask 把它的 web3 提供者注入到浏览器的全局 JavaScript对象web3中。所以你的应用可以检查 web3 是否存在。若存在就使用 web3.currentProvider 作为它的提供者。
这里是一些 Metamask 提供的示例代码,用来检查用户是否安装了MetaMask,如果没有安装就告诉用户需要安装MetaMask来使用我们的应用。
1 | window.addEventListener('load', function() { |
你可以在你所有的应用中使用这段样板代码,好检查用户是否安装以及告诉用户安装 MetaMask。
注意: 除了MetaMask,你的用户也可能在使用其他他的私钥管理应用,比如 Mist 浏览器。不过,它们都实现了相同的模式来注入
web3变量。所以我这里描述的方法对两者是通用的。
实战演习
我们在HTML文件中的 </body> 标签前面放置了一个空的 script 标签。可以把这节课的 JavaScript 代码写在里面。
- 把上面用来检测 MetaMask 是否安装的模板代码粘贴进来。请粘贴到以
window.addEventListener开头的代码块中。
1 | <!DOCTYPE html> |
第3章: 和合约对话
现在,我们已经用 MetaMask 的 Web3 提供者初始化了 Web3.js。接下来就让它和我们的智能合约对话吧。
Web3.js 需要两个东西来和你的合约对话: 它的 地址 和它的 ***ABI***。
合约地址
在你写完了你的智能合约后,你需要编译它并把它部署到以太坊。我们将在下一课中详述部署,因为它和写代码是截然不同的过程,所以我们决定打乱顺序,先来讲 Web3.js。
在你部署智能合约以后,它将获得一个以太坊上的永久地址。如果你还记得第二课,CryptoKitties 在以太坊上的地址是 0x06012c8cf97BEaD5deAe237070F9587f8E7A266d。
你需要在部署后复制这个地址以来和你的智能合约对话。
合约 ABI
另一个 Web3.js 为了要和你的智能合约对话而需要的东西是 ***ABI***。
ABI 意为应用二进制接口(Application Binary Interface)。 基本上,它是以 JSON 格式表示合约的方法,告诉 Web3.js 如何以合同理解的方式格式化函数调用。
当你编译你的合约向以太坊部署时(我们将在第七课详述), Solidity 编译器会给你 ABI,所以除了合约地址,你还需要把这个也复制下来。
因为我们这一课不会讲述部署,所以现在我们已经帮你编译了 ABI 并放在了名为cryptozombies_abi.js,文件中,保存在一个名为 cryptoZombiesABI 的变量中。
如果我们将cryptozombies_abi.js 包含进我们的项目,我们就能通过那个变量访问 CryptoZombies ABI 。
实例化 Web3.js
一旦你有了合约的地址和 ABI,你可以像这样来实例化 Web3.js。
1 | // 实例化 myContract |
实战演习
- 在文件的
<head>标签块中,用script标签引入cryptozombies_abi.js,好把 ABI 的定义引入项目。 - 在
<body>里的<script>开头 , 定义一个var,取名cryptoZombies, 不过不要对其赋值,稍后我们将用这个这个变量来存储我们实例化合约。 - 接下来,创建一个名为
startApp()的function。 接下来两步来完成这个方法。 startApp()里应该做的第一件事是定义一个名为cryptoZombiesAddress的变量并赋值为"你的合约地址"(这是你的合约在以太坊主网上的地址)。- 最后,来实例化我们的合约。模仿我们上面的代码,将
cryptoZombies赋值为newweb3js.eth.Contract(使用我们上面代码中通过script引入的cryptoZombiesABI和cryptoZombiesAddress)。
1 | <!DOCTYPE html> |
第4章: 调用和合约函数
我们的合约配置好了!现在来用 Web3.js 和它对话。
Web3.js 有两个方法来调用我们合约的函数: call and send.
Call
call 用来调用 view 和 pure 函数。它只运行在本地节点,不会在区块链上创建事务。
复习:
view和pure函数是只读的并不会改变区块链的状态。它们也不会消耗任何gas。用户也不会被要求用MetaMask对事务签名。
使用 Web3.js,你可以如下 call 一个名为myMethod的方法并传入一个 123 作为参数:
1 | myContract.methods.myMethod(123).call() |
Send
send 将创建一个事务并改变区块链上的数据。你需要用 send 来调用任何非 view 或者 pure 的函数。
注意:
send一个事务将要求用户支付gas,并会要求弹出对话框请求用户使用 Metamask 对事务签名。在我们使用 Metamask 作为我们的 web3 提供者的时候,所有这一切都会在我们调用send()的时候自动发生。而我们自己无需在代码中操心这一切,挺爽的吧。
使用 Web3.js, 你可以像这样 send 一个事务调用myMethod 并传入 123 作为参数:
1 | myContract.methods.myMethod(123).send() |
语法几乎 call()一模一样。
获取僵尸数据
来看一个使用 call 读取我们合约数据的真实例子
回忆一下,我们定义我们的僵尸数组为 公开(public):
1 | Zombie[] public zombies; |
在 Solidity 里,当你定义一个 public变量的时候, 它将自动定义一个公开的 “getter” 同名方法, 所以如果你像要查看 id 为 15 的僵尸,你可以像一个函数一样调用它: zombies(15).
这是如何在外面的前端界面中写一个 JavaScript 方法来传入一个僵尸 id,在我们的合同中查询那个僵尸并返回结果
注意: 本课中所有的示例代码都使用 Web3.js 的 1.0 版,此版本使用的是 Promises 而不是回调函数。你在线上看到的其他教程可能还在使用老版的 Web3.js。在1.0版中,语法改变了不少。如果你从其他教程中复制代码,先确保你们使用的是相同版本的Web3.js。
1 | function getZombieDetails(id) { |
我们来看看这里都做了什么
cryptoZombies.methods.zombies(id).call() 将和 Web3 提供者节点通信,告诉它返回从我们的合约中的 Zombie[] public zombies,id为传入参数的僵尸信息。
注意这是 异步的,就像从外部服务器中调用API。所以 Web3 在这里返回了一个 Promises. (如果你对 JavaScript的 Promises 不了解,最好先去学习一下这方面知识再继续)。
一旦那个 promise 被 resolve, (意味着我们从 Web3 提供者那里获得了响应),我们的例子代码将执行 then 语句中的代码,在控制台打出 result。
result 是一个像这样的 JavaScript 对象:
1 | { |
我们可以用一些前端逻辑代码来解析这个对象并在前端界面友好展示。
实战演习
我们已经帮你把 getZombieDetails 复制进了代码。
先为
zombieToOwner创建一个类似的函数。如果你还记得ZombieFactory.sol,我们有一个长这样的映射:1
mapping (uint => address) public zombieToOwner;
定义一个 JavaScript 方法,起名为
zombieToOwner。和上面的getZombieDetails类似, 它将接收一个id作为参数,并返回一个 Web3.jscall我们合约里的zombieToOwner。之后在下面,为
getZombiesByOwner定义一个方法。如果你还能记起ZombieHelper.sol,这个方法定义像这样:1
function getZombiesByOwner(address _owner)
我们的
getZombiesByOwner方法将接收owner作为参数,并返回一个对我们函数getZombiesByOwner的 Web3.jscall
1 | // 1. Define `zombieToOwner` here |
第5章: MetaMask 和账户
太棒了!你成功地写了一些前端代码来和你的第一个智能合约交互。
接下来我们综合一下——比如我们想让我们应用的首页显示用户的整个僵尸大军。
毫无疑问我们首先需要用 getZombiesByOwner(owner) 来查询当前用户的所有僵尸ID。
但是我们的 Solidity 合约需要 owner 作为 Solidity address。我们如何能知道应用用户的地址呢?
获得 MetaMask中的用户账户
MetaMask 允许用户在扩展中管理多个账户。
我们可以通过这样来获取 web3 变量中激活的当前账户:
1 | var userAccount = web3.eth.accounts[0] |
因为用户可以随时在 MetaMask 中切换账户,我们的应用需要监控这个变量,一旦改变就要相应更新界面。例如,若用户的首页展示它们的僵尸大军,当他们在 MetaMask 中切换了账号,我们就需要更新页面来展示新选择的账户的僵尸大军。
我们可以通过 setInterval 方法来做:
1 | var accountInterval = setInterval(function() { |
这段代码做的是,每100毫秒检查一次 userAccount 是否还等于 web3.eth.accounts[0] (比如:用户是否还激活了那个账户)。若不等,则将 当前激活用户赋值给 userAccount,然后调用一个函数来更新界面。
实战演习
我们来让应用在页面第一次加载的时候显示用户的僵尸大军,监控当前 MetaMask 中的激活账户,并在账户发生改变的时候刷新显示。
定义一个名为
userAccount的变量,不给任何初始值。在
startApp()函数的最后,复制粘贴上面样板代码中的accountInterval方法进去。将
updateInterface();替换成一个getZombiesByOwner的call函数,并传入userAccount。在
getZombiesByOwner后面链式调用then语句,并将返回的结果传入名为displayZombies的函数。 (语句像这样:.then(displayZombies);).我们还没有
displayZombies函数,将于下一章实现。
1 | // 1. declare `userAccount` here |
openzeppelin攻防挑战
1 Hello Ethernaut
这道题,主要考察的是控制台执行函数调用,通过语句contract.函数名来进行函数的调用,从而查看函数的返回值,然后进入下一个内容,层层递进,最终完成合约交互,提交最终的实例。
生成的实例是真实部署到测试网的合约
执行流程
1 | contract.info() |
合约源码:
1 | // SPDX-License-Identifier: MIT |
2 Fallback
仔细看下面的合约代码.
通过这关你需要
- 获得这个合约的所有权
- 把他的余额减到0
这可能有帮助
- 如何通过与ABI互动发送ether
- 如何在ABI之外发送ether
- 转换 wei/ether 单位 (参见
help()命令)- Fallback 方法
合约源码:
1 | // SPDX-License-Identifier: MIT |
漏洞点:
receive()函数在接收 ETH 时,若调用者有贡献记录(contributions[msg.sender] > 0),会将其设为owner。
攻击步骤:
- 调用
contribute()存入少量 ETH
1 | await contract.contribute({value: web3.utils.toWei('0.0001')}); |
- 作用:满足
contributions[msg.sender] > 0的条件。 - 关键限制:必须发送
< 0.001 ETH(因contribute()中有数值检查)。
- 直接发送 ETH 触发
receive()
1 | await contract.sendTransaction({value: web3.utils.toWei('0.0001')}); |
- 原理:
- 直接向合约地址转账(无 calldata)会触发
receive()。 - 由于攻击者已通过
contribute()存入过 ETH,满足contributions[msg.sender] > 0,此时owner被修改为攻击者地址。
- 直接向合约地址转账(无 calldata)会触发
- 调用
withdraw()提取所有 ETH
1 | await contract.withdraw(); |
- 前提:攻击者已成为
owner(通过receive()篡改成功)。 - 结果:合约余额被全部转移到攻击者地址。
修复建议
分离 ETH 接收和权限管理:
1
2
3receive() external payable {
contributions[msg.sender] += msg.value; // 仅更新贡献值
}使用明确的权限转移函数:
1
2
3function transferOwnership(address newOwner) public onlyOwner {
owner = newOwner;
}添加事件日志:
1
event OwnershipTransferred(address oldOwner, address newOwner);
3 Fallout
获得以下合约的所有权来完成这一关.
这可能有帮助
- Solidity Remix IDE
合约源码:
1 | // SPDX-License-Identifier: MIT |
8月13日
| 今日学习内容 |
|---|
| 智能合约开发 |
| Chainlink预言机的solidity进阶课程 |
| Hardhat开发框架-初学 |
智能合约开发
Dapp 架构和开发流程
Dapp:去中心化应用,运行在区块链或分布式网络上,应用的逻辑和数据是由多个参与者共同维护。
Dapp 架构
三个核心部分:
- 前端(User Interface):
- 前端是 Dapp 与用户交互的界面,通常由 HTML、CSS 和 JavaScript(如 React、Vue 等框架)构建。与传统 Web 应用不同,Dapp 前端会连接区块链来调用智能合约,呈现数据和执行交易。
- 前端还需要集成区块链钱包(如 MetaMask)来进行身份验证和签署交易,确保用户的隐私和安全。
- 智能合约(Smart Contracts):
- 智能合约是 Dapp 的核心,它定义了应用的业务逻辑,并部署在区块链上。智能合约通过执行自动化的规则来确保交易和操作的透明性与不可篡改性。
- 在以太坊平台上,智能合约通常使用 Solidity 编程语言编写,并通过 Ethereum Virtual Machine (EVM) 执行。
- 数据检索器(Indexer):
- 智能合约通常以
Event形式释放日志事件,比如释放代表 NFT 转移的Transfer事件,数据检索器会检索这些数据并将其写入到 PostgreSQL 等传统数据库中 - Dapp 在前端进行数据展示时需要检索器内的数据。一个简单的示例是某 NFT 项目需要展示用户持有的所有 NFT,但是 NFT 合约并不会提供通过输入地址参数返回该地址下的所有 NFT 的函数,此时我们可以运行数据检索器将
Transfer事件读取后写入传统数据库内,前端可以在传统数据库内检索用户持有的 NFT 数据
- 区块链和去中心化存储(Blockchain & Decentralized Storage):
- 区块链用于存储智能合约的状态数据及交易记录。去中心化存储如 IPFS(InterPlanetary File System)或 Arweave,用于存储大规模的非结构化数据(如图片、文档等),确保数据不易丢失和篡改。
- 通过使用去中心化存储,Dapp 确保所有数据在多个节点上备份,保证数据的持久性和去中心化特性。
Dapp 开发流程
需求分析与规划
在开发 Dapp 之前,首先需要进行需求分析和规划,明确应用的目标和功能。此阶段包括:
- 确定功能需求:需要定义用户可以进行的操作,比如转账、查询余额、创建投票等。
- 选择区块链平台:决定在哪个平台上构建 Dapp(如以太坊、Solana、Polygon 等),这通常取决于目标用户群、交易成本、可扩展性等因素。
- 设计用户体验(UX):定义 Dapp 的界面设计和交互流程,确保用户能够轻松使用应用并与区块链交互。
智能合约开发
智能合约是 Dapp 的核心,负责执行去中心化的业务逻辑和存储重要的数据。在这一阶段,开发者需要:
- 编写智能合约:使用 Solidity 或其他智能合约语言编写合约,确保合约的功能满足需求分析中定义的要求。
- 编写测试用例:为智能合约编写单元测试,确保合约逻辑正确、无漏洞。
- 审计和优化:对合约进行安全审计,确保合约的安全性,避免常见漏洞(如重入攻击、整数溢出等)。
检索器开发
检索器是获取链上数据的核心,负责捕获智能合约释放的事件并以合理的方式将其存入数据库的不同的表内部。在这一阶段,开发者需要:
- 确定功能需要的数据内容: 前端使用的数据大部份都直接来自检索器,所以开发者需要确定前端工程师所需要的数据
- 编写检索器程序: 目前主流的检索器框架,如 ponder 和 subgraph 都是用了 TypeScript 语言作为检索器的程序编写语言,开发者主要编写事件数据清理以及事件数据写入数据库的代码
- 部署和运维: 编写程序完成后,一般使用 Docker 部署到云服务器中,当然目前很多检索器框架也提供 SaaS 服务,同时检索器作为一个常规的数据库应用需要运维
前端开发
前端是用户与 Dapp 交互的主要界面,因此开发前端时需要:
- 选择前端框架:可以使用现代前端框架(如 React、Vue)来构建 UI。前端将通过 JavaScript 与智能合约进行交互。
- 连接钱包:通过集成 MetaMask 等 Web3 钱包,用户可以连接到 Dapp,并授权其与智能合约交互。
- 显示区块链数据:前端需要从区块链和检索器内获取数据(如账户余额、交易记录),并通过用户界面展示。
- 处理交易签名与确认:当用户发起交易时,前端需要与钱包进行交互,获取用户的签名并将交易发送到区块链。
与区块链交互
前端和智能合约通过 Viem(推荐)、Ethers.js 或 Wagmi 等现代化库进行交互。这些库提供更好的 TypeScript 支持和性能优化:
- 读取数据:前端通过智能合约的公共函数读取区块链上的状态数据(如余额、合约信息)。
- 发送交易:当用户发起交易时,前端需要通过钱包签署交易并发送到区块链,执行合约中的某个功能(如转账)。
部署与上线
一旦开发完成,Dapp 进入部署阶段。具体步骤包括:
- 部署智能合约:推荐使用 Hardhat 或 Foundry(现代化开发工具)将智能合约部署到测试网(如 Sepolia、Holesky)或主网。
- 前端部署:将前端应用部署到去中心化平台(如 IPFS)或传统的 Web 服务(Vercel)。
- 发布和维护:将 Dapp 上线,进行用户反馈收集,定期更新合约和前端,修复潜在问题。
Solidity 智能合约编程
基础语法与开发范式
版本声明
每个 Solidity 文件必须以版本声明开始:
1
pragma solidity ^0.8.0;
数据类型
基本数据类型
类型 描述 示例 默认值 bool 布尔值 true / false false uint8 8 位无符号整数 0 ~ 255 0 uint16 16 位无符号整数 0 ~ 65535 0 uint256 / uint 256 位无符号整数 0 ~ (2^256 - 1) 0 int8 8 位有符号整数 -128 - 127 0 int256 / int 256 位有符号整数 -2^255 ~ (2^255 - 1) 0 address 以太坊地址 0x…. 0 bytes1 ~ bytes32 固定长度字节数组 bytes32 data = “Hello” 0x00 bytes 动态字节数组 bytes memory data = “Hello World” “” string UTF-8 编码字符串 string name = “Alice” “” 复合数据类型
类型 语法 描述 示例 静态数组 T[k] 固定长度数组 uint[5] numbers 动态数组 T[] 可变长度数组 uint[] memory list 映射 mapping(K => V) 键值对存储 mapping(address => uint256) balances 结构体 struct 自定义数据结构 struct Person { string name; uint age; }枚举 enum 枚举类型 enum Status { Pending, Active, Inactive }函数修饰符
可见性修饰符表
修饰符 可见范围 描述 使用场景 public 内部 + 外部 任何地方都可以调用 对外提供的公共接口 external 仅外部 只能从合约外部调用 外部用户接口,gas 效率更高 internal 内部 + 继承 当前合约和子合约可调用 内部逻辑函数,需要被继承 private 仅内部 只有当前合约可调用 私有实现细节 状态修饰符表
修饰符 状态读取 状态修改 Gas 消耗 描述 pure ❌ ❌ 低 不读取也不修改状态的函数 view ✅ ❌ 低 只读取状态,不修改状态 payable ✅ ✅ 正常 可以接收以太币的函数 无修饰符 ✅ ✅ 正常 可以读取和修改状态 开发范式
状态机模式
智能合约本质上是一个状态机,通过交易改变合约状态。
事件驱动编程
使用事件(Events)记录重要的状态变化,便于前端监听和日志记录。
模块化设计
通过继承和库(Library)实现代码复用和模块化。
合约结构详解
基本结构
//是 Solidity 中的单行注释符号,例如:// SPDX-License-Identifier: MIT用于指定源代码的许可证类型。pragma关键字用于声明 Solidity 源代码所需的编译器版本,确保合约在兼容的编译器环境中正确编译。contract关键字用于定义一个智能合约,其语法格式为:contract 合约名 { ... }。- 一个智能合约的基本结构通常由以下三部分组成:状态变量、构造函数和普通函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract MyContract {
// 状态变量
uint256 public myNumber;
// 构造函数
constructor() {
myNumber = 100;
}
// 函数
function setNumber(uint256 _number) public {
myNumber = _number;
}
}状态变量(State Variables)
状态变量是指在合约中定义的、其值永久存储在区块链上的变量。它们用于记录合约的持久化数据,构成了合约的整体状态。当合约被部署后,这些变量将被写入区块链,并在合约的整个生命周期中保持可访问性和可追踪性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21contract MyContract {
/*
* 可以通过内部与外部函数更改变量
* public可以通过前端代码访问
*/
uint256 public totalSupply;
mapping(address => uint256) private balances;
address public owner;
// 常量
uint256 public constant MAX_SUPPLY = 1000000;
// 不可变量(构造函数中设置一次)
uint256 public immutable deploymentTime;
constructor() {
owner = msg.sender;
deploymentTime = block.timestamp;
totalSupply = 0;
}
}函数(Functions)
函数是 Solidity 智能合约中执行具体逻辑操作的核心组成部分。通过函数,可以实现对状态变量的读取、修改,或执行特定业务逻辑。
函数声明格式
Solidity 中函数的标准声明格式如下所示:
1
2
3
4
5
6
7
8
9function <函数名>(<参数列表>)
<可见性>
<状态可变性>
<修饰符列表>
<虚拟/重写关键字>
returns (<返回值列表>)
{
// 函数体
}各部分含义如下:
<函数名>:函数的名称;<参数列表>:传入函数的参数;<可见性修饰符>:如public、private、internal、external;<状态可变性修饰符>:如view、pure、payable;<函数修饰符>:如onlyOwner等自定义逻辑控制;virtual/override:用于支持继承与函数重写;returns:定义返回值及其类型。
函数可见性(Function Visibility)
函数可见性决定了函数在何种上下文中可以被调用
1
2
3
4
5
6
7
8
9
10contract VisibilityExample {
// 仅当前合约可访问
function privateFunc() private pure returns(uint256) { return 1; }
// 当前合约和继承合约可访问
function internalFunc() internal pure returns(uint256) { return 2; }
// 所有人可访问
function publicFunc() public pure returns(uint256) { return 3; }
// 仅外部调用
function externalFunc() external pure returns(uint256) { return 4; }
}函数状态修饰符(State Mutability Modifiers)
用于指明函数是否修改或读取合约状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23contract StateModifiers {
uint256 public count = 0;
// view: 只读函数,不修改状态
function getCount() public view returns(uint256) {
return count;
}
// pure: 纯函数,不读取也不修改状态
function add(uint256 a, uint256 b) public pure returns(uint256) {
return a + b;
}
// payable: 可接收以太币
function deposit() public payable {
// msg.value 是发送的以太币数量
}
// 默认:可修改状态
function increment() public {
count++;
}
}函数参数和返回值
Solidity 支持多参数与多返回值,以及命名返回值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 多个返回值
function getPersonInfo() public pure returns(string memory name, uint256 age) {
name = "Alice";
age = 25;
}
// 命名返回值
function calculate(uint256 a, uint256 b) public pure returns(uint256 sum, uint256 product) {
sum = a + b;
product = a * b;
// 自动返回命名变量
}
// 调用带多返回值的函数
function callExample() public pure {
(string memory name, uint256 age) = getPersonInfo();
// 或者忽略某些返回值
(, uint256 productOnly) = calculate(5, 3);
}修饰符(Function Modifiers)
修饰符允许在函数执行前插入额外逻辑,常用于权限控制与前置检查:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28contract ModifierExample {
address public owner;
bool public paused = false;
constructor() {
owner = msg.sender;
}
// 自定义修饰符
modifier onlyOwner() {
require(msg.sender == owner, "Not the owner");
_; // 继续执行被修饰的函数
}
modifier whenNotPaused() {
require(!paused, "Contract is paused");
_;
}
function togglePause() public onlyOwner {
paused = !paused;
}
// 使用多个修饰符
function criticalFunction() public onlyOwner whenNotPaused {
// 函数逻辑
}
}继承与函数重写(Inheritance and Override)
Solidity 支持单继承与多继承,子合约可重写父合约中的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// 基础合约
contract Animal {
string public name;
constructor(string memory _name) {
name = _name;
}
function speak() public virtual returns(string memory) {
return "Some sound";
}
}
// 继承合约
contract Dog is Animal {
constructor(string memory _name) Animal(_name) {}
// 重写父类函数
function speak() public pure override returns(string memory) {
return "Woof!";
}
}
// 多重继承
contract Pet is Animal {
address public owner;
constructor(string memory _name, address _owner) Animal(_name) {
owner = _owner;
}
}
contract Labrador is Dog, Pet {
constructor(string memory _name, address _owner)
Dog(_name)
Pet(_name, _owner) {}
}接口与抽象合约(Interfaces & Abstract Contracts)
接口与抽象合约用于定义规范与继承框架:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 接口定义
interface IERC20 {
function transfer(address to, uint256 amount) external returns (bool);
function balanceOf(address account) external view returns (uint256);
}
// 抽象合约
abstract contract AbstractToken {
string public name;
// 没有函数体的抽象函数,必须被子类使用 override 关键词重载实现
function totalSupply() public virtual returns (uint256);
// 有函数体实现的抽象函数,子类可以不使用 override 关键词重载直接继承已有的实现,也可以选择使用 override 关键词重载实现
function decimals() public view virtual returns (uint8) {
return 18;
}
}事件机制(Events)
事件用于在链上记录重要状态变化,并可由外部监听器(如检索器或前端应用)捕捉:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18contract EventExample {
// 定义事件
event Transfer(address indexed from, address indexed to, uint256 amount);
event Approval(address indexed owner, address indexed spender, uint256 amount);
mapping(address => uint256) public balances;
function transfer(address to, uint256 amount) public {
require(balances[msg.sender] >= amount, "Insufficient balance");
balances[msg.sender] -= amount;
balances[to] += amount;
// 触发事件
// 可以在区块链浏览器查找到当前事件记录
emit Transfer(msg.sender, to, amount);
}
}
以太坊技术基础
帐户模型
| 对比维度 | 外部拥有账户 EOA | 合约账户 Contract Account |
|---|---|---|
| 地址来源 | keccak256(pubKey)[12:] (公钥 → 地址) |
创建时由 CREATE/CREATE2 计算 |
| 控制方式 | 私钥签名(用户、钱包) | 合约代码(EVM 字节码) |
| 状态字段 | nonce、balance |
nonce、balance、codeHash、storageRoot |
| 能否发起交易 | ✅ 必须用私钥签名 | ❌ 只能由 EOA 触发或合约内部调用 |
| Gas 费用支付 | 由账户本身 ETH 余额承担 | 由调用者支付 |
| 典型场景 | 钱包地址、热冷账户 | ERC-20/721 Token、DeFi 协议、DAO |
Gas 机制
| 术语 | 含义 | 备注 |
|---|---|---|
| Gas | 执行 1 条 EVM 指令的抽象工作量单位 | 汇编级别价格表见 evm.codes |
| Gas Limit (Tx) | 发送者愿为本笔交易消耗的 Gas 上限 | 防止死循环耗尽余额 |
| Gas Used | 实际执行指令花费的 Gas 总和 | 多退少不补 |
| Base Fee | 随区块动态调整的基础费用(EIP-1559) | 全网销毁,抑制拍卖狂飙 |
| Priority Fee / Tip | 发送者给出以激励打包者的附加费 | 给矿工 / 验证者 |
| Max Fee Per Gas | maxFee = baseFee + priorityFee 上限 |
钱包通常自动估算 |
交易生命周期
- 签名构造
- 钱包收集字段:
nonce, to, value, data, gasLimit, maxFeePerGas, priorityFeePerGas, chainId - 使用私钥生成
v, r, s签名 → 序列化 RLP
- 钱包收集字段:
- 广播到 P2P 网络
- 交易进入本地 & 邻居节点的 mempool
- 节点根据
maxFeePerGas、gasLimit、nonce做基本筛查
- 打包 / 提议区块
- 验证者(PoS)或矿工(PoW 时代)挑选利润最高、合法顺序的交易
- 执行 EVM → 产生 交易收据(
status, gasUsed, logsBloom, logs[])
- 区块传播与共识
- 区块头包含新 stateRoot、receiptsRoot
- 超 2⁄3 质押者签名后在共识层定案(PoS Finality ≈ 2 Epoch ≈ 64 slot ≈ ~12 min)
- 确认数 & Finality
- 客户端/前端常以
n ≥ 12作”概率足够低”确认 - 完全终结在 PoS 下由 Finality Gadget(Casper FFG)给出
- 客户端/前端常以
Chainlink预言机的solidity进阶课程
虚函数:
允许函数在继承合约中被重写(Override)
在父合约中声明为 virtual 的函数,表示允许子合约重写该函数。
1 | // 父合约 |
注意:
存在虚函数的合约必须为抽象合约,也就是再合约开头添加abstract
如果虚函数没有函数体,那么继承了抽象父合约的子合约需要重写虚函数,或者使用抽象子合约
部署一个Token合约
基础版本
1 | // SPDX-License-Identifier: MIT |
ERC-20继承版本
1 | // SPDX-License-Identifier: MIT |
8月14日
| 今日学习内容 |
|---|
| Hardhat开发框架 |
今天主要实操会比较多,大部分时间在研究数据包为什么导入失败,为什么部署失败,主要是在解决一些疑难杂症
Hardhat开发框架
主流开发框架
| 框架 | 语言 |
|---|---|
| Hardhat | Javascript |
| Truffle | Javascript |
| Foundry | Rust |
| Brownie | Python |
需要安装的环境:node.js、vscode、git
合约部署
- 创建Hardhat项目需要先创建npm项目,首先初始化npm项目,初始化中可以设置该项目的相关信息,初始化成功后,会生成package.json文件
1 | npm init |
- 安装Hardhat包
1 | npm install hardhat --save-dev |
–save-dev:只在开发环境中使用
- 创建Hardhat项目
1 | npx hardhat |
- 下载我们需要的合约
1 | npm install @chainlink/contracts --save-dev |
- 编译contract文件夹下的合约
1 | npx hardhat compile |
- 部署合约
使用插件部署
1 | npx hardhat deploy |
使用脚本部署,创建一个js文件
1 | // import ethers |
1 | npx hardhat run scripts/deployFundMe.js --network sepolia |
网络&私钥配置
想要发送到指定测试网,需要配置
- 打开hardhat.config.js,添加network字段,填入测试网的url以及私钥
1 | require("@nomicfoundation/hardhat-toolbox"); |
注意:私钥很重要,此处一定要创建一个测试账户来进行,因为你的代码一旦部署到github上,此配置文件是可见的,那么私钥就是暴露的。不过还有一个方法,此处可以将将私钥写入创建的env文件,然后通过调用的方式来使用,因为env是不会被上传到github的
.env
引入一个dotenv包,将url和私钥写入.env文件
1 | npm install --save-dev dotenv |
更改后配置
1 | require("@nomicfoundation/hardhat-toolbox"); |
.env
1 | SEPOLIA_URL = https://eth-sepolia.g.alchemy.com/v2/Vf-WXrhQ2Fv_u9XbSC9Mc |
然后运行部署脚本,显示部署成功

env-enc
当然,这样的方式仍然存在安全问题,一旦别人拿到这个配置文件,就还是有可能得到私钥,那么其实可以考虑加密该文件内容。
导入env-enc包
1 | npm install --save-dev @chainlink/env-enc |
使用env-enc设置密码
1 | npx env-enc set-pw |
将配置文件通过加密的方式进行写入
1 | npx env-enc set |
设置完成后,可以在.env.enc看到内容
再将hardhat.config.js文件中的require(“dotenv”)内容更改
1 | require("@chainlink/env-enc").config() |
在.gitignore文件中增加.env.enc,来防止上传到github
Hardhat Verify
借助于hardhat-verify,Verify之后可以在etherscan上看到合约的代码以及可以查看和运行合约代码
安装插件
1 | npm install --save-dev @nomicfoundation/hardhat-verify |
导入包
1 | import hardhatVerify from "@nomicfoundation/hardhat-verify"; |
因为hardhat这个插件默认运行在主网,所以此处需要获取etherscan的aipkey
hardhat.config.ts您需要在文件中添加以下 Etherscan 配置
1 | export default { |
运行verify任务,传递部署网络、合约地址以及用于部署它的构造函数参数
1 | npx hardhat verify --network sepolia 合约地址 "10" |
这里还是建议使用导入,而不是直接显示apikey
1 | const ETHERSCAN_API_KEY = process.env.ETHERSCAN_API_KEY |
在js脚本中加入内容,使用verifyContract插件中的函数以编程方式验证合约
1 | await verifyContract( |
然后运行
1 | npx hardhat run scripts/deployFundMe.js --network sepolia |
8月15日
| 今日学习内容 |
|---|
| Web.js |
Web.js
项目创建
安装vue-cli
1 | npm install -g @vue/cli |
创建一个vue项目
1 | npx @vue/cli create web3-wallet |
此处我使用了Vue3
到项目路径下启动项目
1 | npm run serve |
配置安装vant-ui组件库
安装
1 | npm install vant |
-D:只在dev开发环境中安装
在vue.config.js文件中配置插件
1 | const { defineConfig } = require('@vue/cli-service') |
Web3连接到以太坊网络
- web3是以太坊官方开提供的一个连接以太坊区块链的模块,允许使用HTTP或IPC与本地或远程以太坊节点进行交互,它包含以太坊生态系统的几乎所有功能。web3模块主要连接以太坊暴露出来的RPC层。开发者利用web3连接RPC层,可以连接任何暴露了RPC接口的节点,从而与区块链交互。web3是一个集合库,支持多种开发语言使用wbe3,其中的 JavaScript API 叫做web3.js、另外还有web3.py、web3j,web3.js将是我们钱包开发项目的重点
| 包 | 功能 |
|---|---|
| web3.eth | 用于与以太坊区块链和智能合约之间的交互 |
| web3.utils | 包含一些辅助方法 |
| web3.shh | 用于协议进行通信的P2P和广播 |
| web3.bzz | 用于与群网络交互的Bzz模块 |
- 实例化web3对象
安装web3
1 | npm install web3 |
web3要与以坊节点进行交互,需要创建一个web3对象
1 | var Web3 = require('web3'); |
根据APl可知需要指定节点地址,我们将ws://some.local-or-remote.node:8546换成其它连接到以太坊网络的节点的地址,以此来确定连接的以太坊的网络。那么连接到以太坊网络的节点的地址是多少呢?这里我们需要使用到
alchemy
- 获取连接到以太坊网络的节点地址
alchemy提供公开的Ethereum主网和测试网络节点,到alchemy.com网站注册后即可获取各个网络的地址。请按照如下步骤获取地址。
第一步:打开alchemy网站地址:https://dashboard.alchemy.com/,使用邮箱注册后登陆
第二步:点击上图标记的“create new project”按钮创建一个新项目。然后弹出如下弹框,在输入框输入项目名,
如”MyEtherWallet“,然后点击“create project”按钮创建。
第三步:找到Ethereum下的sepolia测试网下的websockets接口
- 连接到以太坊测试网络
1 | var Web3 = require("web3") |
连接到以太坊主网与sepolia测试网络一样的,只需复制主网节点的地址去实例化web3即可。由于在主网上交易需要花费gas,因此我们基于sepolia测试网络进行开发,后续开发完成后可再切换到主网
Web3.js高频API
账号创建
API
1 | web3.eth.accounts.create([entropy]); |
参数:
entropy-String(可选):它是一个可选项,是一个随机字符串,将作为解锁账号的密码。如果没有传递字符串,则使用random生成随机字符串
返回值:
Object:包含以下字段的一个帐户对象:
address- string:帐户地址
privateKey-string:帐户私钥。前端永远不应该在localstorage中以未加密的方式共享或存储!
signTransaction(tx[, callback]) - Function:签名交易的方法。
sign(data)-Function:签名二进制交易的方法。
例子:
1 | web3.eth.accounts.create('2435a#@#@±±± |
余额获取
根据地址获取以wei为单位余额
API
1 | web3.eth.getBalance(address).then((res)→{ |
例子:
1 | //获取余额 |
在 Vue 3 的 Composition API 中,
ref是一个函数,用于创建一个响应式引用(reactive reference),通常用于包装基本类型(如字符串、数字等),使其具有响应式能力。
ref的作用:
- 创建响应式数据:
ref会将传入的值包装在一个响应式对象中- 自动追踪依赖:当在模板或计算属性中使用时,Vue 会自动追踪它的变化
- 触发视图更新:当
ref的值改变时,Vue 会自动更新相关的 DOM代码解析:
- 创建了一个响应式变量
address,初始值是'0x6191a878F0CB11E707271bce5C5e6d20dbF7xxxx'address实际上是一个Ref对象,不是直接的字符串如何使用
ref:
读取值:需要通过
.value访问实际值
修改值:也必须通过
.value修改
在模板中使用:模板中会自动解包,不需要写
.value
2
3
<div>{{ address }}</div> <!-- 自动显示 address.value -->
</template>
单位转换
- Eth 转为 wei
1 | #Web3或者实例后的web3对象都可以 |
- wei转为Eth
1 | #Web3或者实例后的web3对象都可以 |
Eth转账
API
1 | web3.eth.sendSignedTransaction(signedTransactionData[,callback]参数 |
参数
signedTransactionData-String:以HEX格式签名的交易数据。交易数据对象可以包含如下字段:
from- (String|Number):发送帐户的地址。如果未指定,则使用web3.eth.defaultAccount属性。或web3.eth.accounts.wallet中本地钱包的地址。to-(String):(可选)消息的目标地址,若未定义则为合同发送消息。value- (Number|String|BN|BigNumber):(可选)为wei中的交易转移的数量,如果是合约发送消息,则
是捐赠给合约地址。gas-(Number):(可选,默认:待定)用于交易的gas(未使用的gas会退还)。gasPrice-(Number|String|BN|BigNumber):(可选)此交易的gas价格,以wei为单位,默认为web3.eth.gasPricedata-(String):(可选)包含合同上函数调用数据的ABl字节字符串。nonce-(Number):(可选)随机数的整数。
callback-(Function):(可选)可选回调,将错误对象作为第一个参数返回,结果作为第二个参数返回。
返回
PromiEvent:promise组合的事件,将在交易完成时调用。包含以下事件
"transactionHash"返回String:在发送事务并且事务哈希可用之后立即触发。"receipt"返回Object:在交易确认时触发。“confirmation"返回Number,Object:每次确认都会被调用,直到第12次确认。接收确认编号作为第一个参数,将数据作为第二个参数。"error”返回Error:如果在发送过程中发生错误,则会触发。
1.构建转账参数
区块链转账和支付宝转账类似,需要发送方、接收方、金额、密码
另外需要添加部分区块链参数:矿工费gas、地址转账交易次数
await需要在async函数中才能使用
1 | //获取账户交易次数 |
通过转账参数计算最终gas费用,并将通过私钥将转账参数进行编码加密
ethereumjs-tx 第三方库请选择1.3.7版本
1 | import Tx from "ethereumjs-tx"; |
这段代码是使用
ethereumjs-tx(一个 Ethereum 交易签名的 JavaScript 库)来离线构建、签名并序列化以太坊交易的过程。它通常用于在浏览器或 Node.js 环境下,通过私钥对交易进行签名,而无需依赖 MetaMask 或其他 Web3 钱包。
代码逐行解析
1. 导入
ethereumjs-tx
ethereumjs-tx是一个用于处理以太坊交易的库,可以:
- 构建原始交易数据
- 用私钥签名交易
- 生成符合以太坊协议要求的 RLP 编码交易数据
2. 处理私钥
- **
privatekey.slice(2)**:
以太坊私钥通常以0x开头(如0xabc123...),slice(2)去掉0x,只保留 hex 部分。- **
new Buffer(..., "hex")**:
将私钥的 16 进制字符串转换成Buffer(二进制数据),因为ethereumjs-tx要求私钥必须是Buffer类型。
3. 预估 Gas 费用
2
rawTx.gas = gas;
- **
web3.eth.estimateGas(rawTx)**:
调用 Web3 的estimateGas方法,估算该交易需要消耗的 Gas(燃料费)。- **
rawTx.gas = gas**:
将估算的 Gas 值赋给交易的gas字段,避免 Gas 不足导致交易失败。
4. 创建交易对象并签名
2
tx.sign(privateKey);
- **
new Tx(rawTx)**:
用rawTx(原始交易数据)初始化一个ethereumjs-tx交易对象。tx.sign(privateKey):
用privateKey(Buffer 格式的私钥)对交易进行数字签名,确保只有私钥持有者能发起这笔交易。
rawTx的典型结构
2
3
4
5
6
7
8
nonce: "0x00", // 交易序号(防止重放攻击)
gasPrice: "0x09184e72a000", // Gas 单价(wei)
gasLimit: "0x2710", // Gas 上限
to: "0xRecipientAddress", // 接收方地址
value: "0x00", // 转账金额(wei)
data: "0x7f7465737432000000000000000000000000000000000000000000000000000000600057", // 合约调用数据(可选)
};
5. 序列化交易
tx.serialize():
将签名后的交易数据编码成 RLP(Recursive Length Prefix)格式,这是以太坊网络要求的二进制格式。serializedTx的结果是Buffer类型,可以用于:
- 通过
web3.eth.sendSignedTransaction()广播到以太坊网络- 存储或传输签名后的交易数据
完整流程总结
- 准备私钥 → 去掉
0x,转成Buffer。- 估算 Gas → 确保交易有足够的燃料费。
- 创建交易对象 → 设置
nonce、gasPrice、to、value等字段。- 签名交易 → 用私钥对交易进行 ECDSA 签名。
- 序列化交易 → 生成 RLP 编码的二进制数据,用于广播。
这里使用buffer,需要引入一个包
1 | npm i node-polyfill-webpack-plugin |
在vue.config.js中导入配置
1 | const { defineConfig } = require('@vue/cli-service') |
NodePolyfillWebpackPlugin是一个 Webpack 插件,主要用于在浏览器环境中模拟 Node.js 核心模块(如crypto、buffer、stream等),解决前端项目依赖 Node.js 原生模块时的兼容性问题。
为什么需要这个插件?
浏览器无法直接使用 Node.js 模块
- 像
crypto、path、stream、buffer等模块是 Node.js 内置的,浏览器默认不支持。- 但某些库(如
web3.js、ethers.js、ipfs)可能间接依赖这些模块。Web3/区块链开发常见问题
例如,
web3.js可能依赖crypto进行哈希计算,或buffer处理二进制数据。直接运行会报错:
text
NodePolyfillWebpackPlugin 的作用
✅ 自动注入 Node.js 核心模块的浏览器兼容实现
- 将
crypto、buffer、stream等模块替换为浏览器可用的 polyfill(如crypto-browserify)。- 无需手动配置每个模块。
通过sendsignedTransaction api发送转账交易,并且获取交易id
1 | web3.eth.sendSignedTransaction("0x" + serializedTx.toString("hex")).on("transactionHash",(txid) => { |
8月16日
留点时间就回顾一下行业赛道
今天产生了问题,为什么会有稳定币,既然稳定币是和法币一比一对等的,为什么需要稳定币?
ai给我的解答
1. 解决加密货币的波动性问题
- 问题:比特币、以太坊等主流加密货币价格波动剧烈,不适合作为:
- 日常支付工具(商家不愿接受一天内可能贬值10%的货币)。
- 价值存储媒介(用户担心资产缩水)。
- 稳定币的解决方案:
通过锚定法币(如USDT、USDC)或算法调控(如DAI),提供价格稳定的加密资产,同时保留区块链的便捷性。
2. 加密货币市场的“避风港”
- 交易媒介:
在交易所中,稳定币是主要的交易对(如BTC/USDT)。用户可以在市场暴跌时将资产转换为稳定币避险,避免换成法币的复杂流程(提现、手续费、监管限制)。- 套利和做市:
交易者利用稳定币快速切换仓位,无需依赖传统银行系统。
3. 跨境支付与金融包容性
- 传统跨境支付的问题:
银行转账慢(1-3天)、手续费高(尤其是小额汇款)、依赖SWIFT系统。- 稳定币的优势:
- 几分钟内完成跨境转账,手续费极低。
- 为无银行账户的人群提供金融服务(如通过USDT进行国际汇款)。
总结一下就是
- 稳定性:在波动剧烈的加密市场中提供“安全资产”
- 效率:实现快速、低成本的全球支付
- 兼容性:成为连接传统金融与加密世界的桥梁
DeFi
去中心化金融,提供不依赖传统银行或金融中介的服务
DEX:中心化交易所
Uniswap
去中心化交易所(DEX)的代表,核心创新在于引入“自动做市商”(AMM)模式,通过“恒定乘积公式” 实现代币定价。用户通过存入流动性池(如 ETH 和 DAI)成为流动性提供者(LP),赚取交易手续费。
恒定乘积公式:x * y = k
这个公式听起来复杂,但它的核心思想其实很简单。我们可以把它想象成 Uniswap 是一个非常聪明的自动交易员,它通过一个简单的数学公式来决定价格,而不依赖人工设置或市场波动。
x 和 y 代表流动性池中的两种加密货币,比如 ETH 和 USDC。
比如一个流动性池里,假设有 10 个 ETH 和 5000 个 USDC。那么:
x = 10(ETH) y = 5000(USDC)
公式如何工作?
恒定乘积公式就是 x * y = k,其中 k 是一个常数。
10 * 5000 = 50,000(这就是 k 的值)
当你在这个池子里进行交易时,这个公式始终要保持成立。也就是说,交易后,ETH 和 USDC 的数量会发生变化,但它们相乘的结果 k 必须始终是 50,000(忽略手续费的情况下)。
举个例子:
如果你想用 1 个 ETH 兑换 USDC,流动性池中的 ETH 数量就会增多,而 USDC 的数量就会减少。
假设交易后,池中的 ETH 变成了 11 个,那么为了保持公式成立,USDC 数量需要调整到 4545.45 个(50,000 / 11 = 4545.45)。
具体兑换价格计算
:
- 交易前:10 ETH,5000 USDC
- 交易后:11 ETH,4545.45 USDC
- 你用 1 ETH 兑换到了 5000 − 4545.45 = 454.55 USDC(不考虑手续费的情况)
- 兑换价格 = 454.55 USDC / 1 ETH = 454.55 USDC per ETH(低于交易前现货价 500,体现了价格冲击)
这样,Uniswap 就能自动算出兑换的价格,而且随着池子中资产比例的变化,价格也会自动调整。
那流动性提供者(LP)是如何赚钱的
当你把资金存入流动性池时,你成为了流动性提供者(LP)。每当别人进行交易时,你提供的资金就会被用来进行兑换。LP 在每次交易中都会收取一定的 交易手续费(我们以 0.3% 为例)。这些手续费会根据你在流动性池中提供的资金比例进行分配。
去中心化交易所 vs 中心化交易所
| 特点 | 去中心化交易所 | 中心化交易所 |
|---|---|---|
| 交易不需要中介,快速方便 | 你直接用自己的钱包进行交易,不需要像中心化交易所那样注册账户、上传身份证等繁琐步骤。 | 需要通过一个平台来进行配对和交易,往往存在人工审核、系统延迟等问题,交易可能比较慢。 |
| 24/7 全天候交易 | 无论你身在何处,任何时候都能进行交易。没有交易时间的限制。 | 通常会受到全球市场交易时间、服务器维护等因素的影响。尤其是某些交易所还可能进行系统升级或停机。 |
| 大额交易更便捷 | 你不需要等待层层审批,特别是对于一些大额资金的交易,完全依赖智能合约和流动性池来完成。所有交易都直接在链上进行,快速而高效。 | 大额资金的交易通常需要通过银行、金融机构等审批环节,可能还要经过反洗钱审查等复杂的程序,时间较长。 |
Compound:去中心化借贷协议
Compound 是一个去中心化的借贷平台,允许用户借入或借出加密资产。用户在平台上存入资产并获得相应的 cToken,这是一种代表用户在协议中存入资金的代币。用户可以通过这个代币赚取利息,同时也可以借入其他资产,但需要提供超额担保。
MakerDAO(现已更名为 Sky):稳定币系统
MakerDAO 是一个去中心化的借贷协议,它允许用户通过超额抵押资产来生成 DAI,一种与美元挂钩的稳定币
NFT
基本理解 所以不需要复习
DAO:去中心化自治组织
不依赖传统的公司架构,而是通过智能合约和社区投票来做决策
Nouns DAO:社区驱动的 NFT 艺术 DAO
Nouns DAO 就像是艺术和区块链的结合体,每天都会生成一个独一无二的 NFT —— 一个卡通小人头像。
LXDAO:支持 Web3 公共物品的建设者
LXDAO 是一个特别专注于 Web3 公共物品的项目。Web3 是一种更自由、更去中心化的互联网形态。LXDAO 通过支持开源项目、资助创新项目,推动这一理念的实际落地。
它的运作方式有点像是一个“工会”加“奖励平台”。
ConstitutionDAO:一场疯狂的拍卖
拍卖
8月19日
转账web3js功能
1 | <script setup> |
8月20日
账户系统
简介
密码
密码的使用场景:
- 作为转账的支付密码
- 用keystore导入钱包的时候需要输入
私钥
私钥由64位长度的十六进制的字符组成,比
如:0×A4356E49C88C8B7AB370AF7D5C0C54F0261AAA006F6BDE09CD4745CF54E0115A,一个账户只有一个私钥且不能修改。
通常一个钱包中私钥和公钥是成对出现的,有了私钥,我们就可以通过一定的算法生成公钥,再通过公钥经过一定
的算法生成地址,这一过程都是不可逆的。私钥一定要妥善保管,若被泄漏别人可以通过私钥解锁账号转出你的该
账号的数字货币。
公钥
公钥(PublicKey)是和私钥成对出现的,和私钥一起组成一个密钥对,保存在钱包中。公钥由私钥生成,但是无法通过公钥倒推得到私钥。公钥能够通过一系列算法运算得到钱包的地址,因此可以作为拥有这个钱包地址的凭证。
Keystore
Keystore常见于以太坊钱包,它是将私钥以加密的方式保存为一份JSON文件,这份JSON文件就是keystore,所
以它就是加密后的私钥。Keystore必须配合钱包密码才能导入并使用该账号。当黑客盗取Keystore后,在没有密码情况下,有可能通过暴力破解Keystore密码解开Keystore,所以建议使用者在设置密码时稍微复杂些,比如带上特殊字符,至少8位以上,并安全存储。
助记词 Mnemonic
私钥是64位长度的十六进制的字符,不利于记录且容易记错,所以用算法将一串随机数转化为了一串12~24个容易记住的单词,方便保存记录。注意:
- 助记词是私钥的另一种表现形式
- 助记词=私钥,这是不正确的说法,通过助记词可以获取相关联的多个私钥,但是通过其中一个私钥是不能获
取助记词的,因此助记词私钥。
BIP
要弄清楚助记词与私钥的关系,得清楚BlP协议,是 Bitcoin Improvement Proposals的缩 写,意思是Bitcoin
的改进建议,用于提出Bitcoin的新功能或改进措施。BIP协议衍生了很多的版本,主要有BIP32、BIP39、BIP44。
BIP32
BIP32是HD钱包的核心提案,通过种子来生成主私钥,然后派生海量的子私钥和地址,种子是一串很长的随机数。
BIP39
由于种子是一串很长的随机数,不利于记录,所以我们用算法将种子转化为一串12~24个的单词,方便保存记录,
这就是BIP39,它扩展了HD钱包种子的生成算法。
BIP44
BIP44是在BIP32和BIP43的基础上增加多币种,提出的层次结构非常全面,它允许处理多个币种,多个帐户,每
个帐户有数百万个地址
在BIP32路径中定义以下5个级别:
1 | m/purpse'/coin_type'/account'/change/address_index |
- purpose:在BIP43之后建议将常数设置为44’。表示根据BIP44规范使用该节点的子树
- Coin_type:币种,代表一个主节点(种子)可用于无限数量的独立加密币,如比特币,Litecoin或Namecoin。此级别为每个加密币创建一个单独的子树,避免重用已经在其它链上存在的地址。开发人员可以为他们的项目注册未使用的号码
- Account:账户,此级别为了设置独立的用户身份可以将所有币种放在一个的帐户中,从0开始按顺序递增
- Change:常量0用于外部链,常量1用于内部链,外部链用于钱包在外部用于接收和付款。内部链用于在钱包
外部不可见的地址,如返回交易变更 - Address_index:地址索引,按顺序递增的方式从索引o开始编号
BIP44的规则使得HD钱包非常强大,用户只需要保存一个种子,就能控制所有币种,所有账户的钱包,因此由BIP39生成的助记词非常重要,所以一定安全妥善保管,那么会不会被破解呢?如果一个HD钱包助记词是12个单词,一共有2048个单词可能性,那么随机的生成的助记词所有可能性大概是5e+39,因此几乎不可能被破解
HD钱包
通过BIP协议生成账号的钱包叫做HD钱包。这个HD钱包,并不是HardwareWallet硬件钱包,这里的HD是HierarchicalDeterministic的缩写,意思是分层确定性,所以HD钱包的全称为比特币分成确定性钱包。
密码、私钥、keystore与助记词的关系
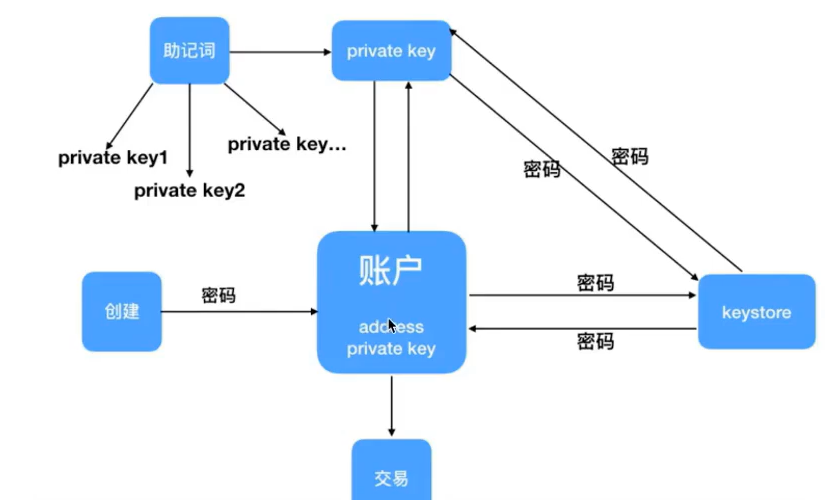
钱包的核心:私钥
基于以上的分析,我们对以太坊钱包的账号系统有了一个很好的认识,那么我们在使用钱包的过程中,该如何保管
自己的钱包呢?主要包含以下几种方式:
- 私钥(Private Key)
- keystore+密码(Keystore+Password)
- 助记词(Mnemonic code)
通过以上三种中的一种方式都可以解锁账号,然后掌控它,所以对于每种方式中的数据都必须妥善包括,如有泄漏,请尽快转移数字资产。
我们可以得到以下总结:
- 通过私钥+密码可以生成keystore,即加密私钥;
- 通过keystore+密码可以获取私钥,即解密keystore。
- 通过助记词根据不同的路径获取不同的私钥,即使用HD钱包将助记词转化成种子来生成主私钥,然后派生海
量的子私钥和地址。
可以看出这几种方式的核心其实都是为了获得私钥,然后去解锁账号,因此钱包的核心功能是私钥的创建、存储和
使用。
创建账户
web3直接创建账户
1 | web3.eth.accounts.create('2435@#@#@±++t!!678543213456764321534567543213456785432134567); |
助记词创建账户
需要使用 BIP39 协议将助记词转换成种子,再通过 ethereumjs-wallet 库生成hd钱包,根据路径的不同从hd钱包中获取不同的keypair,keypair中就包含有公钥、私钥,再通过 ethereumjs-util 库将公钥生成地址,从而根据助记词获取所有关联的账号,能获取到公钥、私钥、地址等数据信息。
HD钱包 的全称是 分层确定性钱包。它是一种利用特定算法,从一个单一的种子(Seed)生成几乎无限个密钥对(私钥和公钥)的系统。
你可以把它想象成一棵“密钥树”:
- 根种子:就像大树的根。这是最核心的机密,通常由12或24个英文单词(助记词)表示。谁拥有这个种子,谁就完全控制整棵树上的所有资产。
- 主私钥:由根种子生成的第一个、也是最重要的私钥,相当于树干。
- 子密钥:从主私钥派生出的无数个私钥和地址,相当于树枝和树叶。这些地址就是你用来接收不同加密货币(如ETH、BTC)的地址。
- 依赖库
需要用到三个库:bip39、ethereumjs-wallet/hdkey、ethereumjs-util。先安装依赖库,cd到项目跟路径运行命令npm i bip39 ethereumjs-wallet ethereumjs-util
- bip39:随机产生新的 mnemonic code,并可以将其转成 binary 的seed。
- ethereumjs-wallet:生成和管理公私钥,下面使用其中hdkey子套件来创建HD钱包。
- ethereumjs-util:Ethereum的一个工具库。
- https://iancoleman.io/bip39/
- 通过助记词创建账号
- 创建助记词
1 | //引入bip39模块 |
- 根据助记词生成密钥对keypair
1 | //导入分层钱包模块 |
8月21日
Uniswap
Uniswp是一个去中心化交易所,所谓去中心化,可以从以下两个方面理解:
- 交易全部是由开源的代码来控制,没有任何人为的因素
- 交易所无实际的掌控机构,规则不能够被随便修改
Uniswap的核心是一个数学公式
1 | x * y = k |
Uniswap允许任何人做市和交换代币。第个版本一一Uniswap V1,于2018年发布,作为概念验证。第2版是2020年发布的生产版本。
Uniswap V2允许交易者直接从一个ERC-20代币交换到另一个ERC-20代币。交易者之间不直接进行交易。相反,他们使用一个保留两个代币的代币池进行交易。这个代币池被称为“流动性池’。
Uniswap V2
Uniswap V2 是一个革命性的、完全去中心化的链上交易所协议,构建在以太坊区块链上。它于 2020 年 5 月发布,是 Uniswap V1 的重大升级,解决了 V1 的一些关键限制,并成为了整个 DeFi(去中心化金融)生态系统的基石。
你可以把它理解为一个无人管理的、由代码和数学公式运行的自动做市商(AMM)。
一、核心机制与工作原理
- 自动做市商 (AMM) 与恒定乘积公式
Uniswap V2 的核心是一个简单的数学公式:
1 | X * Y = K |
- X:流动性池中第一种资产的数量(例如 ETH)。
- Y:流动性池中第二种资产的数量(例如 DAI)。
- K:一个恒定不变的常数。
这个公式决定了交易的价格和滑点:
- 定价:资产的价格完全由池中两种资产的比例决定。例如,ETH 的价格 = (DAI 的数量) / (ETH 的数量)。
- 交易执行:当用户用 A 资产购买 B 资产时,他们向池子投入 A,取出 B。由于 K 必须保持不变,取出 B 会导致 Y 减少,因此 X 必须增加来补偿。这种变化自动决定了用户能拿到多少 B,即执行了交易。
- 滑点:交易量越大,对池子比例的改变就越大,价格滑点也越大。
- 流动性提供者 (LPs) 与手续费
- 任何人都可以成为流动性提供者:用户可以将等值的两种资产(如 ETH 和 USDC)存入交易池中,为市场提供流动性。
- 获得奖励:作为回报,LPs 会获得该交易对的**流动性代币 (LP Tokens)**。LP Tokens 代表了他们在资金池中的份额。
- 赚取手续费:所有交易都会收取 0.3% 的费用。这笔费用会直接添加到流动性池中,使得
K值缓慢增大。当 LPs 销毁他们的 LP Tokens 取出本金时,他们可以按份额获得这部分积累的手续费,从而实现被动收益。
- 价格预言机
这是 V2 相对于 V1 的一个重大创新。
- Uniswap V2 通过记录每个区块第一笔交易的资产价格(即资产累积价格),提供了一个防篡改的链上价格数据源。
- 其他 DeFi 协议(如 Compound, Aave)可以引用这个时间加权平均价格(TWAP)来获取资产价格,极大地增强了整个生态的安全性和可靠性。
二、相比 V1 的重大改进
- 支持任意ERC20交易对:
- V1 只能与 ETH 组成交易对(如 DAI/ETH, MKR/ETH)。如果你想用 DAI 换 MKR,需要经过 ETH 中转,效率低且手续费高。
- V2 允许任何两种 ERC-20 代币直接组成交易对(如 DAI/MKR),大大提高了资本效率和交易体验。
- 价格预言机:
- 如上所述,V2 引入了原生的价格预言机功能,而 V1 没有。
- 闪电贷:
- V2 原生支持闪电贷功能。允许用户无需抵押即可借出大量资产,但必须在同一笔以太坊交易内归还本金和0.09%的费用。这为套利、清算和复杂的链上策略提供了强大的金融工具。
- 协议费用(可开关):
- V2 在代码中预留了一个向 LP 收取的0.05%费用作为协议收入的功能,但这个功能在发布时是关闭的,需要通过治理来开启(事实上从未开启过)。
三、核心功能
- **代币兑换 (Swap)**:用户可以在任意两个 ERC-20 代币之间进行兑换。
- **提供流动性 (Add Liquidity)**:注入资产以赚取手续费。
- **移除流动性 (Remove Liquidity)**:销毁 LP Tokens,取回本金和赚取的手续费。
- **闪电贷 (Flash Swaps)**:无需抵押的即时贷款。
四、优缺点分析
优点:
- 完全去中心化与无需许可:任何人都可以上线新代币的交易对,无需审核。
- 高度抗审查:协议在链上运行,无法被关闭。
- 资本效率(对于长尾资产):为不热门的小币种提供了前所未有的流动性。
- 可组合性:是 DeFi 乐高的基石,可以与其他协议无缝组合。
缺点(或称“无常损失”):
- **无常损失 (Impermanent Loss)**:
- 这是提供流动性最大的风险。当池中两种资产的价格比率发生剧烈变化时(如一个暴涨),相比于单纯持有这些资产,LP 可能会遭受损失。
- 简单理解:AMM 机制会自动“高卖低买”,导致你持有的暴涨资产数量变少,暴跌资产数量变多。只有当价格比率回归到存入时的水平,损失才会消失(因此称为“无常”)。
- ** gas 费高昂**:所有操作都在链上进行,在以太坊网络拥堵时成本很高。
- 滑点:对于流动性差的池子,大额交易会有很高的滑点。
五、总结与影响
Uniswap V2 不仅仅是一个交易所,它更是一个金融基础设施。它通过极其简洁优雅的数学模型,实现了完全去中心化的交易、借贷(闪电贷)和价格发现功能,为 2020 年的 “DeFi Summer” 提供了核心动力。
尽管后来出现了更高效的 V3 版本,但 V2 因其简单性和可靠性,至今仍在许多链和场景中被广泛使用,是理解 AMM 和 DeFi 世界不可或缺的一课。
Uniswap V3
Uniswap V3 是 Uniswap 协议的第三个主要版本,于 2021 年 5 月上线。它最革命性的改进是引入了集中流动性,彻底改变了流动性提供者(LP)的资金效率。
V3 与 V2 的核心区别
| 特性 | Uniswap V2 | Uniswap V3 |
|---|---|---|
| 流动性配置 | 被动 & 分散 流动性均匀分布在整个(0, ∞)价格区间 | 主动 & 集中 LP 可以自定义价格区间来提供流动性 |
| 资金效率 | 低 | 极高(最高可达 V2 的 4000 倍) |
| 做市策略 | 单一 | 多样化(如稳定币对窄区间,波动性大的币对宽区间) |
| 费用等级 | 单一(0.3%) | 多层级(0.05%, 0.3%, 1%) |
| LP Token | 可互换的 ERC-20 代表池子的份额 | 不可互换的 NFT (ERC-721) 代表一个特定的头寸 |
| 价格预言机 | 时间加权平均价格 | 更高效、更便宜的预言机 |
V3 的核心创新:集中流动性
这是理解 V3 的钥匙。
传统 V2 的问题
在 V2 中,LP 的资本沿着 x * y = k 曲线均匀分布。这意味着只有一小部分资金在当前价格附近实际参与交易,大部分资金是闲置的,效率低下。
V3 的解决方案
V3 允许 LP 将资金集中在一个自定义的价格区间内(例如,USDC/DAI 集中在 $0.99 - $1.01)。
- 在区间内:LP 提供 100% 的流动性,赚取所有交易费用,资本效率极高。
- 在区间外:LP 的资金会 100% 转换成两种资产中价值较低的一种,停止赚取费用,直到价格重新进入区间。
举例:
一个 LP 认为 ETH 将在 $1,800 到 $2,200 之间交易。他们可以创建一个只在这个区间提供流动性的头寸。他们的资金效率将远高于一个在整个价格范围提供流动性的 V2 LP。
其他关键特性
- 多级费率
为了适应不同波动性的交易对,V3 引入了三个独立的费用等级:
- **0.05%**:针对极度稳定的资产对(如 USDC/DAI)
- **0.30%**:针对标准波动性资产对(如 ETH/USDC)(与 V2 相同)
- **1.00%**:针对高度波动性或长尾资产对
这允许 LP 根据其承担的风险获得相应的补偿。
- 活跃的流动性管理
由于价格会波动,LP 的头寸可能会移出活跃区间。这要求 LP 更积极地管理他们的头寸(手动调整或使用专门的“再平衡”服务),以最大化费用收益并避免无常损失。
- 高级预言机
V3 引入了一种更 gas 高效的方式,让开发者能够存储任何时间间隔的价格历史数据,降低了集成链上价格数据的成本。
对参与者的影响
- 对于流动性提供者 (LPs)
- 优点:潜在收益大幅增加(更高的资本效率)。
- 挑战:需要更多的主动管理和市场判断(选择价格区间)。“懒惰的”LP 策略不再有效。
- 风险:如果价格超出设定的范围,将停止赚取费用并 100% 暴露于一种资产中。
- 对于交易者
- 体验:与 V2 几乎无差别。
- 优势:由于集中流动性,滑点通常更低,特别是对于主流交易对。
- 对于开发者
- 可组合性:V3 的核心合约甚至比 V2 更具可组合性,催生了一个全新的创新生态系统(如 DeFi 机枪池、结构化产品等)。
- 基础设施:需要与新的非标准(NFT)LP 令牌进行交互。
V3 生态与工具
由于 V3 的复杂性,一个庞大的工具生态系统已经出现:
- 流动性管理平台:如 Gamma, Arrakis Finance 等,帮助 LP 自动管理他们的 V3 头寸。
- 分析平台:如 Uniswap V3 Analytics, DexGuru 等,提供高级的头寸和池子分析。
- DeFi 集成:许多协议将 V3 LP 头寸作为抵押品或其他用途。
总结
Uniswap V3 将从被动、通用的自动化做市商转变为一个主动、专业的资本效率市场。
它不再是“一劳永逸”的协议,而是为高级用户和机构级参与者提供了一个功能更强大、但也更复杂的工具。它牺牲了一些简单性,但换来了无与伦比的资本控制力和效率,巩固了 Uniswap 作为 DeFi 基础设施核心的地位。
对于新手来说,从 V2 开始理解更容易,但要深入了解现代 DeFi 的运作方式,掌握 V3 的概念是必不可少的。
8月22日
Uniswap V4
Uniswap V4 的核心是从一个“一体适用”的交易所转变为一个“可定制”的流动性基础设施。
一、核心创新:Hook(钩子)
V4 最革命性的创新是引入了 Hook(钩子)机制。你可以把它理解为一个智能合约插件系统。
- 是什么? Hook 是在资金池(Pool)生命周期(创建、初始化、 swaps、修改仓位、销毁)的特定时间点被调用的外部合约。
- 做什么? 开发者可以通过 Hook 在这些时间点注入自定义逻辑,从而创建具有前所未有功能的资金池。
类比: 如果说 Uniswap V2/V3 是一个功能固定的“功能手机”,那么 V4 就是一个“智能手机操作系统”(Singleton 合约是内核),而 Hooks 就是可以自由安装和卸载的“App”,极大地扩展了系统的功能。
Hook 的应用场景示例:
- 限价单(Limit Orders):创建一个池子,允许在特定价格范围内执行 swap,实现传统的限价单功能。
- 动态费用(Dynamic Fees):根据市场波动性自动调整交易费用(例如,波动大时费用高,波动小时费用低)。
- 时间加权做市商(TWAMM):将大额订单拆分成无数个小订单在长时间内执行,减少滑点。
- 链上预言机改进:在 swap 发生时,自动将价格数据写入链下存储,提供更便宜、更高效的价格馈送。
- 自定义收益策略:将闲置的流动性自动存入借贷协议(如 Aave)赚取额外收益。
二、另一个重大优化:Singleton(单例合约)
在 V3 及之前版本,每个交易对都需要部署一整套单独的合约,这非常消耗 Gas。
- V4 的做法:将所有资金池统一管理在一个单一的“单例”合约中。
- 好处:
- 极大降低部署和交易成本:创建新资金池的成本预计降低 99%。任何跨多个资金池的交易(例如,在多条路径间进行 swap)都将因为无需在多个合约间转移代币而节省大量 Gas。
- 高效:资产在一个合约内流转,效率更高。
三、其他关键特性
- 闪电记账(Flash Accounting):
- 与 Singleton 配合使用。在进行多池交易时,只在交易最后才进行净额结算和代币转移。
- 好处:再次大幅降低 Gas 成本。例如,一个涉及多种代币的复杂交易,最终可能只净转移 2 种代币,节省了中间所有不必要的代币转移费用。
- 原生 ETH 支持:
- V4 将原生 ETH(而不仅是 WETH)作为一等公民,使用 ETH 进行交易和提供流动性会更便宜、更简单。
四、V4 与 V3 的对比总结
| 特性 | Uniswap V3 | Uniswap V4 | 优势 |
|---|---|---|---|
| 架构 | 每个池子有独立的合约 | 单例合约 + 可插拔的 Hook 合约 | Gas 成本极低,可定制性极高 |
| 可定制性 | 固定功能(集中流动性) | 无限可能(通过 Hook) | 可以创建任何类型的衍生 AMM |
| 池子创建 | 昂贵(需部署新合约) | 非常便宜(在单例中注册即可) | 鼓励创新和长尾资产池 |
| 多池交易 | 代币在合约间多次转移 | 闪电记账,只进行净额结算 | 复杂路由的 Gas 费大幅降低 |
| 原生 ETH | 主要使用 WETH | 原生支持 ETH | 用户体验更好,成本更低 |
五、潜在影响与展望
- 创新爆炸:Hook 机制将催生出大量新型的、专门化的 AMM 池,远远超出其简单的交换功能。DeFi 的可组合性将达到新高度。
- 降低门槛:更低的 Gas 费使得创建和交易小市值代币变得更加可行,有利于生态创新。
- 竞争格局:V4 可能不仅是一个交易所,更会成为一个“流动性操作系统”,其他协议可以基于它轻松构建产品,进一步巩固 Uniswap 的市场主导地位。
- 安全风险:Hook 由第三方开发,其安全性需要额外审计。用户需要谨慎选择他们与之交互的池子,因为恶意的 Hook 可能耗尽资金。
总结:
Uniswap V4 通过“单例”合约实现极高的效率,并通过“钩子”机制实现无限的可定制性。它不再是一个单一的产品,而是一个强大的、可编程的流动性基础设施平台。 这标志着 DeFi 协议从提供固定功能的“产品”向提供底层能力的“平台”演进的关键一步。它的正式发布将是整个加密货币领域的一个里程碑事件。
8月23日
1. ERC-20 – 可替代代币标准
- 核心功能:同质化代币 的标准接口。就像现实世界中的货币,每个代币之间完全一样,可以互相分割和替换。例如:USDT, USDC, LINK, UNI 等。
- 关键方法/事件:
totalSupply(): 总供应量balanceOf(): 查询余额transfer(): 转账transferFrom()和approve(): 授权第三方(如交易所)代表用户转账Transfer和Approval事件
- 重要性:是以太坊生态的基石,定义了代币的基本结构,使得钱包、交易所等应用能够以统一的方式处理所有 ERC-20 代币。
- 缺点:
transfer方法只是简单地转账,没有回调机制,因此如果误转到合约地址,代币很可能永久丢失。
2. ERC-721 – NFT 标准
- 核心功能:非同质化代币 的标准接口。每个代币都是独一无二的,拥有唯一的
tokenId。例如:CryptoPunks, Bored Ape Yacht Club 等数字藏品。 - 关键方法/事件:
- 继承了
balanceOf,ownerOf,transfer等基本方法。 tokenURI(): 指向一个包含该 NFT 元数据(名称、描述、图像/属性等)的 JSON 文件。
- 继承了
- 重要性:开创了数字唯一性和所有权证明的新时代,推动了数字艺术、收藏品、游戏资产等领域的发展。
3. ERC-1155 – 多代币标准
- 核心功能:在同一合约中同时管理多种代币(包括同质化和非同质化) 的标准。非常高效,特别适合游戏(管理多种道具)和批量操作。
- 关键优势:
- 高效:一次交易可以批量转账多种代币(多个 ID),节省大量 Gas 费。
- 灵活:一个 ID 可以代表一种同质化代币(供应量 > 1),也可以代表一种非同质化代币(供应量 = 1)。
- 安全:引入了安全转账规则,确保代币只能被接收方合约识别后才能完成转账,防止丢失。
- 重要性:对游戏和元宇宙项目至关重要,是功能性和效率上的重大升级。
4. ERC-165 – 接口检测标准
- 核心功能:允许合约声明它实现了哪些接口(即哪些 ERC 标准)。
- 工作原理:每个标准接口都有一个唯一的接口 ID。调用者可以查询一个合约是否支持某个特定的接口 ID,从而知道它是否兼容 ERC-20, ERC-721 等。
- 重要性:是许多其他标准(如 ERC-721, ERC-1155)的基础设施。它让智能合约能够在交互前进行“功能检测”,避免与不兼容的合约交互。
5. ERC-223 – ERC-20 改进
- 核心功能:旨在解决 ERC-20 的一个主要问题:向不兼容的合约地址误转代币导致永久丢失。
- 工作原理:在
transfer方法中加入了一个tokenFallback机制。如果接收地址是合约,ERC-223 会尝试调用该合约的tokenFallback函数。如果该合约没有这个函数,交易会回滚,从而保护用户的资产。 - 现状:虽然想法很好,但并未被广泛采用,因为需要生态(钱包、交易所等)同时支持,迁移成本过高。其思想被后来的标准(如 ERC-677, ERC-1363)所继承。
6. ERC-827 – ERC-20 扩展
- 核心功能:允许用户在转账代币的同时授权第三方执行某些操作。
- 使用场景:例如,用户在一笔交易中即可完成:1) 支付 USDT 购买某个商品,同时 2) 授权商家的合约自动调用另一个合约来完成订单确认或记录。它**扩展了 ERC-20 的
approve方法**。 - 现状:存在一定的安全风险(过度授权可能导致资产被盗),已被更先进和安全的标准(如 ERC-1363)所取代。
7. ERC-1046 – 可扩展元数据的 ERC-20
- 核心功能:为 ERC-20 代币定义了一种标准化的方式来存储和访问元数据(图标、名称、精度等)。
- 工作原理:代币合约通过一个特定的函数(如
tokenMetadataURI)返回一个指向 JSON 文件的链接。这个文件包含了代币的完整信息。 - 重要性:使得钱包和区块浏览器无需维护庞大的代币列表数据库,可以直接从链上获取代币的 Logo 和信息,极大地改善了用户体验。
8. ERC-6093 – 统一代币错误代码标准
- 核心功能:为 ERC-20 和 ERC-721 的常见错误提供了标准化的错误代码和描述。
- 工作原理:定义了诸如
"ERC20InsufficientBalance","ERC20InvalidSender"等标准错误。开发者可以在合约中直接复用这些预定义错误。 - 重要性:
- 提升可读性:让交易回滚的原因更加清晰明了。
- 便于开发:为开发工具和开发者提供了统一的错误处理参考。
- 增强安全性:减少因自定义错误信息不准确而导致的误解。
9. ERC-1363 – 可支付型代币
- 核心功能:定义了代币在转账后可以自动触发接收方合约的逻辑。它结合了 ERC-20 的转账功能和 ERC-223 的回调思想,但更安全、更完整。
- 使用场景:是订阅支付、支付网关、游戏内购等的理想选择。例如:用户支付代币购买服务,代币到账后自动触发智能合约开始提供服务,所有步骤在一笔交易中完成。
- 重要性:实现了“代币即服务”的模式,极大地扩展了代币的实用性和可编程性。
10. ERC-3643(前身 T-REX)– 合规型代币标准
- 核心功能:为发行和管理合规的安全代币 而设计的一套完整的框架。常用于现实世界资产 代币化。
- 核心特性:
- 身份验证:集成了去中心化身份验证系统,只有通过 KYC/AML 检查的白名单地址才能接收和发送代币。
- 转让限制:可以根据法律法规设置复杂的转让规则(如锁定期、投资者资质等)。
- 全面生命周期管理:提供发行、增发、销毁、强制赎回、股息分配等功能。
- 重要性:是连接传统金融和 DeFi 的关键桥梁,为股票、债券、房地产等 RWA 在区块链上的合规发行和交易提供了技术基础。
总结对比
| ERC 编号 | 核心目的 | 关键特性 | 主要应用场景 |
|---|---|---|---|
| 20 | 同质化代币 | 基础转账、授权 | 通用型代币(治理、 utility、稳定币) |
| 721 | 非同质化代币 | 唯一性、元数据 | 数字艺术、收藏品、身份证明 |
| 1155 | 多代币管理 | 批量操作、高效、灵活 | 游戏道具、多种资产集合 |
| 165 | 接口检测 | 查询合约支持的标准 | 基础设施,兼容性检查 |
| 223 | 安全转账 | 转账回调防丢失 | (未被广泛采用) |
| 827 | 授权并调用 | 一笔交易完成支付和调用 | (已被 ERC-1363 等取代) |
| 1046 | 代币元数据 | 链上元数据 URI | 改善钱包和浏览器显示 |
| 6093 | 统一错误提示 | 标准化错误代码 | 开发调试、提升用户体验 |
| 1363 | 可支付代币 | 转账后回调执行逻辑 | 订阅服务、支付网关、链游 |
| 3643 | 合规安全代币 | KYC/AML、转让限制 | RWA(股票、债券、房地产) |
8月24日
回顾一下区块链的数据结构
区块
区块链中的每一个区块,都由两个部分组成:区块头( Header )和区块体( Body )。
①区块头
区块头里包含了一个区块的基本信息,主要包括:
●父哈希值( parentHash ):记录前一个区块的哈希值。
●时间戳( timestamp ):记录区块创建的具体时间。
●随机数( nonce ):用于工作量证明( PoW )机制中的挖矿过程。
●难度目标( difficulty ):表示挖矿的难度。
●币基( coinBase ):标识矿工的账户地址。
另外,区块头里还记录了三个非常重要的根哈希值:
●状态树根( stateRoot ):表示了区块链的状态树的根哈希值,状态树记录了所有账户的状态信息,如余额、合约代码等。
●收据树根( receiptRoot ):表示收据树的根哈希值,收据树记录了交易执行的结果,如交易是否成功、交易费用等。
●交易树根( transactionRoot ):表示交易树的根哈希值,交易树包含了区块中所有交易的信息。
②区块体
区块体里存储了该区块中的所有交易数据,即所有交易哈希的列表。

交易
在以太坊中,交易代表从一个账户向另一个账户发送资产或消息的行为。当用户发起一笔交易时,以太坊客户端或钱包软件将会构造交易数据。交易数据主要包含如下字段:
●nonce:发送方账户的交易计数器,统计该账户在此区块链中的总交易次数。
●gasPrice:发送方愿意为每单位 gas 支付的价格。
●gasLimit:发送方为这次交易设置的最大 gas 消耗量。
●to:接收方的账户地址。
●value:要传输的以太币数量。
●data:智能合约相关的字节码。
●v, r, s:交易签名,由发送方的私钥生成。
交易数据构造完成后,钱包将使用用户的私钥对整个交易进行签名,并将签名结果( v, r, s )加入交易数据中,然后对整个交易数据(不包括签名)计算哈希值,交易哈希是交易数据的唯一标识符,确保了交易的唯一性和不可篡改。

例如,Alice 想要发送 1 ETH 给 Bob,Alice 的账户地址是 0x123…ABC,Bob 的账户地址是 0x456…DEF。Alice 的账户已经执行过5笔交易,所以她的下一笔交易的 nonce 为6。当前的 gas 价格是 20 Gwei,她设置的 gas limit 是21000(标准以太坊转账所需的gas费)。Alice 不调用任何合约,所以 data 字段为空。
●nonce: 6
●gasPrice: 20000000000 (20 Gwei)
●gasLimit: 21000
●to: 0x456…DEF
●value: 1000000000000000000 (1 ETH)
●data: 0x
●v, r, s: [签名数据]
Alice 的钱包会把这些交易数据进行打包和签名,然后生成交易哈希,并将这个交易广播到以太坊网络。矿工将确认这笔交易并将其加入新区块,一旦成功,1 ETH 就会从 Alice 的账户转移到 Bob 的账户。
交易收据
在以太坊中,当一笔交易完成后,会生成“交易收据”( Transaction Receipt,又叫交易回执)。交易收据记录了交易执行的基本信息,是交易被包含在区块链中的重要证据。

每个交易收据包含的信息有:
●transactionHash:交易哈希值,用于唯一标识一笔交易。
●transactionIndex:交易在所在区块中的索引位置。
●blockHash:包含该交易的区块哈希值。
●blockNumber:包含该交易的区块编号。
●from:发起交易的地址。
●to:交易的目标地址。
●cumulativeGasUsed:当前区块中累积消耗的 Gas 量。
●gasUsed:这笔交易所消耗的 Gas 量。
●contractAddress:如果交易用于创建合约,则表示合约地址;否则为 null。
●logs:交易过程中产生的事件日志。
●logsBloom:布隆过滤器,用于快速检索交易日志。
●status:交易执行的状态码,表示成功或失败。
默克尔-帕特里夏树 Merkle Patricia Tree
以太坊每天的交易量达到数百万笔,如此多的交易数据是如何存储的呢?这里采用了一种名为Merkle Patricia Tree( MPT )的数据结构,这是一种特殊类型的默克尔树( Merkle Tree )。我们先了解一下基本的默克尔树。
①默克尔树,也称为哈希树( Hash Tree ),这棵树的叶子节点是数据块的哈希值,非叶子节点是其子节点的哈希值串联后再次进行哈希计算的结果,这样可以确保数据的完整性。如图所示,节点值的计算方法为:
哈希 A=Hash (数据 A );
哈希 B=Hash (数据 B );
哈希 E=Hash (哈希 A+哈希 B );

②帕特里夏树( Patricia Trie ),也称为压缩前缀树,这棵树既可以利用字符串的公共前缀来减少查询时间,又可以通过压缩无分支的节点来节省空间。

③默克尔-帕特里夏树 ( Merkle Patricia Tree ) 结合了默克尔树( Merkle Tree )和帕特里夏树( Patricia Trie )的优点,既可以验证数据的完整性,也可以快速检索状态信息,非常适合用作以太坊中的数据存储。在每个区块里,分别有一棵默克尔-帕特里夏树来存储交易数据、收据数据、状态数据和账户数据。
小结
这一小节,我们对以太坊区块链的数据结构有了一个基本了解,可以用下面一张图来总结,它是一种高度复杂且精妙的设计,它整个系统能够安全地记录和验证交易,同时保证了网络的去中心化特性。

8月25日
今天听了知识分享会,学习了很多关于web3的求职知识,包括web3找工作的方式,以及如何进行交叉判断工作的合规性,web3因为其特殊性,对于这个找工作的安全性还是需要重视的。目前的话,我还在继续学习solidity以及dapp的开发,所以目前还暂时没有可写的简历内容。
常见的共识算法
历史证明( PoH ):PoH 旨在通过创建一个可信的时间记录来验证事件的顺序和时间,使得网络参与者可以在没有互相通信的情况下验证事件发生的先后顺序。
实用拜占庭容错算法( PBFT ):用于容忍系统内一定比例的节点存在恶意行为的情况,确保全网能够达成一致。PBFT 非常适用于私有或联盟链。
委托权益证明( DPoS ):这是一种增强版的 PoS,用户将投票权委托给少数代表,这些代表负责验证和添加新的区块到区块链。DPoS 旨在提高网络的可扩展性和交易速度。
权威证明( PoA ):在 PoA 中,交易和区块的验证是由预先选定的、受信任的节点(验证者)完成的。这些节点通常会因为身份的公开而承担责任,适用于那些需要速度和效率的网络。
纯权益证明( Pure PoS ):PPoS 消除了 PoS 中的潜在中心化问题,通过随机选择验证者来确保网络的去中心化和安全性。
空间证明( PoSpace )或容量证明( PoC ):这类算法基于网络参与者提供的存储空间大小来选择区块生产者,它的优点是对电力能源的消耗较低。
认证证明( PoAuth ):类似于 PoA,但 PoAuth 要求验证者的身份是公开的,他们通常是由社区信任的人或公司。
钱包地址的生成过程
第一步:生成种子。种子是一个随机生成的数字序列,是后续的起点。种子可以由系统生成的随机数或用户提供的熵(比如随机移动鼠标产生的数据)来产生。
第二步:生成助记词。助记词是将种子转换成的一系列方便记忆的单词。在以太坊中,有一个固定的2048个单词的单词库,首先将种子分割成多个二进制数据片段,每一个片段对应单词库中的一个单词,最终形成一串单词序列,即助记词。
第三步:生成私钥。私钥是控制钱包地址的密钥。使用上一步的种子,通过 HMAC-SHA512 算法进行计算,可以得到私钥。
第四步:生成公钥。有了私钥之后,通过椭圆曲线加密算法( ECDSA ),我们可以计算出对应的公钥。
第五步:生成地址。最后一步是生成钱包地址。首先使用 Keccak-256 哈希函数计算公钥的哈希值,然后取哈希值的最后20个字节,就是一个以太坊钱包地址。
8月26日
0G基础
1 理解 0G — 去中心化 AI 操作系统
0G 代表 Zero Gravity——零重力
0G 采用了高度模块化的设计,将运行 AI 所需的功能拆解为四个独立却可协作的网络层级:存储、计算、数据可用性和主链共识。
在这个架构中,每个模块都可以独立调用,也可以组合部署,构成完整的链上 AI 应用栈。
AI 能不能不是“平台的”,而是“公共的”?这正是“On-Chain AI” 概念的核心:它不是单纯地把模型部署到链上,而是通过链上机制,重新定义模型的所有权、执行权和验证权。
在 0G 提出的系统中,这个过程由多个模块协同完成:
模型参数可以被永久记录在 0G 的存储层中,任何人都可以获取并验证其一致性;
推理和训练任务可以运行在去中心化计算网络中,由服务节点执行、并通过零知识证明或签名机制验证结果;
输入数据与中间状态被分片、加密、签名并保存在 DA 网络中,保障过程的完整性与透明性;
所有的服务调用都通过智能合约触发、结算和审计,防止暗箱操作。
“链上 AI” 的核心目标包括:
- 重新定义 AI 模型的所有权、执行权和验证权
- 确保模型参数和推理结果的透明性
- 通过智能合约触发和审计 AI 服务
2 解析 0G 的四大技术模块
0G Chain:高性能执行引擎
将 AI 引入区块链世界,首先遇到的挑战就是性能瓶颈。像以太坊这样的传统公链,每秒只能处理十几笔交易,确认时间常常超过十秒,gas 成本也非常高。这种执行效率显然难以满足 AI 模型高频、低延迟的调用需求。
0G Chain 的目标,就是打造一个专为 AI 优化的执行主链,在吞吐量、响应速度和扩展性上做出根本性提升。
共识与执行的解耦架构
0G Chain 首先打破了传统链上“共识与执行耦合”的设计。它将交易排序(共识)和状态处理(执行)分离,使执行层可以独立扩展、并行处理。这样一来,AI 模型不再受限于节点全网同步执行的效率瓶颈,而可以通过调度机制快速响应任务,实现高并发、低延迟。
高性能 CometBFT 共识引擎
在共识机制上,0G 采用经过深度优化的 CometBFT。通过调整出块间隔、精简节点通信,0G 实现了每秒超过 5000 笔交易的处理能力,并将最终确认时间压缩至亚秒级。这一性能足以支撑模型调用、状态变更等频繁交互,为 AI 提供真正“实时”级别的链上反馈。
并发架构的演进:DAG 共识与共享质押
面向未来,0G 计划引入 DAG 共识架构,使多个共识网络可并行处理事务,从根本上提升吞吐能力。同时,通过共享质押机制,不同网络可以共享安全保障,却各自独立扩展,形成灵活、弹性的执行网络。这将使 AI 智能体的部署从单链过渡到多域协作,接近 Web2 的系统响应效率。
保持 EVM 完全兼容
尽管底层进行了重构,0G 保留了对以太坊虚拟机(EVM)的兼容性。开发者可直接使用 Solidity、Foundry 等工具,无需重写代码或迁移生态。这确保了已有开发经验和工具链的可复用性,大大降低了使用门槛。
0G Storage:链上AI的数据仓库
双通道机制
从系统层面看,0G Storage 通过两个并行的“通道”协同工作:
●数据发布通道:负责存储元数据与可用性证明,并通过 0G 的共识网络验证这些数据是否真实存在。这一层确保数据可快速检索,也让存储过程具备可验证性。
●数据存储通道:处理实际的数据存储任务。系统采用纠删码机制,将原始数据切块并冗余编码,即使约 30% 的存储节点出现故障,数据依然可以完整恢复。网络还会自动进行数据副本维护,确保长期可用性。
架构设计:日志层 + KV 层
0G Storage 采用两层结构设计。底层是日志层,用于大规模数据的持久写入,比如模型权重或训练数据。上层是 Key-Value 层,支持高频读写,用于模型缓存、嵌入向量和实时状态更新。所有写入都默认记录在日志层中,保证可验证性与数据溯源。
核心优势:快、便宜、可靠
0G Storage 的读写速度可达 2GB/s,远超 IPFS/Arweave 等主流方案,成本相比 AWS S3 可降低高达 95%。同时通过纠删码与分片机制保障容错能力,在节点下线的情况下仍可持续访问。
去中心化并激励存储节点
网络通过 PoRA(Proof of Random Access)机制,随机抽检节点数据来确保真实存储,节点提交有效证明后可获得激励。每次抽检数据最多不超过 8TB,确保普通设备也能参与,降低中心化风险。
开发者体验:SDK + CLI 支持
0G 提供 Go 与 TypeScript SDK,支持链上/链下数据交互;同时配有 CLI 工具,方便开发者通过命令行上传、查询、调试,快速集成进 AI 应用或合约逻辑中。
可插拔与模块通用性
0G Storage 是独立模块,不依赖 0G Chain 可单独部署。支持 EVM 链集成,也可与 Web2 系统对接,为不同阶段的开发者提供灵活接入方式,适合逐步迁移与试点部署。
8月27日
0G Compute:去中心化AI推理网络
0G Compute 的目标,是构建一个由全球节点组成的去中心化 AI 计算网络
与传统云服务不同,0G Compute 不收固定月费,也没有账户锁定,按用量计费、随用随付。
用户预存资金后发起请求,系统通过合约自动匹配节点、执行任务并完成结算,全程无需平台介入。
节点提供者只需注册自己的 GPU 硬件,设定价格与可用状态,便可以接收任务、执行计算,并在任务完成后立即收到报酬。
实现“无需信任”的执行
为了确保平台可以在没有中介的前提下安全运行,0G Compute 引入了一套基于智能合约的信任框架。
所有资金都通过链上托管,只有在服务完成、结果返回后才释放。请求与响应过程都由签名保障,确保记录真实且不可篡改。而结算则采用零知识证明机制(ZK-Proofs),压缩计算过程的证明,极大降低链上成本,提升验证效率。
利用 TEE 实现可信的模型微调任务
大型 AI 模型虽具通用智能,但难以胜任特定领域任务,需通过微调(fine-tuning) —— 使用专属小数据集对基础模型再次训练,使其适应特定任务。
传统微调方式依赖中心化平台或分散服务,不仅缺乏透明度与隐私保障,还常引发信任和结算问题。0G Compute Network 提供全新解决方案:通过受信任执行环境(TEE)结合链上合约机制,打造一个去信任、可验证、自动结算的 AI 微调网络。
0G 的微调服务由四个步骤组成:
节点提供者在可信虚拟机(CVM)中启动微调服务并上链发布。每台服务器启动时自动生成签名密钥对,并生成远程证明报告(RA Report),客户可据此验证节点是否在真实的 TEE 中运行。
客户通过下载并验证 RA 报告和节点的公钥,确认服务可信。随后在 0G 合约中创建账户并预存资金,采用 “即用即付”模型保障任务费用。
客户构造并签名微调请求,包含数据集哈希、模型哈希、脚本哈希及费用。节点验证请求并从 0G Storage 下载相关内容,随后在 TEE 内运行微调脚本。
任务完成后,客户从 0G Storage 下载加密模型,使用链上哈希确认完整性后调用合约的 /acknowledge 方法。此时合约触发付款,费用自动转入提供者账户。
灵活接入,支持 Web2 与 Web3
无论是链上应用,还是传统 Web 服务,0G Compute 都提供了完整的调用方式。开发者可以直接在合约中触发推理服务,也可以通过 REST API 或 SDK 进行链下调用。这种灵活性大大降低了使用门槛,让 AI 能够真正融入更多场景,而不局限于链内系统。
0G DA:模块化数据可用性层
在区块链世界,数据可用性(Data Availability, 简称 DA)
DA 确保了链上数据“真实存在、可被获取”,从而让任何人都可以验证一笔交易的合法性。
以 Rollup 为例,它们将计算过程放在链下执行,只将交易数据发布回主链。若这些数据无法被验证者访问或检索,便失去了验证交易的基础,整个系统的安全性也会受到威胁。
0G DA 就是在这个背景下提出的模块,用于为 AI、Rollup、桥接、DeFi 等复杂应用,提供高性能、去中心化、无限扩展的数据可用性支持。
0G DA 是一个高度模块化的数据可用性网络。它的核心任务是确保数据可以被存储、被验证、被检索,并且具备足够的吞吐量来应对 AI 等高频调用场景。
与传统方案相比,0G DA 具有以下几个关键特征:
支持水平扩展的共识架构
原生内置的存储系统(与 0G Storage 深度协同)
基于样本的轻量级共识机制,提升验证效率
通过共享质押机制继承以太坊的安全性
系统如何运作
在 0G 中,所有数据会首先被进行 纠删编码(erasure coding),被切分为多个数据块,然后分布式存储在 0G Storage 的各个节点上。
接下来,0G 使用 DA 节点(Data Availability Nodes) 来验证这些数据是否真实可用。这些节点是通过 可验证随机函数(VRF) 选出的,确保过程不可预测,防止节点串通。
DA 节点被分组为多个小型“quorum”,各自对部分数据块进行抽样验证。这种“采样而非全验证”的机制,极大地提升了处理效率。验证完成后,DA 节点提交可用性证明,由 0G 共识网络的验证者最终确认并上链。
值得注意的是,DA 节点并不直接参与最终共识过程,这一职责由另一组独立的验证者承担。这种分工方式提高了系统整体的可扩展性与安全性。
安全性
与其他 DA 方案不同,0G 的共识验证者通过共享质押机制,在以太坊主网上抵押 0G Token。无论在哪一条子链或子网络上发生违规行为,都会回溯到主网质押池进行惩罚。
这种机制带来了两重好处:一方面,0G 网络继承了以太坊数十亿美元级别的经济安全性;另一方面,不同网络之间也能共享安全基础,支持模块之间的独立演进和扩容。
四大核心优势
1.无限扩展性:0G 可以通过添加更多 DA 共识网络,线性扩展数据可用性能力,适配任意规模的 AI 或 L2 工作负载。
2.模块化架构:存储、共识与可用性各自独立部署,优化灵活,便于组合。
3.高吞吐设计:在 Galileo 测试网中,0G 已实现 50 Gbps 的数据处理能力,适用于 LLM 推理、Agent 网络管理等场景。
4.原生 AI 支持:专为去中心化 AI 应用设计,与 0G Chain、Storage、Compute 无缝协作,构建完整的 AI 操作系统基础设施。
应用场景
Rollup 与 L2 网络:Polygon、Optimism、Arbitrum 等可以用 0G DA 存储与广播其状态数据,降低成本、提高速度
共享排序器(Shared Sequencer):多链事务排序依赖稳定高效的数据可用性,0G DA 提供去中心化支持
跨链桥:通过验证状态数据,提升跨链通信的安全性
RaaS 服务商:像 Caldera、AltLayer 等可将 0G DA 集成为默认可用性后端
DeFi 与高频交易系统:适用于订单簿数据和链上行情更新
链上游戏:用于资产状态、玩家操作记录等海量数据的验证与读取
AI 与数据市场:为 LLM 训练、Agent 状态同步提供持续可用的数据层
8月28日
使用 Foundry 编写并部署一个最基础的 ERC20 合约 —— MyToken
Step 1:初始化 Foundry 项目
在终端中创建一个新目录并初始化:
1 | mkdir mytoken-foundry |
这将生成一个基本的 Foundry 项目结构。
Step 2:添加 OpenZeppelin 合约库
由于我们未启用 Git,需手动添加 OpenZeppelin 库:
1 | mkdir -p lib/openzeppelin-contracts |
Step 3:创建合约文件
进入 src/ 目录,新建 MyToken.sol 文件:
1 | // SPDX-License-Identifier: MIT |
通过 Foundry 工具链对合约进行本地编译、部署脚本执行,并推送到 0G Galileo 测试网。
Step 1:编译合约
确保你已处于项目根目录下,执行:
1 | forge build |
如无报错,终端会显示构建成功的提示,并在 out/ 目录生成 ABI 和字节码。
Step 2(可选):本地测试合约
你可以为合约添加单元测试(在 test/ 目录),然后执行:
1 | forge test |
🧪 本节以部署为主,测试不是必需步骤。建议后续熟悉 Foundry 后再系统学习测试相关用法。
Step 3:配置部署脚本
确保你已经创建了以下文件:
合约:src/MyToken.sol
脚本:script/DeployMyToken.s.sol
脚本内容如下:
1 | // SPDX-License-Identifier: MIT |
Step 4:配置环境变量
在项目根目录下创建 .env 文件,写入你的部署钱包私钥(需要拥有 Galileo 测试币):
1 | PRIVATE_KEY=0x你的私钥 |
⚠️ 私钥请勿泄露或上传,请仅用于测试钱包。
Step 5:部署到 0G Galileo
执行以下命令,将合约部署到 0G 测试网:
1 | forge script script/DeployMyToken.s.sol:DeployMyToken \ |
如果一切正常,终端会输出部署交易哈希、部署地址和区块确认信息。
常见参数解释:
rpc-url:指定链的 RPC 节点(这里是 Galileo 测试网)
broadcast:将部署实际广播到链上
legacy:兼容低版本 Gas 模型(当前 0G Galileo 推荐添加)